Paddle开发深度学习模型快速入门
Paddle开发深度学习模型快速入门
一、常见问题汇总
1.训练集(train),验证集(validation),测试集(test)
训练集(train set):用于训练模型以及确定参数。相当于老师教学生知识的过程。
验证集(validation set):用于确定网络结构以及调整模型的超参数。相当于月考等小测验
测试集(test set):用于检验模型的泛化能力。相当于大考
2.numpy.squeeze
numpy.squeeze(a,[axis]= None)
从数组的形状中删除某个维度。(axis为几时,可以看做此维度消失,删除后的形状便可得知)

3.iloc[]函数
iloc[]函数,属于pandas库,全称为index location,即对数据进行位置索引,从而在数据表中提取出相应的数据。
4.nn.Embedding
参考链接:https://www.jianshu.com/p/63e7acc5e890
5.rank()
rank(method='first', ascending=False)
-
method=‘average’ (默认设置):那么这两个人就占据了前两名,分不出谁第 1,谁第 2,就把两人的名次算个平均数,都算 1.5 名,这样下一个人就是第3名。
-
method=‘max’:两人并列第 2 名,下一个人是第 3 名。
-
method=‘min’:两人并列第 1 名,下一个人是第 3 名。
-
method=‘dense’:两人并列第 1 名,但下一个人是第 2 名。
-
method=‘first’:那么试卷先被改出来的人是第 1 名,试卷后被改出来的是第 2 名。
ascending
ascending=False表示降序
参考链接:https://blog.csdn.net/Matrix_cc/article/details/123194080
group by 参考链接:https://zhuanlan.zhihu.com/p/101284491(未看)
5.pandas 内置函数(仅列举论教程中出现的)
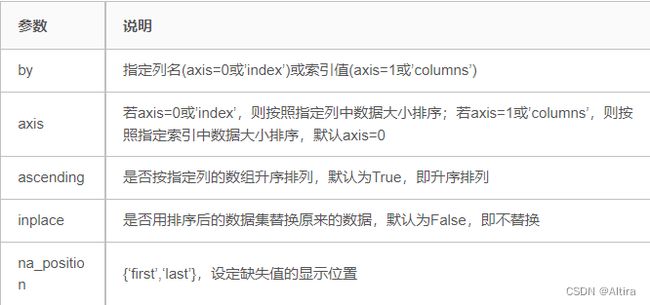
1.sort_values()

by={‘col1’,‘col2’} :by带两个参数,表示先按’col1’进行排序,相同的再按‘col2’排序。
2.resert_index
重新设置索引
https://blog.csdn.net/weixin_43298886/article/details/108090189
3.pandas获取符合条件数据
df = pd.read_csv(config['valid_path'])
df[df['user_id']==110120]
4.apply()
andas 的 apply() 函数可以作用于 Series 或者整个 DataFrame,功能也是自动遍历整个 Series 或者 DataFrame, 对每一个元素运行指定的函数。
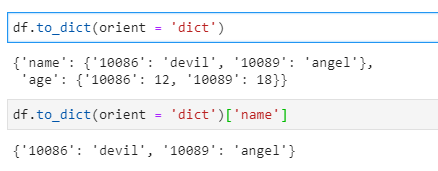
5.to_dict()
DataFrame.to_dict(self,orient = 'dict',into = )
将数据转化为字典类型(默认),也可以转化为其他类型(‘list’,‘series’,‘split’,‘records’,‘index’)
df.to_dict(orient = 'dict')
df.to_dict(orient = 'dict')['name']
https://blog.csdn.net/qq_38060702/article/details/109843385
6.defaultdict()
当key不存在时,返回的是工厂函数的默认值,比如list对应[ ],str对应的是空字符串,set对应set( ),int对应0。
from collections import defaultdict
dict1 = defaultdict(int)
dict2 = defaultdict(set)
dict3 = defaultdict(str)
dict4 = defaultdict(list)
dict1[2] ='two'
print(dict1[1])
print(dict2[1])
print(dict3[1])
print(dict4[1])
0
set()
[]
7.tqdm()
tqdm是 Python 进度条库,可以在 Python长循环中添加一个进度提示信息。用户只需要封装任意的迭代器,是一个快速、扩展性强的进度条工具库。
8.squeeze()
numpy中的squeeze(a,axis=None) 直接压缩掉所选中的维度
课程链接:https://aistudio.baidu.com/aistudio/education/group/info/27783