【文献阅读笔记】High-Resolution Image Synthesis with Latent Diffusion Models

标题:《High-Resolution Image Synthesis with Latent Diffusion Models》
出版源:CVPR 2022
论文领域:Image Synthesis
相关链接:[pdf] [arXiv] [github]
High-Resolution Image Synthesis with Latent Diffusion Models
- 1 Introduction
- 2 Contributions
- 3 Methods
- 4 Results
- 5 Conclusion
-
- 参考文献
1 Introduction
通过将图像形成过程分解为去噪自动编码器的连续应用,diffusion models(DMs)在图像数据上取得了最先进的合成结果。此外,他们的公式允许用于控制图像生成过程而不需要重新训练的导向机制。不过,由于这些模型通常直接在像素空间操作,优化强大的 DM 通常消耗数百个 GPU,并且由于连续评估,推论是昂贵的。为了使DM能够在有限的计算资源训练,同时保留其质量和灵活性,文中作者将其应用于强大的预训练自动编码器的潜在空间中。
2 Contributions
i. 对更高维度的数据进行了更优雅的扩展数据,因此可以(a)工作在提供更忠实和详细重建的压缩水平上,以及(b)能有效地应用于百万像素图像的高分辨率合成。
ii. 在显著降低计算复杂度的同时,能够在多个任务(无条件的图像合成、绘画、随机的超分辨率)和数据集上取得有竞争力的性能。
iii. 不需要对重建和生成能力进行微妙的加权。这确保了极其忠实的重建,并且对潜伏空间的正则化要求很低。
iv. 模型可以以卷积方式应用,并呈现出 102 4 2 1024^2 10242 px的大型一致图像。
v. 设计通用的基于cross-attention的条件机制。
3 Methods
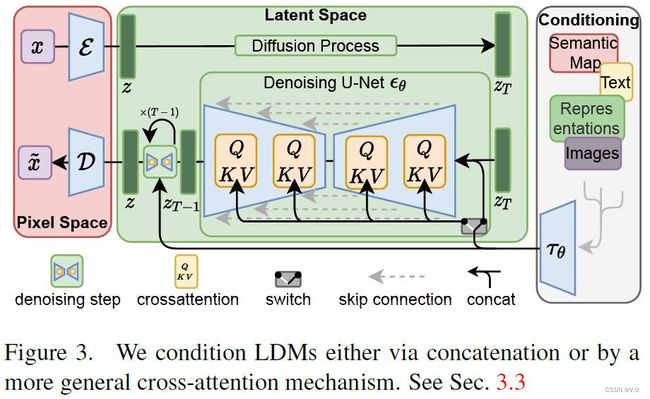
本文认为后面perceptual部分十分耗费资源,因此,LDMs设计为一个有效的生成模型+轻微的感知压缩阶段,着重优化semantic部分。模型框架如图1。
3.1 Perceptual Image Compression
LDMs利用了一个自编码模型,它学习了一个感知上等同于图像空间的空间,但显著降低了计算复杂度。
给定RGB图像 x ∈ R H × W × 3 x \in R^{H \times W \times 3} x∈RH×W×3,利用一个encoder ε \varepsilon ε将 x x x编码成一个潜在特征 z = ε ( x ) z = \varepsilon(x) z=ε(x)。其下采因子为 f = 2 m , m ∈ N f=2^m, m \in N f=2m,m∈N。解码器 D D D重构潜在特征, x ~ = D ( z ) = D ( ε ( x ) ) \widetilde{x} = D(z) = D(\varepsilon(x)) x =D(z)=D(ε(x))。
为了避免潜在的高方差空间,作者使用了两种正则化方法进行实验。一种是轻微的KL惩罚,一种是VGGAN中使用到的 V Q − r e g VQ-reg VQ−reg。
3.2 Latent Diffusion Models
和DM的区别在于将图像换成了latent。
3.3 Conditioning Mechanisms
为了将DM变成更灵活的条件性图像生成器conditional image generators,用cross-attention来增强其底层UNet backbone,这对于学习各种输入模态的基于注意的模型是有效的。文中引入 τ θ \tau_{\theta} τθ通过cross-attention层将不同模态信息 y y y映射到中间表达空间,公式如下:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d ) ⋅ V Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d}}) \cdot V Attention(Q,K,V)=softmax(dQKT)⋅V
Q = W Q ( i ) ⋅ φ i ( z t ) , K = W K ( i ) ⋅ τ θ ( y ) , V = W V ( i ) ⋅ τ θ ( y ) Q=W_Q^{(i)} \cdot \varphi_i(z_t), K=W_K^{(i)} \cdot \tau_{\theta}(y), V=W_V^{(i)} \cdot \tau_{\theta}(y) Q=WQ(i)⋅φi(zt),K=WK(i)⋅τθ(y),V=WV(i)⋅τθ(y)
4 Results
4.1 感知压缩权衡(On Perceptual Compression Tradeoffs)
文中探究了在ImageNet数据集训练过程中不同的下采样因子的表现,如图2.

基于CelebA-HQ(left)和ImageNet(right)数据集比较了不同压缩数量在推理速度和样本质量上的性能,结果如图3.

同时分析了多模态下条件潜在扩散模型BERT-tokenizer,应用 τ θ \tau_{\theta} τθ作为transformer,通过cross-attention将其映射到UNet中。文中也探究了super-resolution、inpainting下的潜在扩散(Latent Diffusion)。
5 Conclusion
文章作者提出了潜伏扩散模型(latent diffusion models),这是一种简单而有效的方法,可以显著提高去噪扩散模型的训练和采样效率而不降低其质量训练和研究的效率。基于这一点和cross-attention条件机制,在一序列不需要特定任务架构的条件图像合成任务中,文中的实验与最先进的方法相比显示了有利的结果。
参考文献
Rombach R, Blattmann A, Lorenz D, et al. High-resolution image synthesis with latent diffusion models[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 10684-10695.
【注】本文为个人文献笔记,难免存在错误,欢迎读者的指正。