关于深度学习下目标检测入门那点事
关于深度学习下目标检测入门那点事
- 你需要知道的学前班知识
-
- 边界框(Bounding Box)
- 交并比(IOU)
- 非极大值抑制(NMS)
- 评价参数
-
- 精确率(Precision)
- 召回率(Recall)
- P-R(Precision-Recall )曲线
- AP(Average Precision)与mAP(mean Average Precision)
- 准确率(Accuracy)
- 什么是目标检测?
-
- 图像分类与目标检测
- 检测网络结构
- 检测网络发展史
- 单阶段与两阶段网络
- Anchor
- 如何学习一个新的检测网络?
(本博客创建目的源于实验室小组内部方便知识传承学习,但当然不会吝啬于私密不公开,但有些文字段落会是写给小组内看的,如有疑问麻烦跳过即可,同时也欢迎各位本硕博报考西安电子科技大学人工智能学院。)
首先,如果你看到这篇博客,恭喜你,大概率你已经加入并成为了我们实验室的一员,预祝你往后的科研生活丰富且逸趣横生。
一个好的实验室科研氛围需要所有人一起努力,虽然说写博客会耗费一些额外的时间,但为了更好地传承、方便学习新的知识,我们开通了这个CSDN账号,而这也是我们的第一篇博客,同时希望这个工作能够一直坚持下去,往后还要依靠诸位,提前谢过。
写自2020/12/10 2020级要泉赫
你需要知道的学前班知识
如果你对目标检测已经了然于胸,那这篇博客建议直接跳过。
如果你对目标检测的基础知识了如指掌,那First Part建议直接跳过。
如果你对深度学习网络一点都不了解,那这篇博客也建议先跳过。
边界框(Bounding Box)
顾名思义,如果你看过一些目标检测后的结果,你肯定会看到物体周围都会围有一个小框,这便是最终得到的检测(Detection Result)框。当然,除了检测框之外,还有真值(Ground Truth)框与预测(Predicted)框,这三种框本质上都可以被称为Bounding Box(简称bbox),因为它都是为了表示物体位置信息而生成的边界框。首先,每个目标都会有一个表示它准确位置信息的真值框,之后我们的网络在训练过程中会根据真值框等信息进行学习从而生成无数的预测框,最后,网络会层层筛选计算输出最终的结果——检测框。
通常情况下,我们会将真值框直接称为Ground Truth(简称GT),将经过网络预测所得出的边界框(即Pred BBox)称之为BBox,最终的检测结果框称为Detection Result(简称DT)。如下图中,绿色的框即为GT BBox,红色的框则Pred BBox(图源网络)。

交并比(IOU)
在明确了BBox的概念之后,IOU便很好理解了,它其实就是一个用来筛选预测BBox衡量指标,话不多说,直接上图(图源网络)。
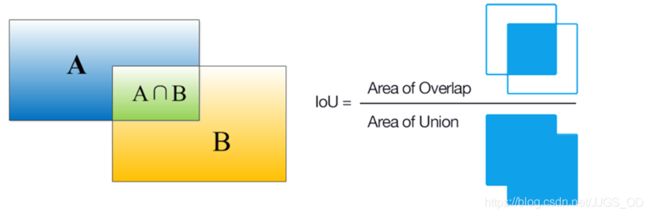
简单点说,就是GT BBox与Pred BBox交集的面积 / 二者并集的面积,这个要是再不清楚就真的过分了啊。
非极大值抑制(NMS)
在学习目标检测初期时候,我个人觉得这个概念相比于前面肯定还是有那么一点拗口的,不过理解了之后你会发现其实也就soso,它其实就是筛选我们预测框的一个方法。
这里我不打算再自己讲述一遍了,因为博客的初衷也只是分享自己学习过程中的资料与心得,既然可以直接站在巨人的肩膀上,又何苦自己耗时耗力重新写一遍呢是吧,前人栽树后人乘凉嘛。
NMS概念
关于NMS解释详细的博客有很多,我这里粘贴其中一篇的地址在这里,如果还有问题欢迎私聊我。
评价参数
终于来到我们的重头戏了,这一部分绝对可以算是我们学前班的毕业考试级别了,看懂不是最重要的,记住才是最重要的。像我就经常会被梁师兄提问,然后回答得磕磕绊绊记不清,还得你们惠师兄救场,哎,没办法,谁让我这么菜呢,可千万别像我学习啊。
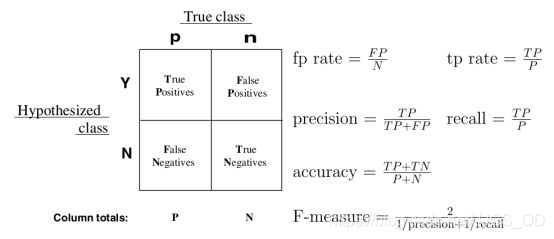
在学习评价参数指标之前,你需要先知道——
| 标签 | 正例 (预测) | 负例(预测) |
|---|---|---|
| 正例(真实) | TP | FN |
| 负例(真实) | FP | TN |
记忆的话其实很简单,第一个字母表示检测正确与否,第二个字母表示预测目标结果为正样本还是负样本,然后进行排列组合就好,简单解释一下便是这样(正样本飞机,负样本大雁):
TP:正样本被正确识别为正样本(飞机的图片被正确的识别成了飞机)
TN:负样本被正确识别为负样本(大雁的图片没有被识别出来,系统正确地认为它们是大雁)
FP:负样本被错误识别为正样本(大雁的图片被错误地识别成了飞机)
FN:正样本被错误识别为负样本(飞机的图片没有被识别出来,系统错误地认为它们是大雁)
在了解了TP、FP、TN、FN之后,我们便可以开始学习下面的参数含义了。
精确率(Precision)
Precision = TP/(TP+FP)
即识别出的正例目标中,包含识别正确的样本所占的比例。
该怎么记忆呢?你可以这样理解,精确精确,什么是精确,精确首先得是结果判断为正确的,所以精确统计的就只是属于识别结果为正样本的那一部分,但凡我们识别结果为负样本的全部不管,这样就能和后面的准确率区分开了。
或者还有一种理解方式,就是我们最后的指标是要统计错检,这个便是我们的精确率,在检出的所有结果中看看有多少是正确的,那么计算方式便显而易见了。
召回率(Recall)
Recall = TP/(TP+FN)
即识别正确的正例目标占真实所有正例目标的比例。
这个又该怎么记忆呢?召回召回,什么叫召回,就是指原本为正样本的数据有多少被我们正确检测出来的,看看有多少真实目标被我们漏检了的,这便是召回率。
P-R(Precision-Recall )曲线
P-R曲线顾名思义,是由Precision和Recal绘制的曲线,反应的是Precision和Recal之间的关系,我们通过改变识别阈值,使得系统依次能够识别前K张图片,阈值的变化同时会导致Precision与Recall值发生变化,从而得到不同多组的Precision与Recall值,从而绘制出曲线。
用以下检测结果数据举个例子(图源网络):
比如阈值0.9,只有第一个样本被我判断为正例,那么我的Precision就是100%,但是Recall就是10%。阈值0.1,所有样本都被我判断为正例,Recall是100%,Precision就是50%,多次更改阈值之后,我们便可以将得到的Precision与Recall值绘制成下图(图源网络)。

如果一个分类器的性能比较好,那么它应该有如下的表现:在Recall值增长的同时,Precision的值保持在一个很高的水平。而性能比较差的分类器可能会损失很多Precision值才能换来Recall值的提高。通常情况下,文章中都会使用Precision-recall曲线,来显示出分类器在Precision与Recall之间的权衡。
AP(Average Precision)与mAP(mean Average Precision)
AP即某一类别全部图像中的平均精确度,这样说其实很空,所以需要一个准确的计算方式,那就是Precision-recall 曲线下面的面积,通常来说一个越好的分类器,AP值越高。
mAP是对全部类别求平均AP值。其实就加和然后除以类别总数,得到的就是mAP的值,是不是很简单。mAP的大小一定在[0,1]区间,越大越好。同时该指标是目标检测算法中最重要的一个。
一般情况下,单一目标我们会用到AP指标,多个目标时我们会用到mAP指标。
准确率(Accuracy)
Accuracy = (TP+TN)/ALL
即分对的样本数除以所有的样本数 。
准确率一般用来评估模型的全局准确程度,不能包含太多信息,无法全面评价一个模型性能。
最后,放一张总结的图在这里(图源网络)
什么是目标检测?
目标检测有多容易,谁看谁知道。
—— 鲁迅
图像分类与目标检测
按照我学习深度学习的过程,一开始接触的便是分类网络,所以再介绍检测网络之前,我觉得如果和分类网络做一个比较能够好的帮助大家理解。
其实,分类的原理是输入一张图片,经过其中卷积、激活、池化等相关层,最后加入全连接层达到分类概率的效果,而对于目标检测来说就不仅仅是分类这样简单的一个图片输出一个结果,而且还需要输出图片中目标的位置信息。
说白了,目标检测就是不仅要知道目标是什么,还要通过设计网络找到目标在哪。
所以,分类网络一定是目标检测不可或缺的一部分,我们通常也将目标检测网络中分类网络的部分称之为骨干网络(Backbone),下面这张图更好的说明了从分类到检测的递进关系(图源网络)。
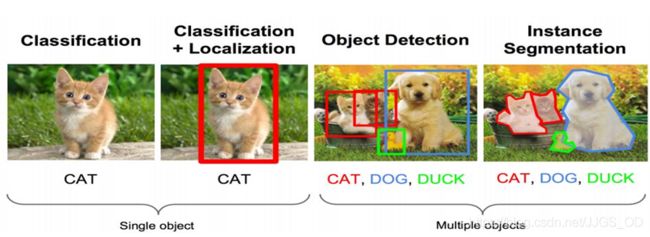 相比于图像分类网络,目标检测网络的输出是非结构化的。也就是说,它的输出具有很强的不确定性。举个例子,图像分类任务的输入也是一张图像,输出为一个标签/类别,代表着这张图的分类,因此分类任务的输出是结构化的,有且仅有一个标签;而目标检测的输出是图像中的所有目标(类别+位置),图像中到底有多少个目标是不确定的。这一特点非常重要,也正因为这一特点,目标检测的性能度量方法要比图像分类任务复杂得多。
相比于图像分类网络,目标检测网络的输出是非结构化的。也就是说,它的输出具有很强的不确定性。举个例子,图像分类任务的输入也是一张图像,输出为一个标签/类别,代表着这张图的分类,因此分类任务的输出是结构化的,有且仅有一个标签;而目标检测的输出是图像中的所有目标(类别+位置),图像中到底有多少个目标是不确定的。这一特点非常重要,也正因为这一特点,目标检测的性能度量方法要比图像分类任务复杂得多。
检测网络结构
通常来说,一个目标检测网络都可以被分为三个部分,
Detector = Backbone + Neck + Head
Backbone:上文已经提过,负责从图像中提取出些必要的特征信息。
Neck:接在Backbone后面,负责更好地融合/提取Backbone所给出的Feature,从而提高网络的性能。
Head:其余后续的网络负责从这些特征中检测目标的位置和类别。
这里你只需要有这个概念就可以了,以后见多了便熟悉了。
检测网络发展史
其中红色标注的为极其经典的网络(图源论文:《Deep Learning for Generic Object Dection:A Survey》),系统学习时候建议按照先按照这个顺序,环环相扣总比东拼西凑好一些。

单阶段与两阶段网络
| 单阶段网络 | 两阶段网络 |
|---|---|
| 速度快,精度低 | 速度慢,精度高 |
Two-stage网络的第一个stage相当于先拿一个One-stage网络来做一次前景后景(目标与背景)的Classification + detection,这一过程被称为候选区域网络(Region Proposals Network)。这样做的好处有可以选择性的挑选样本使得正负样本更加均衡,然后再对候选区域分类和其位置精修。
One-stage网络则是用其他代替了Region Proposal阶段,直接产生物体的类别概率和位置坐标值,经过单次检测即可直接得到最终的检测结果,因此有着更快的检测速度,但面临着正负样本不均衡与精度不高等问题。
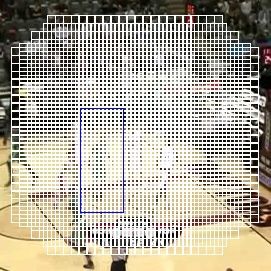
Anchor
在学习目标检测网络过程中你一定不会对这个词陌生,那么它究竟是什么,它到底是怎么样生成的,它到底是个点还是个框?我找到一篇很好的讲解放在这里。
Anchor的概念
同时非常感谢惠师兄制作的一张Anchor可视化图。
如何学习一个新的检测网络?
对于我这样一个初学者来说,其实这个问题真的琢磨了很久,因为一开始的时候会觉得直接看英语原版论文更加生涩难懂,所以会在CSDN或者某乎上看别人总结好的中文讲解,可是很多人的总结都是左一榔头右一棒槌,导致一开始学习走了不少的弯路。后来慢慢的我总结了一条学习思路,可当我直接看原论文学习时候发现其实论文就是按照这条思路讲解的……可能你们不会和我一样蠢,但我还是先写下来防患于未然。同时,其他师兄们可能还有他们的独家学习秘诀,之后我也会让他们补充在这里,作为这一篇博客最后的部分,希望能有助于你的目标检测开启之路事半功倍。
一般来说,学一个目标检测网络分为以下三个步骤,
第一步:看网络结构
第二步:看检测过程
第三步:看训练方法
了解一个网络结构能够更好地知道模块直接的关联,再根据每一个模块的作用去学习网络的检测过程,这便是一篇论文的主要思想,知道了这些之后再去学习网络的训练方法,例如网络的损失函数,对正负样本的处理等等,最后,作者通常会列出他的实验过程,以及与其他网络的性能对比,可以更好的帮你复现网络与深入了解其他网络。
好了,关于深度学习目标检测网络的基础知识到这里就差不多结束了,如果还有遗漏或错误的地方,欢迎提醒以便我后期修改,或者你们直接登录这个账号修改就好,有什么问题或建议也可以直接和我说,我是鸽子王,下一次不一定什么时候再见。