CNN变体学习2
文章目录
- 前言
- 文献阅读
-
- 摘要
- 介绍
- 深度学习模型
- 结果和讨论
- CNN变体
-
- GoogLeNet含并行连结的网络
- Batch Normalization批量归一化
- ResNet残差网络
- 总结
前言
This week, I continue to read the literature last week and learn that the author mainly designed two deep learning models: DeepPM model and APTR model (DeepPM model is based on GRU, APTR model is based on transformer) to deal with time series problems, and both of them performed well. At the same time, DeepPM model performs better in long-term prediction. I also study GoogLeNet, Batch Normalization and ResNet, mainly learning the model structure and model code of GoogLeNet and ResNet.
本周继续阅读上周那篇文献,了解到作者主要是设计了两种深度学习模型,DeepPM模型以及APTR模型(DeepPM模型是基于GRU的,APTR模型是基于transformer)对时间序列问题进行处理,且都表现良好,同时DeepPM模型在长期预测上表现更好。还学习GoogLeNet、Batch Normalization和ResNet,主要学习GoogLeNet和ResNet的模型结构以及模型代码。
文献阅读
上周那篇文献看的比较匆忙,还有些不理解的地方,这周继续看上周那篇文献。
题目:Optimization research on air quality numerical model forecasting effects
based on deep learning methods
作者:Wei Wang , Xingqin An ,, Qingyong Li , Yangli-ao Geng , Haomin Yu , Xinyuan Zhou
摘要
为了提高空气质量数值模型的预测有效性,本研究利用我国中部地区的PM2.5和O3检测数据以及WPF-Chem数值预报,构建并训练了两个深度学习模型DeepPM和APTR。主要是为提高空气质量数值模式的预报性提供一种新的方法和思路。
介绍
一个三位的数值模型可以代表大气中大多数主要的物理和化学过程。它可以在区域尺度上以高时空分辨率明确反应空气污染物的形成和小三,这是空气预测的主流方向,但由于一些不确定性,比如污染物排放清单、气象预测的偏倚、化学过程的复杂性,使得数值模型的预测结果与主要污染物的浓度观测值存在偏差,这就直接影响了空气质量预报的准确性。本研究提出了一种基于深度学习技术的提高数值模型预测有效性的新方法。以中南部地区的每小时PM2.5和O3浓度数据及对应网格的WPF-Chem模型预测结果作为训练数据,结合预报时间之前的观测数据,构建多源数据融合预报优化系统。
WRF-Chem模型:
结合化学的天气研究和预报模型(WRF-Chem)是由NOAA(国家海洋和大气管理局)和NCAR(国家大气研究中心)开发的完全耦合的化学传输模型。
深度学习模型
问题定义:
给定未来P个时间段的空气质量WRF-Chem模拟 {w0,w1 ,wp− 1}和真实的空气质量观测{O− h,O− 2 ,O− 1},目的是预测未来P个时间段 {O0,O1 ,Op− 1}的真实空气质量。映射关系表示如下:

输入过去空气质量观测值的时间范围设置为24 h,并预测未来144 h的空气质量;因此,h = 24 和 p = 144。
针对上述问题,将场地的历史观测数据和相应网格的WRF-Chem预测数据视为时间序列,将原始问题转化为时间序列预测问题。在深度学习中,通常用于处理时间序列数据的网络结构包括门控循环单元(GRU)和transformer。这篇文献分别基于GRU和transformer设计及了两种深度学习模型结构DeepPM和APTR。前者侧重于挖掘空气质量变化的周期性模式,而后者则对时间序列数据中的长期连接具有很强的建模能力。
DeepPM模型
GRU(Gate Recurrent Unit)是循环神经网络(Recurrent Neural Network, RNN)的一种。和LSTM(Long-Short Term Memory)一样,也是为了解决长期记忆和反向传播中的梯度等问题而提出来的。GRU和LSTM在很多情况下实际表现上相差无几,但比LSTM,使用GRU能够达到相当的效果,并且相比之下更容易进行训练,能够很大程度上提高训练效率,因此很多时候会更倾向于使用GRU。LSTM有三个门:遗忘门、记忆门、输出门,GRU有两个门:重置门和更新门。
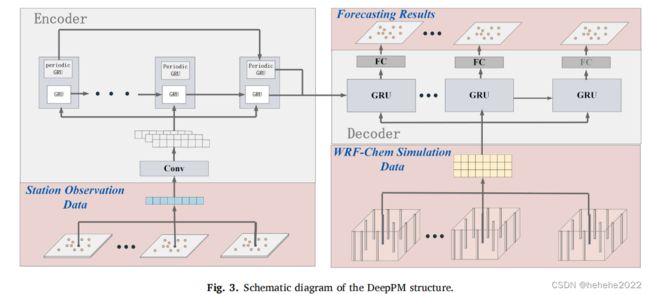
DeepPM模型的结构如上图所示,采用了基于GRU的整体编码器-解码器架构,考虑到某些气体的周期性,例如一天中固定时间的空气质量条件与气象和社会模式的可能相关性,提出了一个周期性跳跃周期单元(周期性GRU)来捕捉这种周期性趋势。解码器也采用了GRU结构,它首先接受从编码器中提取的多尺度时间序列信息,另外输入每个周期对应的WRF-Chem预测,输出相应时刻的融合特征。最终,使用完全连接的网络层来处理最终的预测结果。
APTR模型
APTR模型是基于transformer提出的一种模型,与GRU相比,transformer使用直接加权融合来处理具有时间结构的序列数据,从而轻松捕获嵌入的长期连接。模型图如下图所示:

分别提取了历史遗址观测日期和WRF-Chem数据应用1D-CNN(卷积神经网络)的整个序列的局部时序特征。随后,提取的特征分别送入transformer进行融合。由于transformer平等地处理输入序列的每个元素,并且不使用输入序列的时间信息,因此在特征中引入了表示时间戳的其他位置编码信息。随后,利用transformer中的自注意力机制对站点历史序列和WRF-Chem序列特征进行进一步处理和转换,以降低噪声并增强有用信息。值得注意的是,此步骤中的两种类型的序列特征仍然是独立处理的。然后利用交叉注意力机制计算WRF-Chem序列中每个元素与位点历史序列中每个元素相互作用的权重,并使用这些权重实现两个特征的动态融合。然后通过完全连接的网络层获得最终预测。
性能指标
使用均方根误差(RMSE)、绝对值误差(MAE)、对称平均绝对百分比误差(SMAPE)和皮尔逊相关系数(r)4个指标评估预测结果。
结果和讨论
总体评估表如下:

可以看出在未来24小时的小时预报中,APTR模型表现得更好,在未来144小时的小时预报中,DeepPM模型表现得更好。与WRF-Chem相比两者都有明显的改善。对于长期预测,DeepPM更有利。
CNN变体
GoogLeNet含并行连结的网络
它是第一次几乎快到100层的卷积神经网络,卷积个数超过100。
学了这么多的CNN变体,到底卷积选择几乘几的好,池化是最大池化还是平均池化好,有这么多的选择,到底用哪一个好,GoogLeNet中最重要的是Inception块,在这个块中抽取有不同的通道,不同通道有不同的设计。

输入分了四条路,四个输出等高宽,最后将四个通道合并在一起。
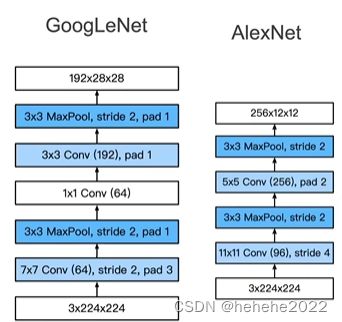
假设输入通道是192X28X28,第一条通道压到64,第二条降到96加到128,1X1的卷积是用来改变通道数的,蓝色的卷积是用来抽取信息的,最后的通道是四个加起来256个。Inception块的设计降低了参数个数及计算复杂度。

GoogLeNet分为5个stage,所谓的stage就是高宽减半,用了9个inception块,

前两个stage,做的是将通道数拉上去,将高宽减下来,用了更小的卷积层使得高宽保留的更多一些,可以支撑一些更深的网络。
stage3
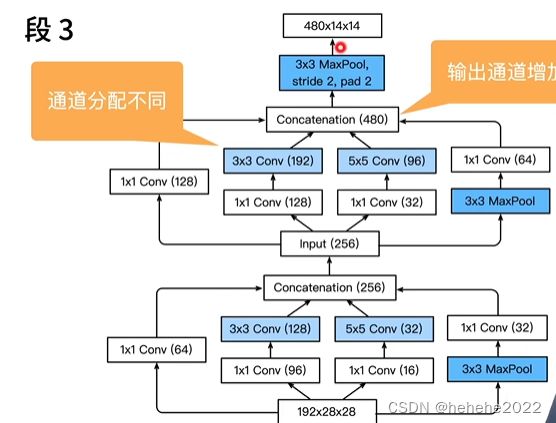
输出通道数增加,从192到480。段4、5也是增加了通道数从480到532到1024。和VGG一样,有5个stage,使用inception block,不断增加通道数最后到1024.
inception有很多后续变种,Inception-BN(v2)使用了batch normalization,inception(v3)修改了inception块,将5X5的卷积改为3X3的卷积层,替换5X5为1X7和7X1卷积层,替换3X3为1X3和3X1的卷积层,inception-v4使用了残差连接。
GoogLeNet模型代码
import torch
from torch import nn, optim
import torch.nn.functional as F
class Inception(nn.Module):
# c1 - c4为每条线路里的层的输出通道数
def __init__(self, in_c, c1, c2, c3, c4):
super(Inception, self).__init__()
# 线路1,单1 x 1卷积层
self.p1_1 = nn.Conv2d(in_c, c1, kernel_size=1)
# 线路2,1 x 1卷积层后接3 x 3卷积层
self.p2_1 = nn.Conv2d(in_c, c2[0], kernel_size=1)
self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1)
# 线路3,1 x 1卷积层后接5 x 5卷积层
self.p3_1 = nn.Conv2d(in_c, c3[0], kernel_size=1)
self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2)
# 线路4,3 x 3最大池化层后接1 x 1卷积层
self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.p4_2 = nn.Conv2d(in_c, c4, kernel_size=1)
def forward(self, x):
p1 = F.relu(self.p1_1(x))
p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))
p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))
p4 = F.relu(self.p4_2(self.p4_1(x)))
return torch.cat((p1, p2, p3, p4), dim=1) # 在通道维上连结输出
class GlobalAvgPool2d(nn.Module):
# 全局平均池化层可通过将池化窗口形状设置成输入的高和宽实现
def __init__(self):
super(GlobalAvgPool2d, self).__init__()
def forward(self, x):
return F.avg_pool2d(x, kernel_size=x.size()[2:])
class FlattenLayer(torch.nn.Module):
def __init__(self):
super(FlattenLayer, self).__init__()
def forward(self, x): # x shape: (batch, *, *, ...)
return x.view(x.shape[0], -1)
#实现每一个stage
class GoogLeNet(nn.Module):
def __init__(self, num_classes=1000):
super(GoogLeNet, self).__init__()
self.b1 = nn.Sequential(nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
self.b2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=1),
nn.Conv2d(64, 192, kernel_size=3, padding=1),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
self.b3 = nn.Sequential(Inception(192, 64, (96, 128), (16, 32), 32),
Inception(256, 128, (128, 192), (32, 96), 64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
self.b4 = nn.Sequential(Inception(480, 192, (96, 208), (16, 48), 64),
Inception(512, 160, (112, 224), (24, 64), 64),
Inception(512, 128, (128, 256), (24, 64), 64),
Inception(512, 112, (144, 288), (32, 64), 64),
Inception(528, 256, (160, 320), (32, 128), 128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
self.b5 = nn.Sequential(Inception(832, 256, (160, 320), (32, 128), 128),
Inception(832, 384, (192, 384), (48, 128), 128),
GlobalAvgPool2d())
self.output = nn.Sequential(FlattenLayer(),
nn.Dropout(p=0.4),
nn.Linear(1024, 1000))
def forward(self, x):
x = b1(x)
x = b2(x)
x = b3(x)
x = b4(x)
x = b5(x)
x = output(x)
return x
net = GoogLeNet()
X = torch.rand(1, 3, 224, 224)
# 可以对照表格看一下各层输出的尺寸
for blk in net.children():
X = blk(X)
print('output shape: ', X.shape)
输出:
output shape: torch.Size([1, 64, 56, 56])
output shape: torch.Size([1, 192, 28, 28])
output shape: torch.Size([1, 480, 14, 14])
output shape: torch.Size([1, 832, 7, 7])
output shape: torch.Size([1, 1024, 1, 1])
output shape: torch.Size([1, 1000])
Batch Normalization批量归一化
问题:
当神经网络很深的时候,从数据(下面)到损失函数(上面)的计算是forward,算backward是从上面到下面计算,问题是梯度在上面的时候会比较大,越到下面靠近数据的时候梯度会比较小,每次更新的时候上面会不断地更新,下面更新的会比较慢,底部层一变化,所有都得跟着变,顶部会重新拟合底部变化导致的问题,导致收敛变慢。我们的问题是能否在底部层学习的时候避免变化顶部层。
批量归一化的核心想法是把小批量的均值和方差固定住。

批量归一化做的是做额外的调整

γ和β是可以学出来的参数。如果它作用在全连接层和卷积层输出上时,它作用在激活函数之前,即全连接层或卷积层输出后直接接一个批量归一化层(把均值一减方差一除再加上γ和β),再做激活函数;也可以作用再全连接层和卷积层的输入上,对输入做线性变换,但两个的作用维度是不一样的;对全连接层,它作用的是特征维上(输入是一个二维的输入,每一行是样本,每一列是特征),对于卷积层,是作用在通道维上的,把所有的像素(对每个像素,它不是有多个通道么,通道数是100的话,这个像素有一个长为100维的向量,向量可以当作这个像素的特征)当作是样本,样本数是批量大小X高X宽,所以来计算它的均值和方差,所以说是作用在通道维。
批量归一化在做什么?
最初论文是想用它来减少内部协变量转移,后续有人指出它可能就是通过在每个小批量里加入噪音来控制模型的复杂度,噪音就是公式里的μB(随机偏移)和σB(随机缩放)。
ResNet残差网络
加深神经网络一定会带来好处吗?不一定,假设下图的最优值在f’处,F1是一个函数,函数的大小代表了函数的复杂程度,学到F6发现它到最优点的距离比F3还大,虽然F6的模型更加复杂,但实际上可能学偏了,可能还不如小模型学到的,这就是模型偏差。我们希望每次学的复杂模型包含小模型为子模型,那就不会效果变差。ResNet的核心思想就是层数增加不会让效果变差。

残差块
f(x) = x+g(x),g(x)为新加的东西,
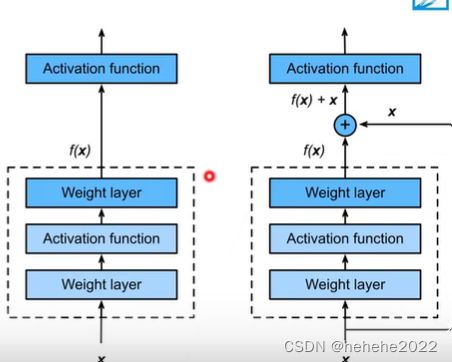
假设有两层,卷积层、激活函数、卷积层,我可以包含f(X),也可以没有f(x),走其他的线路也就是一个小模型。
残差块细节

第一种实现是正常情况下是左边那种,卷积、归一化、relu、卷积、归一化,但现在还会在batch norm上加个输入出去;第二种是会做一个1X1的卷积变化通道。
ResNet最核心的就是加了一个加法过程,它有两种ResNet block 一种是高宽减半的ResNet块,即在第一个卷积层中步幅为2,1X1的卷积将通道数增加一倍,之后接多个高宽不变的ResNet块,步幅为1,重复几次。

ResNet架构
类似于VGG和GoogleNet的总体架构,但替换成了ResNet块。先是7X7的卷积---->batch norm------->3X3的max pooling,加上不同的Resnet块,最后有一个全局的平均池化层。
ResNet代码详解
ResNet代码
import torch
import torch.nn as nn
from .utils import load_state_dict_from_url #这里是为了加载预训练模型需要的
#提供官方预训练模型的下载地址
model_urls = {
'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth',
'resnet34': 'https://download.pytorch.org/models/resnet34-333f7ec4.pth',
'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',
'resnet101': 'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth',
'resnet152': 'https://download.pytorch.org/models/resnet152-b121ed2d.pth',
'resnext50_32x4d': 'https://download.pytorch.org/models/resnext50_32x4d-7cdf4587.pth',
'resnext101_32x8d': 'https://download.pytorch.org/models/resnext101_32x8d-8ba56ff5.pth',
'wide_resnet50_2': 'https://download.pytorch.org/models/wide_resnet50_2-95faca4d.pth',
'wide_resnet101_2': 'https://download.pytorch.org/models/wide_resnet101_2-32ee1156.pth',
}
#封装下3x3卷积层(卷积层的bias置为False是因为卷积层后面要加BN层,因此这里的bias不需要)
#Conv2d函数的具体参数说明可参见Pytorch官方手册https://pytorch-cn.readthedocs.io/zh/latest/package_references/torch-nn/#_1
def con3x3(in_planes, out_planes, stride=1, groups=1, dilation=1):
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=dilation, groups=groups, bias=False, dilation=dilation)
#封装下1x1卷积层
def con1x1(in_planes, out_planes, stride=1):
return nn.Conv2d(in_planes, out_planes, kenerl_size=1, stride=stride, bias=False)
#定义BasicBlock
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsaple=None, groups=1,
base_width=64, dilation=1, norm_layer=None):
super(BasicBlock, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
if groups !=1 or base_width != 64:
raise ValueError('BasicBlock only supports groups=1 and base_width=64')
if dilation > 1:
raise NotImplementedError("Dilation > 1 not supported in BasicBlock")
#下面定义BasicBlock中的各个层
self.conv1 = con3x3(inplanes, planes, stride)
self.bn1 = norm_layer(planes)
self.relu = nn.ReLU(inplace=True) #inplace为True表示进行原地操作,一般默认为False,表示新建一个变量存储操作
self.conv2 = con3x3(planes, planes)
self.bn2 = norm_layer(planes)
self.dowansample = downsaple
self.stride = stride
#定义前向传播函数将前面定义的各层连接起来
def forward(self, x):
identity = x #这是由于残差块需要保留原始输入
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.dowansample is not None: #这是为了保证原始输入与卷积后的输出层叠加时维度相同
identity = self.dowansample(x)
out += identity
out = self.relu(out)
return out
#下面定义Bottleneck层(Resnet50以上用到的基础块)
class Bottleneck(nn.Module):
expansion = 4 #Bottleneck层输出通道都是输入的4倍
def __init__(self, inplanes, planes, stride=1, downnsaple=None, groups=1,
base_width=64, dilation=1, norm_layer=None):
super(Bottleneck, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
width = int(planes * (base_width / 64.)) * groups
#定义Bottleneck中各层
self.conv1 = con1x1(inplanes, width)
self.bn1 = norm_layer(width)
self.conv2 = con3x3(width, width, stride, groups, dilation)
self.bn2 = norm_layer(width)
self.conv3 = con1x1(width, planes * self.expansion)
self.bn3 = norm_layer(planes * self.expansion)
self.relu = nn.ReLU(inplanes=True)
self.downsaple = downnsaple
self.stride = stride
#定义Bottleneck的前向传播
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out = self.relu(out)
if self.downsaple is not None:
identity = self.downsaple(x)
out += identity
out = self.relu(out)
return out
#下面进入正题,定义ResNet类
class ResNet(nn.Module):
def __init__(self, block, layer, num_classes=1000, zero_init_residual=False,
groups=1, width_per_group=64, replace_stride_with_dilation=None,
norm_layer=None):
super(ResNet, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
self._norm_layer = norm_layer
self.inplanes = 64
self.dilation = 1
if replace_stride_with_dilation is None:
replace_stride_with_dilation = [False, False, False]
if len(replace_stride_with_dilation) != 3:
raise ValueError("replace_stride_with_dilation should be None "
"or a 3-element tuple, got {}".format(replace_stride_with_dilation))
self.groups = groups
self.base_width = width_per_group
self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = norm_layer(self.inplanes)
self.relu = nn.ReLU(self.inplanes)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layer[0])
self.layer2 = self._make_layer(block, 128, layer[1], stride=2,
dilate=replace_stride_with_dilation[0])
self.layer3 = self._make_layer(block, 256, layer[2], stride=2,
dilate=replace_stride_with_dilation[1])
self.layer4 = self._make_layer(block, 512, layer[3], stride=2,
dilate=replace_stride_with_dilation[2])
self.avgpool = nn.AdaptiveAvgPool2d((1,1))
self.fc = nn.Linear(512 * block.expanion, num_classes)
#定义初始化方式
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_nomal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
if zero_init_residual:
for m in self.modules():
if isinstance(m, Bottleneck):
nn.init.constant_(m.bn3.weight, 0)
elif isinstance(m, BasicBlock):
nn.init.constant_(m.bn2.weight, 0)
def _make_layer(self, block, planes, blocks, stride=1, dilate=False):
norm_layer = self._norm_layer
downsaple = None
previous_dilation = self.dilation
if dilate:
self.dilation *= stride
stride = 1
if stride != 1 or self.inplanes != planes * block.expanion:
downsaple = nn.Sequential(
con1x1(self.inplanes, planes * block.expanion, stride),
norm_layer(planes * block.expanion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsaple, self.groups,
self.base_width, previous_dilation, norm_layer))
self.inplanes = planes * block.expanion
for _ in range(1, block):
layers.append(block(self.inplanes, planes, groups=self.groups,
base_width=self.base_width, dilate=self.dilation,
norm_layer=norm_layer))
return nn.Sequential(*layers)
def _forward_impl(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
def forward(self, x):
return self._forward_impl(x)
def _resnet(arch, block, layers, pretrained, progress, **kwargs):
model = ResNet(block, layers, **kwargs)
if pretrained:
state_dict = load_state_dict_from_url(model_urls[arch],
progress=progress)
model.load_state_dict(state_dict)
return model
def resnet34(pretrained=False, progress=True, **kwargs):
return _resnet('resnet34', BasicBlock, [3, 4, 6, 3], pretrained, progress,
**kwargs)
def resnet101(pretrained=False, progress=True, **kwargs):
return _resnet('resnet101', Bottleneck, [3, 4, 23, 3], pretrained, progress,
**kwargs)
总结
GoogLeNet 总结:inception块用4条有不同的超参数的卷积层和池化层的路来抽取不同的信息。他的一个主要优点是模型参数小,加速那复杂度低。GoogleNet使用了9个inception块,是第一个达到上百层的网络。
Batch Normalization总结:
批量归一化就是固定小批量中的均值和方差,然后学习出适合的偏移和缩放。
可以加速收敛速度,但一般不改变模型的精度。
ResNet总结:残差块使得很深的网络更加容易训练,甚至可以训练一千层的网络,因为就算我的网络再深,我里面包含着一些小的网络,先把小的训练好,再训练更深的。