【机器学习】主成分分析
有任何的书写错误、排版错误、概念错误等,希望大家包含指正。
维数灾难
在高维情形下出现的数样本稀疏、距离计算困难等问题,是所有机器学习方法共同面临的的严重障碍,被称为“维数灾难”或“维数危机”(curse of dimensionality)。
为了方便思考,我们对离散属性(样本特征)进行分析。属性 a 1 a_1 a1 的可选值数量为 10 10 10 个,那么想要覆盖整个由 a 1 a_1 a1 构成的属性空间,需要 10 10 10 个在属性 a 1 a_1 a1 取值不同的样本即可;增加一个可选值数量同样为 10 10 10 的属性 a 2 a_2 a2,此时属性空间是由 a 1 a_1 a1 和 a 2 a_2 a2 构成的二维空间,需要 1 0 2 10^2 102 个在属性 a 1 a_1 a1 或属性 a 2 a_2 a2 上取值不同的样本。故,对于 d d d 维属性空间,需要的样本个数为 1 0 d 10^d 10d ,显然覆盖整个属性空间的样本个数是随着维度增加而指数级增长的。
所需样本的个数增长是迅速的,但是实际我们能够拥有的训练样本数量相对较少的,导致训练样本在属性空间中的分布是稀疏的,也更容易找到一个超平面将训练样本分开。因为随着属性数量趋向于无限大,样本密度非常稀疏,训练样本被分错的可能性趋向于零。当我们将高维空间的分类结果映射到低维空间时,会出现一个严重的问题,样本几乎被非线性分类器完美分类,低维中的分类决策面变得非常复杂,甚至出现单个样本与其他样本被决策面隔开的情况,这就是我们常说的“过拟合”现象(over-fitting)。
缓解维数灾难的两个重要途径是降维(dimension reduction)和特征选择(feature selection)。其中降维一般是通过某种数学变换将原始高维属性空间转变为一个低维“子空间”,在这个子空间中样本密度大幅提高,距离计算也变得更为容易。之所以可以进行降维操作,是因为很多时候,人们观测或收集到的数据样本虽然是高维的,但与学习任务密切相关的也许仅是某个低维分布,即高维空间中的一个低维“嵌入”(embedding)。可以理解为尽管观测样本的属性非常多,但是仅需其中的少量属性就可以训练出最佳分类器或预测器。
下面我们将介绍降维中的经典算法,主成分分析(Principal Component Analysis,PCA)。
主成分分析
主成分分析的主要思想是,首先对给定样本进行中心化,使得样本的每一个属性的均值变为 0 0 0。之后对样本进行正交变换,原来由线性相关变量表示的样本,通过正交变换变成若干个线性无关的新(抽象)属性表示的样本。新属性是可能的正交变换中原属性的方差和(信息保存)最大的,方差表示在新属性上信息的大小。。将新变量依次称为第一主成分、第二主成分等。这就是主成分分析的基本思想。通过主成分分析,可以利用主成分近似地表示原始数据,这可理解为发现数据的"基本结构" ;也可以把数据由少数主成分表示,这可理解为对数据降维。
注意:
主成分分析的第一步,也可以选择对原始数据进行标准化,而不是中心化,下面公式的推导采用的是中心化;
原样本经过正交变换后,得到的新属性一般是没有具体含义的,或者是我们无法用语言理解的,故称为抽象属性;
在信息论中,数据越混乱提供的信息越多,因为方差是对变量混乱程度的表达,所以方差越大,保留的信息量越大;
降维是通过选出几个主成分来实现的,如果选出全部主成分就起不到我们想要的降维效果了。
几何解释
下面给出主成分分析的直观解释。假设存在一些二维样本,对这些样本进行进行中心化(或规范化)后如图 1 1 1 左子图所示。主成分分析希望找到若干正交坐标轴,使样本在新坐标系下的方差尽可能大。对比图 1 1 1 右子图的 b 1 b_1 b1 轴和 b 2 b_2 b2 轴,显然将样本投影到 b 2 b_2 b2 轴比投影到 b 1 b_1 b1 轴更加聚集,保留的信息也就更少。极端一点来理解,如果样本投影到 b 1 b_1 b1 轴没有发生任何重叠,但是投影到 b 2 b_2 b2 轴的样本完全重叠成一个点,对比两种投影方式,想要通过投影后的样本恢复得到原始样本信息,用投影到 b 1 b_1 b1 轴的样本进行恢复会更加准确。
当然,在选取投影面(轴)时不能仅仅对比 b 1 b_1 b1 和 b 2 b_2 b2 两个轴,而是从全部可能的轴中选择最佳的轴。 从下图中可以看到我们认为 b 1 b_1 b1 是最佳的轴,获取到的第一个轴 b 1 b_1 b1 被称为第一主成分。接下来是确定第二、三、…… 主成分,次主属性要在保证与前面全部主成分正交的前提下投影方差最大,之所以要求正交,是因为希望新属性线性无关。对于图 1 1 1 的二维样本而言,确定了第一主成分 b 1 b_1 b1 后,只能选择唯一的与 b 1 b_1 b1 正交的 b 2 b_2 b2 作为第二主成分,且仅包括这两个主成分。
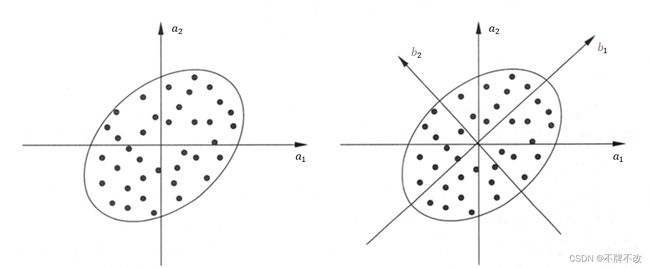
图 1 主成分分析的示例
再看看最大方差的几何解释。假设有两个属性 a 1 a_1 a1 和 a 2 a_2 a2,三个样本点 A A A、 B B B 和 C C C,样本分布在由 a 1 a_1 a1 和 a 2 a_2 a2 组成的坐标系中,如图 2 2 2 所示。对坐标系进行旋转变换,得到新的坐标轴 b 1 b_1 b1,表示新的属性 b 1 b_1 b1。样本点 A A A、 B B B、 C C C 在 b 1 b_1 b1 轴上投影,得到 b 1 b_1 b1 轴的坐标值 A ′ A' A′、 B ′ B' B′、 C ′ C' C′。坐标值的平方和 O A ′ 2 + O B ′ 2 + O C ′ 2 OA'^2 + OB'^2 + OC'^2 OA′2+OB′2+OC′2 表示样本在新属性上的方差和。主成分分析旨在选取正交变换中方差最大的变量,作为第一主成分, 也就是旋转变换中坐标值的平方和最大的轴。注意到旋转变换中样本点到原点的距离的平方和 O A 2 + O B 2 + O C 2 OA^2 + OB^2 + OC^2 OA2+OB2+OC2 保持不变,根据勾股定理,坐标值的平方和 O A ′ 2 + O B ′ 2 + O C ′ 2 OA'^2 + OB'^2 + OC'^2 OA′2+OB′2+OC′2 最大等价于样本点到 b 1 b_1 b1 轴的距离的平方和 A A ′ 2 + B B ′ 2 + C C ′ 2 AA'^2 + BB'^2 + CC'^2 AA′2+BB′2+CC′2 最小。所以,等价地, 主成分分析在旋转变换中选取离样本点的距离平方和最小的轴,作为第一主成分。第二主成分等的选取,在保证与己选坐标轴正交的条件下,类似地进行。
因为已经对原坐标系下的样本进行了中心化,所以在计算投影后样本在 b 1 b_1 b1 上的方差时,无需再进行中心化,此时的坐标值已经是中心化后的值了,故直接平方再累加就是样本方差。具体证明也非常简单,不再展示。
严谨的来说,样本方差的平方项系数应该为 1 n − 1 \frac{1}{n-1} n−11,数据总体方差的平方项系数应该为 1 n \frac{1}{n} n1,但是我们有时候会忽略系数,并且讨论”数据总体“而不是”样本“,这些约定都是为了方便处理和理解,所以见到忽略系数的方差也不要差异,它们只是相差一个倍数。
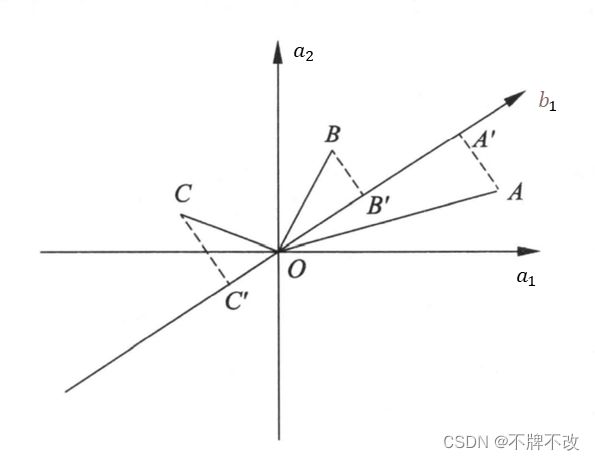
图 2 主成分的几何解释
两个角度
上面仅从几何角度解释了 PCA 的思想,接下来我们从”最大投影方差“和”最小重构代价“两个角度来介绍数学推导。
首先我们规定常用符号。数据集 D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , … , ( x n , y n ) } D=\{(x_1,y_1),(x_2,y_2),\dots,(x_n,y_n)\} D={(x1,y1),(x2,y2),…,(xn,yn)},向量 x i ∈ R p x_i\in\mathbb{R}^p xi∈Rp 为样本, y i ∈ R y_i\in \mathbb R yi∈R 为标签, i = 1 , 2 , … , n i=1,2,\dots,n i=1,2,…,n; W ∈ R p W\in \mathbb R^p W∈Rp 为模型参数(权重)。
记
X = ( x 1 x 2 … x n ) T = ( x 1 T x 2 T ⋮ x n T ) = ( x 11 x 12 … x 1 p x 21 x 22 … x 2 p ⋮ ⋮ ⋮ x n 1 x n 2 … x n p ) n × p Y = ( y 1 y 2 … y n ) n × 1 T X= \left( \begin{matrix} x_1 & x_2 & \dots & x_n \end{matrix} \right)^T =\left( \begin{matrix} x_1^T \\ x_2^T \\ \vdots \\ x_n^T \end{matrix} \right) =\left( \begin{matrix} x_{11} & x_{12} & \dots & x_{1p} \\ x_{21} & x_{22} & \dots & x_{2p} \\ \vdots & \vdots & & \vdots \\ x_{n1} & x_{n2} & \dots & x_{np} \\ \end{matrix} \right)_{n\times p} \\ \\ Y=\left( \begin{matrix} y_1 & y_2 & \dots & y_n \end{matrix} \right)^T_{n\times 1} X=(x1x2…xn)T=⎝⎜⎜⎜⎛x1Tx2T⋮xnT⎠⎟⎟⎟⎞=⎝⎜⎜⎜⎛x11x21⋮xn1x12x22⋮xn2………x1px2p⋮xnp⎠⎟⎟⎟⎞n×pY=(y1y2…yn)n×1T
令
1 n = ( 1 1 ⋮ 1 ) 1_n = \left(\begin{matrix} 1 \\ 1 \\ \vdots \\ 1 \end{matrix}\right) 1n=⎝⎜⎜⎜⎛11⋮1⎠⎟⎟⎟⎞
那么,样本均值可以表示为
X ˉ p × 1 = 1 n ∑ i = 1 n x i = 1 n ( x 1 x 2 … x n ) ( 1 1 ⋮ 1 ) = 1 n X T 1 n \begin{aligned} \bar X_{p\times 1}&=\frac{1}{n}\sum_{i=1}^nx_i\\ &=\frac{1}{n} \left( \begin{matrix} x_1 & x_2 & \dots & x_n \end{matrix} \right)\left(\begin{matrix} 1 \\ 1 \\ \vdots \\ 1 \end{matrix}\right)\\ &=\frac{1}{n}X^T1_n \end{aligned} Xˉp×1=n1i=1∑nxi=n1(x1x2…xn)⎝⎜⎜⎜⎛11⋮1⎠⎟⎟⎟⎞=n1XT1n
样本方差(协方差矩阵)表示为
S p × p = 1 n ∑ i = 1 n ( x i − X ˉ ) ( x i − X ˉ ) T = 1 n ( x 1 − X ˉ x 2 − X ˉ … x n − X ˉ ) ( ( x 1 − X ˉ ) T ( x 2 − X ˉ ) T ⋮ ( x n − X ˉ ) T ) = 1 n ( ( x 1 x 2 … x n ) − X ˉ 1 n T ) ( ( x 1 T x 2 T ⋮ x n T ) − 1 n X ˉ T ) = 1 n ( X T − X ˉ 1 n T ) ( X − 1 n X ˉ T ) = 1 n ( X T − 1 n X T 1 n 1 n T ) ( X − 1 n 1 n 1 n T X ) = 1 n X T ( I n − 1 n 1 n 1 n T ) ( I n − 1 n 1 n 1 n T ) X \begin{aligned} S_{p\times p} &= \frac{1}{n}\sum_{i=1}^n (x_i-\bar X)(x_i - \bar X)^T \\ &=\frac{1}{n} \left(\begin{matrix} x_1 - \bar X & x_2-\bar X & \dots & x_n-\bar X\end{matrix}\right) \left(\begin{matrix} (x_1-\bar X)^T \\ (x_2 - \bar X)^T \\ \vdots \\ (x_n-\bar X)^T \end{matrix}\right)\\ &= \frac{1}{n} \big(\left(\begin{matrix} x_1 & x_2 & \dots & x_n \end{matrix}\right) -\bar X1_n^T\big) \big(\left(\begin{matrix} x_1^T \\ x_2^T \\ \vdots \\ x_n^T \end{matrix}\right)-1_n \bar X^T \big)\\ &=\frac{1}{n} (X^T - \bar X1_n^T)(X-1_n\bar X^T) \\ &=\frac{1}{n} (X^T - \frac{1}{n} X^T1_n1_n^T)(X-\frac{1}{n}1_n1_n^TX) \\ &=\frac{1}{n} X^T(I_n - \frac{1}{n} 1_n1_n^T)(I_n-\frac{1}{n}1_n1_n^T)X \\ \end{aligned} Sp×p=n1i=1∑n(xi−Xˉ)(xi−Xˉ)T=n1(x1−Xˉx2−Xˉ…xn−Xˉ)⎝⎜⎜⎜⎛(x1−Xˉ)T(x2−Xˉ)T⋮(xn−Xˉ)T⎠⎟⎟⎟⎞=n1((x1x2…xn)−Xˉ1nT)(⎝⎜⎜⎜⎛x1Tx2T⋮xnT⎠⎟⎟⎟⎞−1nXˉT)=n1(XT−Xˉ1nT)(X−1nXˉT)=n1(XT−n1XT1n1nT)(X−n11n1nTX)=n1XT(In−n11n1nT)(In−n11n1nT)X
令
H = I n − 1 n 1 n 1 n T H=I_n-\frac{1}{n} 1_n1_n^T H=In−n11n1nT
矩阵 H H H 称为中心化矩阵,其作用是通过数据左乘 H H H 实现将一组数据中心化,即 H X HX HX 。
矩阵 H H H 具有如下性质:
- H T = ( I n − 1 n 1 n 1 n T ) T = ( I n − 1 n 1 n 1 n T ) = H H^T=(I_n-\frac{1}{n} 1_n1_n^T)^T = (I_n-\frac{1}{n}1_n1_n^T)=H HT=(In−n11n1nT)T=(In−n11n1nT)=H
- H 2 = H H^2=H H2=H
证明:
H 2 = ( I n − 1 n 1 n 1 n T ) ( I n − 1 n 1 n 1 n T ) = I n − 2 n 1 n 1 n T + 1 n 2 1 n 1 n T 1 n 1 n T \begin{aligned} H^2 &=(I_n-\frac{1}{n} 1_n1_n^T )(I_n-\frac{1}{n} 1_n1_n^T )\\ &=I_n-\frac{2}{n}1_n1_n^T + \frac{1}{n^2}1_n1_n^T1_n1_n^T \end{aligned} H2=(In−n11n1nT)(In−n11n1nT)=In−n21n1nT+n211n1nT1n1nT
其中 1 n 1 n T 1 n 1 n T = 1 n ( 1 n T 1 n ) 1 n T = n 1 n 1 n T 1_n1_n^T1_n1_n^T=1_n(1_n^T1_n)1_n^T=n1_n1_n^T 1n1nT1n1nT=1n(1nT1n)1nT=n1n1nT 为元素全是 n n n 的矩阵可得
1 n 2 1 n 1 n T 1 n 1 n T = 1 n ( 1 1 … 1 1 1 … 1 ⋮ ⋮ ⋮ 1 1 … 1 ) 2 n 1 n 1 n T = 2 n ( 1 1 … 1 1 1 … 1 ⋮ ⋮ ⋮ 1 1 … 1 ) \frac{1}{n^2}1_n1_n^T1_n1_n^T = \frac{1}{n}\left(\begin{matrix} 1 & 1 & \dots & 1 \\ 1& 1 &\dots & 1 \\ \vdots & \vdots & & \vdots \\1 & 1 & \dots & 1 \end{matrix}\right) \\ \frac{2}{n}1_n1_n^T = \frac{2}{n}\left(\begin{matrix} 1 & 1 & \dots & 1 \\ 1& 1 &\dots & 1 \\ \vdots & \vdots & & \vdots \\1 & 1 & \dots & 1 \end{matrix}\right) \\ n211n1nT1n1nT=n1⎝⎜⎜⎜⎛11⋮111⋮1………11⋮1⎠⎟⎟⎟⎞n21n1nT=n2⎝⎜⎜⎜⎛11⋮111⋮1………11⋮1⎠⎟⎟⎟⎞
故
H 2 = I n − 1 n ( 1 1 … 1 1 1 … 1 ⋮ ⋮ ⋮ 1 1 … 1 ) = I n − 1 n 1 n 1 n T = H H^2=I_n - \frac{1}{n}\left(\begin{matrix} 1 & 1 & \dots & 1 \\ 1& 1 &\dots & 1 \\ \vdots & \vdots & & \vdots \\1 & 1 & \dots & 1 \end{matrix}\right) = I_n - \frac{1}{n}1_n1_n^T = H H2=In−n1⎝⎜⎜⎜⎛11⋮111⋮1………11⋮1⎠⎟⎟⎟⎞=In−n11n1nT=H
将 H H H 代入 S S S 中得
S = 1 n X T H H X = 1 n X T H X S = \frac{1}{n}X^THHX=\frac{1}{n}X^THX S=n1XTHHX=n1XTHX
最大投影方差
上面提到 PCA 是希望找到方差最大的投影面,假设我们要找的第一主成分为 u 1 u_1 u1,满足 ∣ ∣ u 1 ∣ ∣ 2 = 1 ||u_1||_2=1 ∣∣u1∣∣2=1。将中心化后的样本 x i ′ = x i − X ˉ x_i'=x_i-\bar X xi′=xi−Xˉ 投影到 u 1 u_1 u1 上的值的含义为样本 x ′ x' x′ 在轴 u 1 u_1 u1 上的分量或坐标值,即 x ′ T u 1 x'^Tu_1 x′Tu1。对于已经中心化的数据来说,将投影后的数据依然是中心化的,那么投影后的这些样本在 u 1 u_1 u1 轴上坐标值的方差为 1 n ( x ′ T u 1 ) 2 \frac{1}{n}(x'^Tu_1)^2 n1(x′Tu1)2。
根据最大投影方差的思想,定义损失函数
J = 1 n ∑ i = 1 n ( ( x i − X ˉ ) T u 1 ) 2 s . t . u 1 T u 1 = 1 J = \frac{1}{n} \sum_{i=1}^n \big((x_i-\bar X)^Tu_1\big )^2 \\ s.t.\space\space\space\space u_1^Tu_1=1 J=n1i=1∑n((xi−Xˉ)Tu1)2s.t. u1Tu1=1
其中, J J J 可以进一步变形
J = 1 n ∑ i = 1 n ( ( x i − X ˉ ) T u 1 ) T ( ( x i − X ˉ ) T u 1 ) = 1 n ∑ i = 1 n u 1 T ( x i − X ˉ ) ( x i − X ˉ ) u 1 = u 1 T ( 1 n ∑ i = 1 n ( x i − X ˉ ) ( x i − X ˉ ) T ) u 1 = u 1 T S u 1 \begin{aligned} J &= \frac{1}{n}\sum_{i=1}^n \big((x_i-\bar X)^Tu_1\big )^T\big((x_i-\bar X)^Tu_1\big ) \\ &= \frac{1}{n} \sum_{i=1}^n u_1^T(x_i-\bar X)(x_i-\bar X)u_1 \\ &= u_1^T\big(\frac{1}{n} \sum_{i=1}^n(x_i-\bar X)(x_i-\bar X)^T \big) u_1 \\ &=u_1^TSu_1 \end{aligned} J=n1i=1∑n((xi−Xˉ)Tu1)T((xi−Xˉ)Tu1)=n1i=1∑nu1T(xi−Xˉ)(xi−Xˉ)u1=u1T(n1i=1∑n(xi−Xˉ)(xi−Xˉ)T)u1=u1TSu1
最大化投影后的方差就是最大化损失函数,所以
u ^ 1 = a r g max u 1 u 1 T S u 1 s . t . u 1 T u 1 = 1 (1) \hat u_1 = {\rm arg}\max_{u_1} \space u_1^TSu_1 \tag{1}\\ s.t.\space\space\space\space u_1^Tu_1=1 u^1=argu1max u1TSu1s.t. u1Tu1=1(1)
定义拉格朗日函数
L ( u 1 , λ ) = u 1 T S u 1 + λ ( 1 − u 1 T u 1 ) L(u_1, \lambda) = u_1^TSu_1+\lambda(1-u_1^Tu_1) L(u1,λ)=u1TSu1+λ(1−u1Tu1)
对 u 1 u_1 u1 计算偏导,得
∂ L ∂ u 1 = 2 S u 1 − 2 λ u 1 \frac{\partial L}{\partial u_1}=2Su_1-2\lambda u_1 ∂u1∂L=2Su1−2λu1
令偏导等于 0 0 0,得
S u 1 = λ u 1 u 1 T S u 1 = λ (2) \begin{aligned} Su_1 &= \lambda u_1 \\ u_1^TSu_1&= \lambda \tag{2} \end{aligned} Su1u1TSu1=λu1=λ(2)
可见, λ \lambda λ 为协方差矩阵 S S S 的特征值, u 1 u_1 u1 既是特征向量也是第一主成分。式 ( 1 ) (1) (1) 中的 u 1 T S u 1 u_1^TSu_1 u1TSu1 为我们要最大化的目标,亦式 ( 2 ) (2) (2) 的左侧部分,因此最大的特征值 λ 1 \lambda_1 λ1 对应的特征向量 u 1 u_1 u1 为第一主成分。
接着求第二主成分 u 2 u_2 u2,第二主成分不仅要保证 ∣ ∣ u 2 ∣ ∣ 2 = 1 ||u_2||_2=1 ∣∣u2∣∣2=1,而且需要满足与第一主成分正交,即 u 2 T u 1 = 0 u_2^Tu_1=0 u2Tu1=0。对应式 ( 1 ) (1) (1) 可得
u ^ 2 = a r g max u 2 u 2 T S u 2 s . t . u 2 T u 2 = 1 , u 2 T u 1 = 0 \hat u_2 = {\rm arg}\max_{u_2} \space u_2^TSu_2 \\ s.t.\space\space\space\space u_2^Tu_2=1,\space\space\space\space u^T_2u_1=0 u^2=argu2max u2TSu2s.t. u2Tu2=1, u2Tu1=0
定义拉格朗日函数
L ( u 2 , λ , ϕ ) = u 2 T S u 2 + λ ( 1 − u 2 T u 2 ) − ϕ u 2 T u 1 L(u_2, \lambda, \phi) = u_2^TSu_2 + \lambda(1-u_2^Tu_2)-\phi u_2^Tu_1 L(u2,λ,ϕ)=u2TSu2+λ(1−u2Tu2)−ϕu2Tu1
注意,此时 u 1 u_1 u1 已经计算出来了,是已知的。
对 u 2 u_2 u2 计算偏导,并令其等于 0 0 0,得
2 S u 2 − 2 λ u 2 − ϕ u 1 = 0 (3) 2Su_2 - 2\lambda u_2-\phi u_1=0 \tag{3} 2Su2−2λu2−ϕu1=0(3)
将方程左乘 u 1 T u_1^T u1T 有
2 u 1 T S u 2 − 2 λ u 1 T u 2 − ϕ u 1 T u 1 = 0 2u_1^TSu_2 - 2\lambda u_1^Tu_2-\phi u_1^Tu_1=0 2u1TSu2−2λu1Tu2−ϕu1Tu1=0
此式前两项为 0 0 0,且 u 1 T u 1 = 1 u_1^Tu_1=1 u1Tu1=1,导出 ϕ = 0 \phi=0 ϕ=0,因此式 ( 3 ) (3) (3) 变为
S u 2 − λ u 2 = 0 u 2 T S u 2 = λ Su_2-\lambda u_2=0 \\ u_2^TSu_2=\lambda Su2−λu2=0u2TSu2=λ
这与式 ( 2 ) (2) (2) 类似,可以认为第二主成分为第二大特征值 λ 2 \lambda_2 λ2 对应的单位向量 u 2 u_2 u2。
按照上面的方法我们可以递推的求得第一、第二、直到第 p p p 主成分,分别为 u 1 u_1 u1, u 2 u_2 u2, . . . ... ..., u p u_p up,对应协方差矩阵 S S S 的按对应特征值从大到小排列的特征向量。并且,第 k k k 主成分的方差等于 S S S 的第 k k k 个特征值。
整体看一下,对协方差矩阵进行特征值分解,分解得到的特征值表示样本投影到不同坐标轴上的方差,方差越大说明投影后样本的信息保留越完整,因此,我们可以选出最大的若干个特征值对应的特征向量作为坐标轴,将样本投影到新的低维坐标系中,从而实现降维。
最小重构代价
就像之前提到的,若投影后数据越分散,则重构越容易;若数据越集中,甚至重合到一个点,便很难重构回去。因此最小重构代价的思想也是在寻找投影后数据最分散的坐标轴。
中心化后的样本 x i ′ = x i − X ˉ x_i'=x_i-\bar X xi′=xi−Xˉ, x i ′ x'_i xi′ 在新坐标系中可以表示为每个坐标轴上的坐标值 x i ′ T u k x_i'^Tu_k xi′Tuk 与标准基向量 u k u_k uk 的乘积之和,即 x i ′ = ∑ k = 1 p ( x i ′ T u k ) u k x_i' = \sum_{k=1}^p (x_i'^Tu_k)u_k xi′=∑k=1p(xi′Tuk)uk 。假设特征向量 u i u_i ui 按照特征值 λ i λ_i λi 从大到小排列, u 1 u_1 u1 对应的 λ 1 λ_1 λ1 最大, u p u_p up 对应的 λ p λ_p λp 最小。我们将样本从 p p p 维降至 q ( q < p ) q\space(q
最小重构代价的思想是将降维后的 x ^ i ′ \hat x_i' x^i′ 还原为 x i ′ x_i' xi′ 所需代价最小,我们用二者的相似程度来度量代价,相似程度的度量方式为二范数平方。故,损失函数为
J = 1 n ∑ i = 1 n ∣ ∣ x i ′ − x ^ i ′ ∣ ∣ 2 2 = 1 n ∑ i = 1 n ∣ ∣ ∑ k = 1 p ( x i ′ T u k ) u k − ∑ k = 1 q ( x i ′ T u k ) u k ∣ ∣ 2 2 = 1 n ∑ i = 1 n ∣ ∣ ∑ k = q + 1 p ( x i ′ T u k ) u k ∣ ∣ 2 2 \begin{aligned} J&=\frac{1}{n}\sum_{i=1}^n || x'_i - \hat x_i' ||_2^2\\ &=\frac{1}{n}\sum_{i=1}^n|| \sum_{k=1}^p (x_i'^Tu_k)u_k - \sum_{k=1}^q (x_i'^Tu_k)u_k ||_2^2 \\ &=\frac{1}{n}\sum_{i=1}^n|| \sum_{k=q+1}^p (x_i'^Tu_k)u_k ||_2^2 \\ \end{aligned} J=n1i=1∑n∣∣xi′−x^i′∣∣22=n1i=1∑n∣∣k=1∑p(xi′Tuk)uk−k=1∑q(xi′Tuk)uk∣∣22=n1i=1∑n∣∣k=q+1∑p(xi′Tuk)uk∣∣22
我们注意到 ∑ k = q + 1 p ( x i ′ T u k ) u k \sum_{k=q+1}^p (x_i'^Tu_k)u_k ∑k=q+1p(xi′Tuk)uk 是一个向量,可以理解为该向量是在标准正交基 { u k } ( k = q + 1 , … , p ) \{u_k\}\space (k=q+1,\dots,p) {uk} (k=q+1,…,p) 构成的坐标系中坐标为 ( x i ′ T u q + 1 , x i ′ T u q + 2 , … , x i ′ T u p ) \big(x_i'^Tu_{q+1},x_i'^Tu_{q+2},\dots,x_i'^Tu_p\big) (xi′Tuq+1,xi′Tuq+2,…,xi′Tup) 的向量。在标准正交基下,对该向量求二范数的平方可以简化表示坐标值的平方和,即 ∣ ∣ ∑ k = q + 1 p ( x i ′ T u k ) u k ∣ ∣ 2 2 = ∑ k = q + 1 p ( x i ′ T u k ) 2 ||\sum_{k=q+1}^p (x_i'^Tu_k)u_k||_2^2=\sum_{k=q+1}^p(x_i'^Tu_k)^2 ∣∣∑k=q+1p(xi′Tuk)uk∣∣22=∑k=q+1p(xi′Tuk)2 。因此,损失函数变为
J = 1 n ∑ i = 1 n ∑ k = q + 1 p ( x i ′ T u k ) 2 = ∑ k = q + 1 p 1 n ∑ i = 1 n ( x i ′ T u k ) 2 = ∑ k = q + 1 p 1 n ∑ i = 1 n ( ( x i − X ˉ ) T u k ) 2 = ∑ k = q + 1 p u k T ( 1 n ∑ i = 1 n ( x i − X ˉ ) ( x i − X ˉ ) T ) u k = ∑ k = q + 1 p u k T S u k \begin{aligned} J&=\frac{1}{n}\sum_{i=1}^n\sum_{k=q+1}^p(x_i'^Tu_k)^2 \\ &= \sum_{k=q+1}^p\frac{1}{n}\sum_{i=1}^n(x_i'^Tu_k)^2 \\ &= \sum_{k=q+1}^p\frac{1}{n}\sum_{i=1}^n((x_i-\bar X)^Tu_k)^2 \\ &= \sum_{k=q+1}^p u_k^T\Big(\frac{1}{n}\sum_{i=1}^n(x_i-\bar X)(x_i-\bar X)^T \Big)u_k\\ &= \sum_{k=q+1}^p u_k^T S u_k \end{aligned} J=n1i=1∑nk=q+1∑p(xi′Tuk)2=k=q+1∑pn1i=1∑n(xi′Tuk)2=k=q+1∑pn1i=1∑n((xi−Xˉ)Tuk)2=k=q+1∑pukT(n1i=1∑n(xi−Xˉ)(xi−Xˉ)T)uk=k=q+1∑pukTSuk
最佳投影面为
u ^ k = a r g min u k ∑ k = q + 1 p u k T S u k s . t . u k T u k = 1 ( k = q + 1 , q + 2 , … , p ) \hat u_k = {\rm arg}\min_{u_k}\sum_{k=q+1}^p u_k^TS u_k\\ s.t.\space\space\space\space u_k^Tu_k=1\space\space (k=q+1,q+2,\dots,p) u^k=argukmink=q+1∑pukTSuks.t. ukTuk=1 (k=q+1,q+2,…,p)
由于 u k u_k uk 相互独立,因此可以转换为多个 a r g min u k T S u k {\rm arg}\min u_k^TSu_k argminukTSuk 的带约束优化问题,对每一个优化问题单独求解
u ^ k = a r g min u k u k T S u k s . t . u k T u k = 1 \hat u_k = {\rm arg}\min_{u_k} u_k^TS u_k\\ s.t.\space\space\space\space u_k^Tu_k=1 u^k=argukminukTSuks.t. ukTuk=1
使用拉格朗日乘数法可以得到
u k T S u k = λ k u_k^TSu_k=\lambda_k ukTSuk=λk
其中, λ k \lambda_k λk 表示协方差矩阵 S S S 第 k k k 大特征值。损失函数 J J J 可以进一步化为
J = ∑ k = q + 1 p u k T S u k = ∑ k = q + 1 p λ k \begin{aligned} J&=\sum_{k=q+1}^p u_k^TSu_k \\ &=\sum_{k=q+1}^p\lambda_k \end{aligned} J=k=q+1∑pukTSuk=k=q+1∑pλk
这与“最大投影方差”中选出最大的 q q q 个特征值对应的特征向量作为投影面类似,“最小重构代价”是丢弃最小的 p − q p-q p−q 个特征值对应的特征向量,剩下的特征向量作为投影面,也就是对公式中最大化和最小化的理解。
算法流程
PCA 算法流程非常简洁。
输入: 样 本 集 D = { x 1 , x 2 , ⋅ ⋅ ⋅ , x n } ; 低 维 空 间 维 数 q . 过程: \begin{array}{ll} \textbf{输入:}&\space样本集\space D = \{\pmb x_1,\pmb x_2,···,\pmb x_n\}\space ;&&&&&&&\\ &\space 低维空间维数 \space q\space.\\ \textbf{过程:} \end{array} 输入:过程: 样本集 D={xxx1,xxx2,⋅⋅⋅,xxxn} ; 低维空间维数 q .
1 : 对 所 有 样 本 进 行 中 心 化 : x i ← x i − 1 n ∑ i = 1 n x i ; 2 : 计 算 样 本 的 协 方 差 矩 阵 X X T ; 3 : 对 协 方 差 矩 阵 X X T 做 特 征 值 分 解 ; 4 : 取 最 大 的 q 个 特 征 值 所 对 应 的 特 征 向 量 u 1 , u 2 , … , u q \begin{array}{rl} 1:&对所有样本进行中心化:\space x_i\leftarrow x_i-\frac{1}{n}\sum_{i=1}^n x_i\space;\\ 2:&计算样本的协方差矩阵 \space XX^T\space;\\ 3:& 对协方差矩阵\space XX^T\space 做特征值分解\space; \\ 4:&取最大的 \space q \space个特征值所对应的特征向量 \space u_1,u_2,\dots,u_q\\ \end{array} 1:2:3:4:对所有样本进行中心化: xi←xi−n1∑i=1nxi ;计算样本的协方差矩阵 XXT ;对协方差矩阵 XXT 做特征值分解 ;取最大的 q 个特征值所对应的特征向量 u1,u2,…,uq
输出: 投 影 矩 阵 W = ( u 1 , u 2 , ⋅ ⋅ ⋅ , u k ) \begin{array}{l} \textbf{输出:}\space 投影矩阵\space W=(u_1,u_2,···,u_k) &&&&&&&& \end{array} 输出: 投影矩阵 W=(u1,u2,⋅⋅⋅,uk)
算法 1 PCA 算法
其实也可以通过奇异值分解来实现 PCA 算法。首先,将数据 X X X 中心化得到 H X HX HX,直接对 H X HX HX 进行奇异值分解 H X = U Σ V T HX = U\Sigma V^T HX=UΣVT。其中, V V V 便是 PCA 算法中协方差矩阵 S S S 的特征向量, Σ T Σ \Sigma^T\Sigma ΣTΣ 为特征值矩阵。
证明也非常简单。已知
S = 1 n X T H X S = \frac{1}{n} X^THX S=n1XTHX
利用 H H H 的对称性和幂等性, S S S 进一步化为
S = 1 n X T H T H X = 1 n ( H X ) T H X = ( U Σ V T ) U Σ V T = V Σ T U T U Σ V T = V Σ T Σ V T \begin{aligned} S &= \frac{1}{n} X^TH^THX \\ &=\frac{1}{n} (HX)^THX \\ &= (U\Sigma V^T) U\Sigma V^T \\ &= V\Sigma ^TU^TU\Sigma V^T \\ &= V\Sigma^T\Sigma V^T \end{aligned} S=n1XTHTHX=n1(HX)THX=(UΣVT)UΣVT=VΣTUTUΣVT=VΣTΣVT
由于 Σ T Σ \Sigma^T\Sigma ΣTΣ 为对角半正定矩阵,故
S = V Σ T Σ V T S V = V ( Σ T Σ ) S V = ( Σ T Σ ) V \begin{aligned} S &= V\Sigma^T\Sigma V^T \\ SV &= V(\Sigma^T\Sigma) \\ SV &= (\Sigma^T\Sigma) V \end{aligned} SSVSV=VΣTΣVT=V(ΣTΣ)=(ΣTΣ)V
可见,这与 PCA 中对协方差矩阵进行特征值分解等价。PCA 算法流程甚至可以减少至三步,当然,步数越少并不意味着效率更高,具体使用看具体场景。
主成分的个数
具体选择 q q q 的方法,通常利用方差贡献率。记全部样本在原坐标系下第 k k k 维分量,亦第 k k k 维属性,为 a k a_k ak
a k = ( x 1 k x 2 k ⋮ x n k ) n × 1 a_k= \left(\begin{matrix} x_{1k}\\ x_{2k}\\ \vdots \\ x_{nk} \end{matrix}\right)_{n\times1} ak=⎝⎜⎜⎜⎛x1kx2k⋮xnk⎠⎟⎟⎟⎞n×1
全部样本在第 k k k 主成分的分量为 a ^ k \hat a_k a^k
a ^ k = ( x 1 T u k x 2 T u k ⋮ x n T u k ) n × 1 \hat a_k = \left(\begin{matrix} x_1^Tu_k\\ x_2^Tu_k\\ \vdots \\ x_n^Tu_k \end{matrix}\right)_{n\times1} a^k=⎝⎜⎜⎜⎛x1Tukx2Tuk⋮xnTuk⎠⎟⎟⎟⎞n×1
第 q q q 主成分分量的方差贡献率定义为第 q q q 个主成分分量的方差与所有方差之和的比,记作 η q \eta_q ηq
η q = λ q ∑ i = 1 p λ i \eta_q = \frac{\lambda_q}{\sum_{i=1}^p \lambda_i} ηq=∑i=1pλiλq
其中, λ k \lambda_k λk 表示协方差矩阵 S S S 的第 k k k 大特征值。
前 q q q 个主成分分量的累计方差贡献率定义为 q q q 个方差之和与所有方差之和的比
∑ i = 1 q η i = ∑ i = 1 q λ i ∑ i = 1 q λ i \sum_{i=1}^q\eta_i = \frac{\sum_{i=1}^q\lambda_i}{\sum_{i=1}^q\lambda_i} i=1∑qηi=∑i=1qλi∑i=1qλi
通常取 q q q 使得累计方差贡献率达到规定的百分比以上,例如 70%~80% 以上。累计方差贡献率反映了数据在主成分上保留信息的比例,但它不能反映对某个原有属性 a i a_i ai 保留信息的比例,这时通常利用数据在前 q q q 个主成分投影值对原有属性 a i a_i ai 的贡献率。
这句话的含义为,累积方差贡献直接度量的是方差大小,即降维保留了多少主成分信息,但是主成分信息又不能与属性信息直接划等,因此度量属性信息的保留程度也非常有必要。
前 q q q 个主成分分量 a ^ 1 , a ^ 2 , … , a ^ q \hat a_1,\hat a_2,\dots,\hat a_q a^1,a^2,…,a^q 对原有属性 a i a_i ai 的贡献率定义为 a i a_i ai 与 ( a ^ 1 , a ^ 2 , … , a ^ q ) (\hat a_1,\hat a_2,\dots,\hat a_q) (a^1,a^2,…,a^q) 的相关系数的平方,记作 V i \mathcal{V}_i Vi
V i = ρ 2 ( a i , ( a ^ 1 , a ^ 2 , … , a ^ q ) ) \mathcal{V}_i = \rho^2\big( a_i, (\hat a_1,\hat a_2,\dots,\hat a_q) \big) Vi=ρ2(ai,(a^1,a^2,…,a^q))
计算公式为
V i = ρ 2 ( a i , ( a ^ 1 , a ^ 2 , … , a ^ q ) ) = ∑ j = 1 q ρ 2 ( a i , a ^ j ) \mathcal{V}_i = \rho^2\big( a_i, (\hat a_1,\hat a_2,\dots,\hat a_q) \big)=\sum_{j=1}^q\rho^2(a_i,\hat a_j) Vi=ρ2(ai,(a^1,a^2,…,a^q))=j=1∑qρ2(ai,a^j)
因为
ρ ( a i , a ^ j ) = c o v ( a i , a ^ j ) v a r ( a i ) v a r ( a ^ j ) = c o v ( X e i , X u j ) σ i i λ j \rho(a_i,\hat a_j) = \frac{{\rm cov}(a_i, \hat a_j)}{\sqrt{{\rm var}(a_i){\rm var}(\hat a_j)}}=\frac{{\rm cov}(Xe_i,Xu_j)}{\sqrt{\sigma_{ii}}\sqrt{\lambda_j}} ρ(ai,a^j)=var(ai)var(a^j)cov(ai,a^j)=σiiλjcov(Xei,Xuj)
其中, e i e_i ei 为基本单位向量,其第 i i i 个分量为 1 1 1,其余为 0 0 0 ; σ i i \sigma_{ii} σii 表示协方差矩阵 S S S 第 i i i 行第 i i i 列元素。再由协方差的性质
c o v ( X e i , X u j ) = e i T S u j = λ j e i T u j = λ j u i j {\rm cov}(Xe_i,Xu_j)=e_i^TSu_j = \lambda_je^T_iu_j=\lambda_ju_{ij} cov(Xei,Xuj)=eiTSuj=λjeiTuj=λjuij
因此
ρ ( a i , a ^ j ) = λ j u i j σ i i \rho(a_i,\hat a_j) =\frac{\sqrt{\lambda_j}u_{ij}}{\sqrt{\sigma_{ii}}} ρ(ai,a^j)=σiiλjuij
故 V i \mathcal{V}_i Vi 可以进一步变化为
V i = ∑ j = 1 q ρ 2 ( a i , a ^ j ) = ∑ j = 1 q λ j u i j 2 σ i i \mathcal{V}_i = \sum_{j=1}^q\rho^2(a_i,\hat a_j)=\sum_{j=1}^q\frac{\lambda_j u_{ij}^2}{\sigma_{ii}} Vi=j=1∑qρ2(ai,a^j)=j=1∑qσiiλjuij2
计算原有属性 a i a_i ai 和降维后的 q q q 个主成分分量的相关系数平方之和,可以感性地理解为,投影后每个分量都可能与原有属性存在一定的相关性,可能密切相关,可能完全无关,采用相关系数度量原有属性与每个分量的相关性,对它们平方求和,累积全部相关性作为对原有属性 a i a_i ai 的保留程度。
REF
[1] 《统计学习方法(第二版)》李航著
[2] 《机器学习》周志华著
[3] 机器学习-降维 - bilibili
[4] 机器学习-白板推导系列(五)-降维(Dimensionality Reduction)笔记 - 知乎
[5] The Curse of Dimensionality in Classification