论文阅读笔记一:SESSION-BASED RECOMMENDATIONS WITHRECURRENT NEURAL NETWORKS
目录
一 论文简介
1.1 论文名称:SESSION-BASED RECOMMENDATIONS WITHRECURRENT NEURAL NETWORKS(基于RNN神经网络的会话推荐)
1.2 作者:Balázs Hidasi
1.3 发布地址:Published as a conference paper at ICLR 2016
二 论文摘要与介绍
2.1 摘要:
2.2 介绍:
三 GRU
四 GRU4REC框架
五 提升训练的策略
5.1 SESSION-PARALLEL MINI-BATCHES(会话并行小批量)
5.2 SAMPLING ON THE OUTPUT(对输出进行采样)
六 排名损失(RANKING LOSS)
七 实验部分
八 总结
一 论文简介
1.1 论文名称:SESSION-BASED RECOMMENDATIONS WITHRECURRENT NEURAL NETWORKS(基于RNN神经网络的会话推荐)
1.2 作者:Balázs Hidasi
1.3 发布地址:Published as a conference paper at ICLR 2016
二 论文摘要与介绍
2.1 先来看看是什么是会话推荐
会话:是在一个事件(例如,事务)中或在某一时间段内收集或使用的一组项(例如,指任何对象,例如,产品、歌曲或电影),或在一个时间段(例如,一小时)内发生的一组动作或事件(例如,听一首歌)。 例如,在一个事务中购买的一组项目和用户在一小时内收听的歌曲列表都可以被视为会话。此外,用户在一小时内连续单击的网页也可以被视为会话。
会话推荐( Session-based recommendation ):是指只利用用户在最近一段时期(会话)内的交互物品序列去预测用户下一个可能交互的物品,会话内的交互物品序列可准确捕捉用户的短期偏好,对于当前时间点的推荐具有重要意义。

会话推荐分为会话内推荐和会话间推荐。前者主要对会话内的依赖关系建模,来推荐会话中的未知的下一个或多个项目,后者主要对会话间依赖关系建模(有时也包括会话内依赖关系)来推荐下一个会话中可能出现的项目。
详细的会话推荐讲解:(15条消息) 【论文阅读】会话推荐系统综述 A Survey on Session-based Recommender Systems_-猫耳朵-的博客-CSDN博客_会话推荐系统
2.1 摘要:
此论文将循环神经网络 (RNN) 应用于一个新领域,即推荐系统。现实生活中的推荐系统经常面临只能基于短会话数据(例如小型运动用品网站)而不是长用户历史(例如 Netflix)的问题。在只有短会话数据的情况下,经常被称赞的矩阵分解方法并不准确。
论文采用对会话进行建模,提出了一种基于RNN的方法(GRU4REC模型),考虑到推荐系统的实际任务,对经典的RNN进行了改进,使其更适用于这个特定问题。设计了适配于该推荐任务的ranking loss function(BPR和TOP1),两个数据集( RecSys Challenge 2015和 Youtube 的 OTT)的实验结果表明,与广泛使用的方法相比有显着改进。
2.2 背景介绍:
在特殊场景下我们得不到用户信息
在一些特殊的场景下,我们无法得到过多的user信息,许多电子商务推荐系统(尤其是小型零售商的推荐系统)以及大多数新闻和媒体网站通常不会跟踪长时间访问其网站的用户的用户ID。并且在某些领域(例如分类网站)中,用户的行为通常表现出基于会话的特征。因此,应独立处理同一用户的后续会话。
传统推荐系统存在的不足
它们只关注用户的长期静态偏好,而忽略了用户的短期事务模式,这会导致用户的偏好随时间的推移而丢失。在这种情况下,用户在某个时间点的意图可能很容易被其历史购物行为淹没,从而导致不可靠的推荐。 把一个会话数据分解成立许多个独立的项目,没有挖掘到在同一个会话里面项目的关系。
一些基于会话的推荐方法存在不足
大多数基于会话的推荐系统往往采用简单的方法,例如item-to-item similarity(物品间相似性),co-occurrence, or transition probabilities(共现或概率转移)。这些方法虽然不使用用户信息,而且有效,但这些方法通常只考虑用户的最后一次点击或选择,而忽略过去点击的信息。
问题总结:对于缺少user-items矩阵的情况下,矩阵分解法(如LFM)不可用,常用基于领域的方法解决,然而基于领域的方法一般只会考虑session最后一个event(如user的最后一次点击),忽略了前缀的session 。
推荐系统常见的方法 推荐系统中最常用的方法是FM(因子模型)和neighborhood methods(邻域方法),由于缺少用户因子模型,因此很难在基于会话的推荐中应用。依赖于计算项目(或用户)之间相似性的邻域方法基于会话(或用户配置文件)中项目的共现。邻域方法已广泛用于基于会话的推荐中。 RNN对于推荐系统的引入 在过去的几年中,深度神经网络在图像和语音识别等许多任务中取得了巨大成功顺序数据建模最近也引起了很多关注,各种风格的 RNN 是此类数据的首选模型。序列建模的应用范围从测试翻译到对话建模再到图像字幕,虽然 RNN 已应用于上述领域并取得了显著成功,但很少有人关注推荐系统领域。此论文 RNN 可以应用于基于会话的推荐并取得显着效果,此论文解决了在建模此类稀疏序列数据时出现的问题,并通过引入适合的新排名损失函数使 RNN 模型适应推荐设置训练这些模型的任务。 在基于会话的推荐中,我们可以将用户在进入网站时单击的第一个项目作为 RNN 的初始输入,然后我们希望根据该初始输入查询模型以进行推荐。然后,用户的每次连续点击都会产生一个输出(推荐),该输出取决于所有先前的击。
三 GRU
RNN神经网络已被设计为对可变长度序列数据进行建模。 RNN 与传统前馈深度模型的主要区别在于组成网络的单元中存在内部隐藏状态。我们常用的是GRU神络。
什么是GRU神经网络:
GRU(Gate Recurrent Unit)是循环神经网络(Recurrent Neural Network, RNN)的一种。和LSTM(Long-Short Term Memory)一样,也是为了解决长期记忆和反向传播中的梯度等问题而提出来的,实验中选择GRU是因为它的实验效果与LSTM相似,但是更易于计算。
GRU的输入输出结构:(这里借鉴知乎里面讲解的图和公式)
GRU的输入输出结构与普通的RNN是一样的。
有一个当前的输入 Xt ,和上一个节点传递下来的隐状态Ht-1(hidden state),这个隐状态包含了之前节点的相关信息,结合 Xt 和Ht-1,GRU会得到当前隐藏节点的输出 Yt和传递给下一个节点的隐状态 Ht。
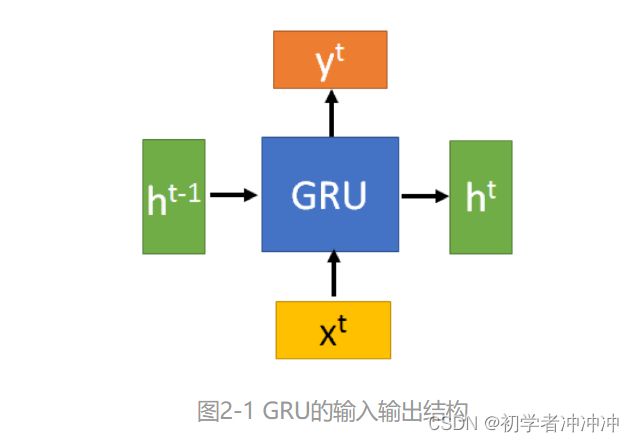
GRU内部构造:
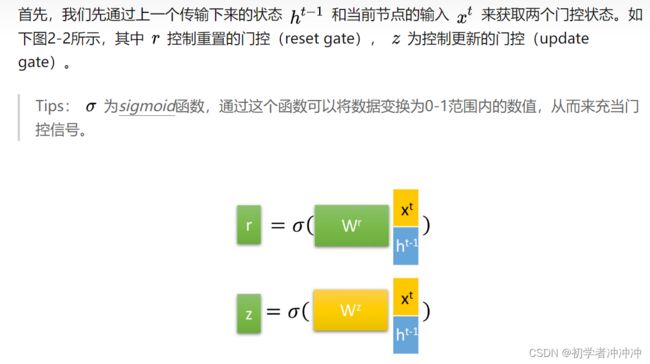
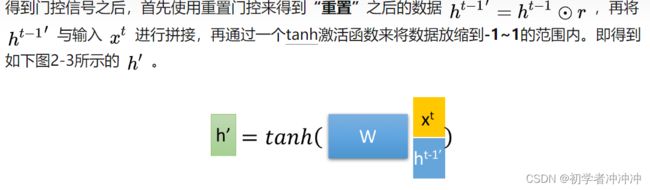


详细的GRU模型讲解链接:人人都能看懂的GRU - 知乎 (zhihu.com)
四 GRU4REC框架

模型的结构很简单,对于一个Session中的点击序列x=[x1,x2,x3...xr-1,xr],依次将x1、x2,...,xr-1输入到模型中,预测下一个被点击的是哪一个Item。首先,序列中的每一个物品xt被转换为one-hot,随后转换成其对应的embedding,经过N层GRU单元后,经过一个全联接层得到下一次每个物品被点击的概率。
模型输入: session 中的点击序列, x=[x1,x2,x3...xr-1,xr] , 1 ≤ r < n,通过one hot encoding 编码,通过embedding层压缩为低维连续向量作为 GRU 的输入。 模型输出:每一个item 被点击的预测概率,Y =M(x),Y=[y1,y2,y3...yi-1,yr] M: 模型函数。yi 是item i 的预测点击概率。
五 提升训练的策略
5.1 SESSION-PARALLEL MINI-BATCHES(会话并行小批量)

Session-parallel mini-batch creation
在序列问题中,RNN如果使用batch进行加速的话,就必然统一其长度,常见的策略是按照长度排序,长度相似时padding会相对比较少。另一个策略是对长序列进行截断或者剪裁成相对比较短的序列。然而这两种策略对于session推荐任务并不合适,因为由于长尾分布,长的序列和短的序列之间差异极大。 作者这里用的策略是将不同的Session给拼接了起来,在同一个序列中如果遇到下一次Session时,会将GRU中的向量参数给重新初始化掉,因为这边GRU是对Step进行预测,所以在序列中间直接初始化掉问题也不大,这样还可以提升数据的利用率,会比简单PADDING的方式更加的合适。
5.2 SAMPLING ON THE OUTPUT(对输出进行采样)
作者提出一个假设,未交互的项目更有可能代表用户不喜欢
未交互的项目常见解释是用户不知道该项目的存在,因此没有交互。然而,用户确实知道该项目并选择不进行交互的可能性很小,因为她不喜欢该项目。项目越受欢迎,用户就越有可能知道它,因此缺失事件更有可能表示不喜欢。
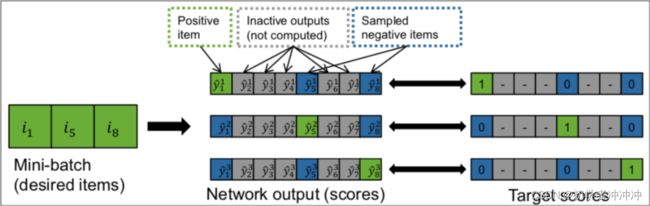
GRU4Rec是一个多分类的模型,最后softmax的时候需要计算所有的item,这样处理速度会非常慢,论文中进行了负采样,负样本没有全局随机挑选,而是选取了在同batch中不同的session的item。为什么这样处理呢?第一个好处是减少计算量,能加速训练,第二个就是我们默认batch中的item流行度会比全局随机挑选好点,这样用户更有可能看过但是没有去点击,说明用户不喜欢,更能刻画用户喜好。
六 排名损失(RANKING LOSS)
推荐系统的核心是项目的基于相关性的排名。排序学习的模型通常分为单点法(Pointwise Approach)、配对法(Pairwise Approach)和列表法(Listwise Approach)三大类,
逐点排名(Pointwise)方法是通过近似为回归问题解决排序问题,将每个查询-文档对的相关性得分作为实数分数或者序数分数,训练排序模型。预测时候对于指定输入,给出查询-文档对的相关性得分。 成对排名(Pairwise)方法是通过近似为分类问题解决排序问题,输入的单条样本为标签-文档对。对于一次查询的多个结果文档,组合任意两个文档形成文档对作为输入样本。即学习一个二分类器,对输入的一对文档对AB(Pairwise的由来),根据A相关性是否比B好,二分类器给出分类标签1或0。对所有文档对进行分类,就可以得到一组偏序关系,从而构造文档全集的排序关系。
列表排序(Listwise方法)是直接优化排序列表,输入为单条样本为一个文档排列。通过构造合适的度量函数衡量当前文档排序和最优排序差值,优化度量函数得到排序模型。

对于几种排名方法的详细讲解:(15条消息) 【推荐】pairwise、pointwise 、 listwise算法是什么?怎么理解?主要区别是什么?_凝眸伏笔的博客-CSDN博客_listwise 此论文解决方案中包含了几个逐点和成对的排名损失。作者发现该网络的逐点排序不稳定(另一方面,成对排名损失表现良好。本文使用Pairwise ranking,即比较正样本和负样本的得分或排名,并确保正样本的loss要低于负样本。 本文使用了两种基于Pairwise ranking的loss function:


七 实验部分
7.1数据集
第一个数据集是 RecSys Challenge 2015 的数据集。该数据集包含有时以购买事件结束的电子商务网站的点击流。(在kaggle上可以找到RecSys Challenge 2015 | Kaggle)
训练集包括两个部分:yoochoose-clicks.dat 和yoochoose-buys.dat
yoochoose-clicks.dat包括:Session ID(会话名称) Timestamp(时间戳) Item ID(项目名称) Category(种类)
yoochoose-buys.dat包括: Session ID(会话名称) Timestamp(时间戳) Item ID(项目名称)Price(价格) Quantity (买的人数)
第二个数据集是从类似 Youtube 的 OTT 视频服务平台收集的。
7.2 评价指标
通过逐步检查session的下一个event的item排名来评估,利用两个指标:recall@20和MRR
召回率(Recall)是推荐系统在召回阶段常用的评价指标。在其他领域我们也经常会看到Recall作为评价指标,其含义为在正样本中有多少被预测为真。那么在推荐系统中,我们通常可以通过。其中u为用户,R(u)为模型预测出的需要推荐的item的集合,T(u)表示真实的测试集中被推荐的集合。对每一个用户求得recall后求平均就可以得到整个数据集上的recall。
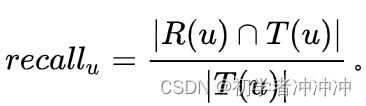
平均倒数排名(Mean Reciprocal Rank,MRR),意义:关心找到的这些项目,是否放在用户更显眼的位置里,即强调"顺序性"。N:用户的总数量,pi:第i个用户的真实访问值在推荐列表的位置,若推荐列表不存在该值,则pi→∞。
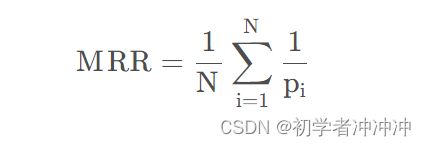
7.3 baselines(有些疑问)
- POP:推荐训练集中最受欢迎的item;
- S-POP:推荐当前session中最受欢迎的item;
- Item-KNN:推荐与实际item相似的item,相似度被定义为session向量之间的余弦相似度
- BPR-MF:一种矩阵分解法,新会话的特征向量为其内的item的特征向量的平均,把它作为用户特征向量。

Recall@20 和 MRR@20 使用基线方法

数据集/损失函数的最佳参数化
Cross-entropy: 实际上是 目标概率向量和预测概率向量的比较。 Dropout:没有添加Dropout的网络是需要对网络的每一个节点进行学习的,而添加了Dropout之后的网络层只需要对该层中没有被Mask掉的节点进行训练,Dropout能够有效缓解模型的过拟合问题,从而使得训练更深更宽的网络成为可能。 Momentum ?
7.4 参数和结构优化

与最佳基线(item-KNN)相比,不同类型的单层 GRU 的 Recall@20 和 MRR@20。突出显示每个数据集的最佳结果。
八 总结
- 多layer不一定好,单层效果反而更好。
- GRU比传统RNN和LSTM效果要好。
- 基于点排序的损失通常是不稳定的,基于成对排名的损失表现良好。
- one-hot编码效果更好。