2022/11/13周报
目录
摘要
一、文献阅读
1、题目和论文摘要
2、问题的提出
3、数据集制作
4、网络结构模型
5、实验结果
二、深度学习
1、决策树
2、信息增益
3、程序举例
总结
摘要
在论文阅读方面,阅读了一篇基于卷积神经网络的超声影像肝癌自动分类的论文。医生通过卷积神经网络来判断肝癌类型,以此提高准确率。在深度学习上,对决策树以及其相关理念进行了学习并简单复现了。
In terms of thesis reading,I read a paper on automatic classification of liver cancer in ultrasound images based on convolutional neural network。The doctors judge the type of liver cancer through convolution neural network, which is improves the accuracy.In depth learning,I learn the concept of decision tree and reproduce the code of the decision tree.
一、文献阅读
1、题目和论文摘要
基于卷积神经网络的超声影像肝癌自动分类
DOI:10.16476/j.pibb.2022.0101
2、问题的提出
原发性肝癌是目前世界上第 5 位常见恶性肿瘤及第 3 位肿瘤致死病因,严重威胁人们的生命和健康。原发性肝癌分为肝细胞癌(HCC)和肝内胆管癌(ICC)。为了提高医生对肝癌患者诊断的准确率,临床上通常将原发性肝癌划分成 HCC和非HCC,其中非HCC包括ICC、HCC-ICC混合型和其它罕见肿瘤。因此,从肝癌病灶中准确地筛选出HCC,对治疗肝癌患者具有重大临床意义。 在诊断过程中,对于影像的判断常常只能依靠裸眼,因此需要计算机智能辅助诊断系统提高诊断和治疗肝癌的效率。文章基于深度学习的方法,分别建立多个二维(VGG、ResNet、DenseNet)和三维(3D-CNN、Res3D、Dense3D)CNN 模型用于定量分析 B 超和 CEUS(超声造影)影像数据集,从而实现对肝癌病例中 HCC 与非 HCC 的自动分类,并对比分析各模型的性能。
3、数据集制作
B 超图像预处理流程如图所示,从每位患者的 B 超图像中挑选出一张肿瘤最清晰的图像。为了避免模型过多地提取正常组织的特征而降低其性能,只选取肿瘤感兴趣区域。某些 B 超图像上含有仪器参数等信息,利用Matlab图像处理的方式去除。将图像统一调整为112✖112尺寸大小便于模型训练。
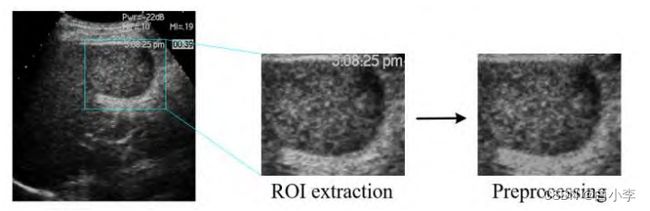 从每例非HCC患者的B超图像中再挑选出5张作为扩充后的数据,总计可获得96例非HCC数据。扩充后的非HCC和HCC样本达到同一个数量级,按 7:1:2 的比例分为训练集、验证集和测试集。
从每例非HCC患者的B超图像中再挑选出5张作为扩充后的数据,总计可获得96例非HCC数据。扩充后的非HCC和HCC样本达到同一个数量级,按 7:1:2 的比例分为训练集、验证集和测试集。
为了使 3D-CNN 模型能够学习到肿瘤区域血流从出现到消失这一变化过程的信息,将CEUS影像重新制作成视频数据,流程如下所示。对于以视频格式储存的数据,开始出现肿瘤回声时存储为第一帧图像,以1帧/2s的频率对视频进行采样,一般收集25帧;对于60秒后的图片格式数据,以1帧/30s的频率抽样,一般收集5帧,每例患者共选取 30帧图像制成视频。此外,为了避免过多正常组织干扰网络的性能,提取肿瘤感兴趣区域的图像,并统一调整尺寸为64×64 大小。
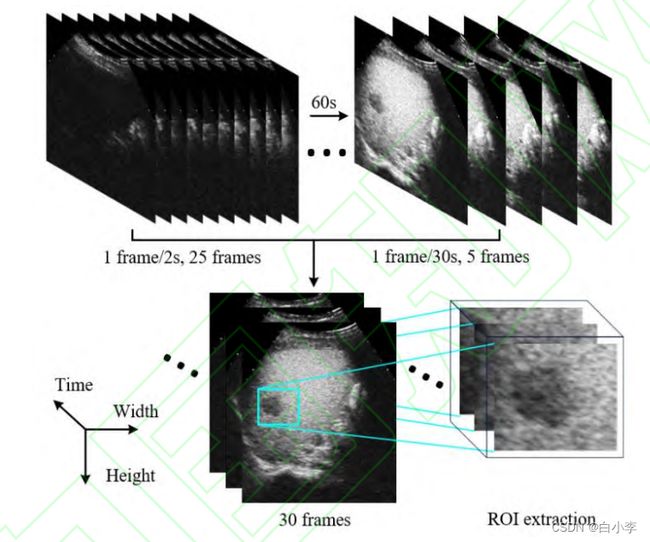
非HCC病例的CEUS视频也需要扩充,跟据每例非HCC的视频依次选取前一秒和后一秒的图像制作成新的视频,16 例非HCC的视频扩充到48例,再进行水平翻转,共得到96例非 HCC 视频。HCC和非HCC视频按相同的比例分为训练集、 验证集和测试集用于训练三维CNN模型。
4、网络结构模型
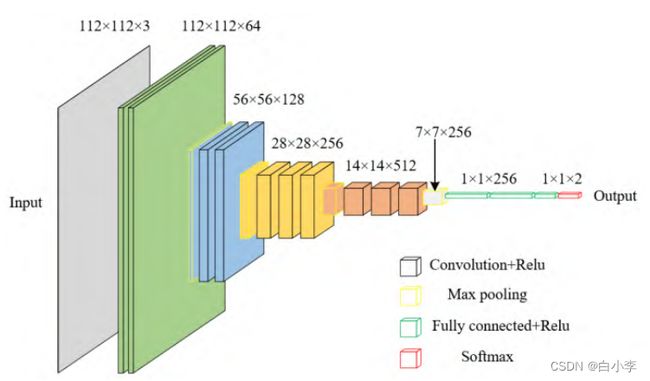
本文建立的 VGG 模型由输入层、隐藏层和输出层构成,模型框架如图所示。输入为 112 ×112 ×3 的 B 超图像。隐藏层由4组卷积层以及4个最大池化层组成,每组卷积层包含两个3×3的卷积层,最大池化层在每组卷积层之后,其步长为2,核大小为2。在池化操作后,卷积层的输出特征通道数提高到原来的两倍,输出层先通过全连接层叠加各个尺度下的特征图,再经过压平层降低全连接层的维度,最后通过Softmax激活函数对图像进行分类ResNet和DenseNet模型是在VGG基础上通过短路机制分别加入残差模块和建立前面所有层与后面层的密集连接而成。
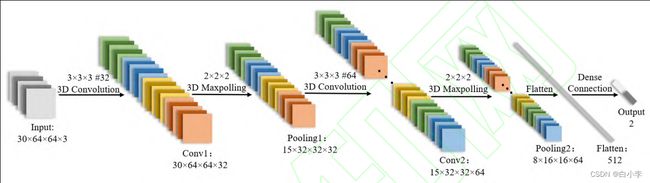
3D-CNN模型结构不仅可以提取二维空间信息,还可以通过时间维度上的卷积来捕捉图像帧与帧之间的相关性。本文建立的 3D-CNN 模型以 CEUS 视频作为输入,首先经过内核尺寸为 3 × 3 × 3 的 3D 卷积层,接着是 3 ×3 ×3 的3D最大池化层,将卷积层的输出通道数增加一倍,再重复经过卷积层和池化层,最后 将其压平,经过由全连接层和分类器组成的分类层。Res-3D、Dense-3D 与二维模型相似,仅将卷积与池化的维度从二维扩展至三维。
5、实验结果
为了客观评价系统的整体性能,采用准确率(ACC)、查准率(PPV)、灵敏度(SE)、特异度(SP)、骰子系数 (DSC)和 AUC 来评价分类结果。ACC 表示准确预测样本数占全部样本数的比率,用于测量总体分类性能,SE和 SP 分别表示正确识别 HCC 与非 HCC的比率,DSC是用于衡量二分类模型精确度,PPV 表示预测样本为 HCC中正确的比率,AUC 用来衡量 ROC 曲线下的识别任务的分类能力。

其中,TP,TN,FP,FN 分别代表真阳性,真阴性,假阳性和假阴性的数量,表示真阳性率,表示假
阳性率,是关于的函数。
由结果来看基于B超数据集的二维CNN模 型中,VGG多项指标优于其他模型。以CEUS视频作为数据集的三维模型中,3D-CNN 基础模型的各项指标均衡化更强,整体性能更佳。
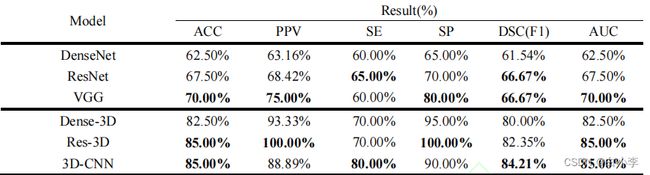
由于 HCC 和非 HCC 样本不均衡,可能影响网络的分类性能。为了验证扩充非 HCC 样本的有效性,下表中对比了 VGG 和 3D-CNN 两个模型在数据扩充前后的各项评价指标。VGG模型在原数据集上获得了更高的 ACC、PPV、SE 和 DSC,但 SP 和 AUC 两个评价指标很低,仅有 25%和 57.5%,表明各项指标均衡化较差。通过扩充非 HCC 样本的数量后,SP 和 AUC 分别提升至 80%和 70%,保持与其它参数相当的水平。与之类似,3D-CNN 模型在扩充后数据集上获得了更高的 PPV、SP 和 AUC,各项评价指标更均衡,证明了通过扩充非 HCC 样本的数量可以提升 VGG 和 3D-CNN 模型的整体分类性能。
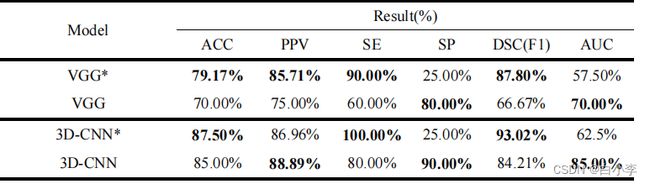
在区分肝癌 HCC 与非 HCC 的任务上,基于 B 超数据集的二维 CNN 模型准确率不高(AUC 不超过 70%),远低于基于 CEUS 数据集的三维 CNN 模型(AUC 达到 85%)。这是因为 B 超图像中仅含有肝癌病灶的二维空间特征,而 CEUS 影像可以呈现血流的时空动态变化。因此,3D-CNN 模型综合学习了病灶的二维空间和血流动态变化特征,从而更准确地区分 HCC 与非 HCC,通过扩充非 HCC 样本数量后,模型的各项评价指标均衡性更好。
二、深度学习
1、决策树
决策树是一种基本的分类与回归方法,从给定的训练数据集中,递归选择最优划分特征,依据此特征对训练数据集进行划分,直到结点符合停止条件。决策树可以看作是一个if-then系列。
决策树的停止条件
-
当前结点所有样本属于同一类别。
-
当前结点属性集为空,或者是所有样本在所有属性上取值相同。
-
当前结点无样本
构建决策树的高效方法:每个判断节点都尽可能让一半进入A分支、另一半进入B分支
决策树的构建算法有ID3(使用信息增益)和C4.5(使用信息增益比)。
2、信息增益
如果一个特征具有更好的分类能力,或者说,按照这一特征将训练数据集分割成子集,使得各个子集在当前条件下有最好的分类,那么就更应该选择这个特征。信息增益就能够很好地表示这一直观的准则。
集合信息的度量方式称为香农熵或者简称为熵(entropy)。在信息论与概率统计中,熵是表示随机变量不确定性的度量。
随机变量X的熵定义为:
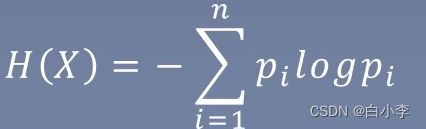
pi为xi的概率分布。熵越大,其随机变量的不确定性越大,即样本数量均匀分布。其中0<=H(P)<=logn
特征A对训练集D的信息增益g(D,A),定义为集合D的经验嫡H(D)与特征A给定条件下D的经验条件嫡H(DIA)之差,即
g(D,A) = H(D)-H(DIA)
算法流程:
输入:训练数据集D和特征A
输出:特征A对训练数据集D的信息增益g(D,A)
1)计算数据集D的经验熵H(D)

2) 计算特征A对数据集D的经验条件熵H(DIA)
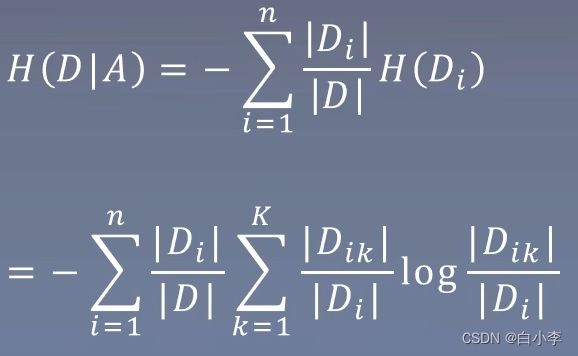
3)计算信息增益
g(D,A) = H(D)-H(DIA)
如果以信息增益为划分依据,存在偏向选择取值较多的特征,信息增益比是对这一问题进行矫正。
信息增益比:特征A对训练数据集D的信息增益比gr(D,A)定义为其信息增益g(D,A)与训练数据集D的经验嫡HD)之比:
即gr(D,A)= g(D,A)/H(D)
3、程序举例
以银行是否给用户放贷为例子。
-
年龄:0代表青年,1代表中年,2代表老年;
-
有工作:0代表否,1代表是;
-
有自己的房子:0代表否,1代表是;
-
信贷情况:0代表一般,1代表好,2代表非常好;
-
类别(是否给贷款):no代表否,yes代表是。
from math import log
"""
函数说明:计算给定数据集的经验熵
Parameters:
dataSet - 数据集
Returns:
shannonEnt - 经验熵
"""
def calcShannonEnt(dataSet):
numEntires = len(dataSet) #返回数据集的行数
labelCounts = {} #保存每个标签(Label)出现次数的字典
for featVec in dataSet: #对每组特征向量进行统计
currentLabel = featVec[-1] #提取标签(Label)信息
if currentLabel not in labelCounts.keys(): #如果标签(Label)没有放入统计次数的字典,添加进去
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1 #Label计数
shannonEnt = 0.0 #经验熵(香农熵)
for key in labelCounts: #计算香农熵
prob = float(labelCounts[key]) / numEntires #选择该标签(Label)的概率
shannonEnt -= prob * log(prob, 2) #利用公式计算
return shannonEnt #返回经验熵(香农熵)
"""
函数说明:创建测试数据集
Parameters:
无
Returns:
dataSet - 数据集
labels - 分类属性
"""
def createDataSet():
dataSet = [[0, 0, 0, 0, 'no'], #数据集
[0, 0, 0, 1, 'no'],
[0, 1, 0, 1, 'yes'],
[0, 1, 1, 0, 'yes'],
[0, 0, 0, 0, 'no'],
[1, 0, 0, 0, 'no'],
[1, 0, 0, 1, 'no'],
[1, 1, 1, 1, 'yes'],
[1, 0, 1, 2, 'yes'],
[1, 0, 1, 2, 'yes'],
[2, 0, 1, 2, 'yes'],
[2, 0, 1, 1, 'yes'],
[2, 1, 0, 1, 'yes'],
[2, 1, 0, 2, 'yes'],
[2, 0, 0, 0, 'no']]
labels = ['不放贷', '放贷'] #分类属性
return dataSet, labels #返回数据集和分类属性
"""
函数说明:按照给定特征划分数据集
Parameters:
dataSet - 待划分的数据集
axis - 划分数据集的特征
value - 需要返回的特征的值
Returns:
无
"""
def splitDataSet(dataSet, axis, value):
retDataSet = [] #创建返回的数据集列表
for featVec in dataSet: #遍历数据集
if featVec[axis] == value:
reducedFeatVec = featVec[:axis] #去掉axis特征
reducedFeatVec.extend(featVec[axis+1:]) #将符合条件的添加到返回的数据集
retDataSet.append(reducedFeatVec)
return retDataSet #返回划分后的数据集
"""
函数说明:选择最优特征
Parameters:
dataSet - 数据集
Returns:
bestFeature - 信息增益最大的(最优)特征的索引值
"""
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1 #特征数量
baseEntropy = calcShannonEnt(dataSet) #计算数据集的香农熵
bestInfoGain = 0.0 #信息增益
bestFeature = -1 #最优特征的索引值
for i in range(numFeatures): #遍历所有特征
#获取dataSet的第i个所有特征
featList = [example[i] for example in dataSet]
uniqueVals = set(featList) #创建set集合{},元素不可重复
newEntropy = 0.0 #经验条件熵
for value in uniqueVals: #计算信息增益
subDataSet = splitDataSet(dataSet, i, value) #subDataSet划分后的子集
prob = len(subDataSet) / float(len(dataSet)) #计算子集的概率
newEntropy += prob * calcShannonEnt(subDataSet) #根据公式计算经验条件熵
infoGain = baseEntropy - newEntropy #信息增益
print("第%d个特征的增益为%.3f" % (i, infoGain)) #打印每个特征的信息增益
if (infoGain > bestInfoGain): #计算信息增益
bestInfoGain = infoGain #更新信息增益,找到最大的信息增益
bestFeature = i #记录信息增益最大的特征的索引值
return bestFeature #返回信息增益最大的特征的索引值
if __name__ == '__main__':
dataSet, features = createDataSet()
print("最优特征索引值:" + str(chooseBestFeatureToSplit(dataSet)))运行结果:
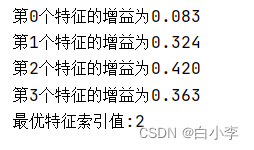
最优特征索引值为2即选择有自己的房子的信息增益作为最优特征。
总结
本周是最后一次对CNN学习,下周将进入对RNN的学习。在深度学习上依旧继续往下学习,由于有较多事耽误,本周对于工程项目的学习暂且停了一下,下周继续学习。