动手学深度学习(十七)——CNN基础知识
文章目录
-
- 1、从全连接层到卷积
-
- 1.1 限制多层感知机
- 1.2 平移不变性
- 1.3 局部性
- 1.4 卷积定义
- 2、图像卷积
-
- 2.1 卷积层
-
- 2.1.1简单应用:检测图片中不同颜色的边缘
- 2.2 卷积核
- 2.3 互相关和卷积
- 2.4 特征映射和感受野
- 2.5 填充和步幅
-
- 2.5.1 填充
- 2.5.2 步幅
- 2.6 多输入多输出通道
-
- 2.6.1 多输入通道
- 2.6.2 多输出通道
- 2.7 1 X 1卷积
- 3、参考:
1、从全连接层到卷积
1.1 限制多层感知机
首先,假设以二维图像 X \mathbf{X} X 作为输入,那么我们多层感知机的隐藏表示 H \mathbf{H} H 在数学上是一个矩阵,在代码中表示为二维张量。
其中 X \mathbf{X} X 和 H \mathbf{H} H 具有相同的形状。
我们可以认为,不仅输入有空间结构,隐藏表示也应该有空间结构。
我们用 [ X ] i , j [\mathbf{X}]_{i, j} [X]i,j 和 [ H ] i , j [\mathbf{H}]_{i, j} [H]i,j 分别表示输入图像和隐藏表示中位置( i i i, j j j)处的像素。
为了使每个隐藏神经元都接收到每个输入像素的信息,我们将参数从权重矩阵(如同我们先前在多层感知机中所做的那样)替换为四阶权重张量 W \mathsf{W} W。假设 U \mathbf{U} U 包含偏置参数,我们可以将全连接层表示为
[ H ] i , j = [ U ] i , j + ∑ k ∑ l [ W ] i , j , k , l [ X ] k , l = [ U ] i , j + ∑ a ∑ b [ V ] i , j , a , b [ X ] i + a , j + b . \begin{aligned} \left[\mathbf{H}\right]_{i, j} &= [\mathbf{U}]_{i, j} + \sum_k \sum_l[\mathsf{W}]_{i, j, k, l} [\mathbf{X}]_{k, l}\\ &= [\mathbf{U}]_{i, j} + \sum_a \sum_b [\mathsf{V}]_{i, j, a, b} [\mathbf{X}]_{i+a, j+b}.\end{aligned} [H]i,j=[U]i,j+k∑l∑[W]i,j,k,l[X]k,l=[U]i,j+a∑b∑[V]i,j,a,b[X]i+a,j+b.
其中,从 W \mathsf{W} W 到 V \mathsf{V} V 的转换只是形式的转换,因为在两个四阶张量中,系数之间存在一一对应的关系。
我们只需重新索引下标 ( k , l ) (k, l) (k,l),使 k = i + a k = i+a k=i+a、 l = j + b l = j+b l=j+b, 由此 [ V ] i , j , a , b = [ W ] i , j , i + a , j + b [\mathsf{V}]_{i, j, a, b} = [\mathsf{W}]_{i, j, i+a, j+b} [V]i,j,a,b=[W]i,j,i+a,j+b。
这里的索引 a a a 和 b b b 覆盖了正偏移和负偏移。
对于隐藏表示中任意给定位置( i i i, j j j)处的像素值 [ H ] i , j [\mathbf{H}]_{i, j} [H]i,j,我们可以通过对 x x x 中以 ( i , j ) (i, j) (i,j) 为中心的像素进行加权求和得到,权重为 [ V ] i , j , a , b [\mathsf{V}]_{i, j, a, b} [V]i,j,a,b 。
1.2 平移不变性
同一层中卷积核不发生变化。
这意味着在输入 X \mathbf{X} X 中的移位,应该仅与隐藏表示 H \mathbf{H} H 中的移位相关。也就是说, V \mathsf{V} V 和 U \mathbf{U} U 实际上不依赖于 ( i , j ) (i, j) (i,j) 的值,即 [ V ] i , j , a , b = [ V ] a , b [\mathsf{V}]_{i, j, a, b} = [\mathbf{V}]_{a, b} [V]i,j,a,b=[V]a,b。并且 U \mathbf{U} U 是一个常数,比如 u u u。因此,我们可以简化 H \mathbf{H} H 定义为:
[ H ] i , j = u + ∑ a ∑ b [ V ] a , b [ X ] i + a , j + b . [\mathbf{H}]_{i, j} = u + \sum_a\sum_b [\mathbf{V}]_{a, b} [\mathbf{X}]_{i+a, j+b}. [H]i,j=u+a∑b∑[V]a,b[X]i+a,j+b.
这就是 卷积 (convolution)。实际上,我们是在使用系数 [ V ] a , b [\mathbf{V}]_{a, b} [V]a,b 对位置 ( i , j ) (i, j) (i,j) 附近的像素 ( i + a , j + b ) (i+a, j+b) (i+a,j+b) 进行加权求和(并加一偏置 u u u)来得到 [ H ] i , j [\mathbf{H}]_{i, j} [H]i,j。
注意, [ V ] a , b [\mathbf{V}]_{a, b} [V]a,b 的参数比 [ V ] i , j , a , b [\mathsf{V}]_{i, j, a, b} [V]i,j,a,b 少很多,因为前者不再依赖于图像中的位置。
1.3 局部性
将一张图/体积 拆分成小元来进行计算,每次只看中心附近的信息
现在引用上述的第二个原则:局部性。如上所述,为了收集用来训练参数 [ H ] i , j [\mathbf{H}]_{i, j} [H]i,j 的相关信息,我们不应偏离到距 ( i , j ) (i, j) (i,j) 很远的地方。这意味着在 ∣ a ∣ > Δ |a|> \Delta ∣a∣>Δ 或 ∣ b ∣ > Δ |b| > \Delta ∣b∣>Δ 的范围之外,我们可以设置 [ V ] a , b = 0 [\mathbf{V}]_{a, b} = 0 [V]a,b=0。由此,我们可以将参数 [ H ] i , j [\mathbf{H}]_{i, j} [H]i,j 重写为
[ H ] i , j = u + ∑ a = − Δ Δ ∑ b = − Δ Δ [ V ] a , b [ X ] i + a , j + b . [\mathbf{H}]_{i, j} = u + \sum_{a = -\Delta}^{\Delta} \sum_{b = -\Delta}^{\Delta} [\mathbf{V}]_{a, b} [\mathbf{X}]_{i+a, j+b}. [H]i,j=u+a=−Δ∑Δb=−Δ∑Δ[V]a,b[X]i+a,j+b.
简而言之, 这是一个 卷积层 (convolutional layer),而卷积神经网络是包含卷积层的一类特殊的神经网络。
在深度学习研究社区中, V \mathbf{V} V 被称为 卷积核 (convolution kernel) 或者 滤波器 (filter),是可学习的权重。
当图像处理的局部区域很小时,卷积神经网络与多层感知机的训练差异可能是巨大的:以前,多层感知机可能需要数十亿个参数来表示,而现在卷积神经网络通常只需要几百个参数,而且不需要改变输入或隐藏表示的维数。
参数量的这一减少所付出的代价就是,我们的特征现在必须是平移不变的,且每一层只能包含局部的信息。
以上所有的权重学习都依赖于归纳偏置,当这种偏置与实际情况相符时,我们就可以得到有效的模型,这些模型能很好地推广到不可见的数据中。
但如果这些假设与实际情况不符,比如当图像不满足平移不变时,我们的模型可能难以拟合。
1.4 卷积定义
在数学中,两个函数(比如 f , g : R d → R f, g: \mathbb{R}^d \to \mathbb{R} f,g:Rd→R)之间的卷积被定义为
( f ∗ g ) ( x ) = ∫ f ( z ) g ( x − z ) d z . (f * g)(\mathbf{x}) = \int f(\mathbf{z}) g(\mathbf{x}-\mathbf{z}) d\mathbf{z}. (f∗g)(x)=∫f(z)g(x−z)dz.
也就是说,卷积是测量 f f f 和 g g g 之间(把其中一个函数“翻转”并移位 x \mathbf{x} x 时)的重叠。
当我们有离散对象时(即定义域为 Z \mathbb{Z} Z ),积分就变成求和,我们得到以下定义:
( f ∗ g ) ( i ) = ∑ a f ( a ) g ( i − a ) . (f * g)(i) = \sum_a f(a) g(i-a). (f∗g)(i)=a∑f(a)g(i−a).
对于二维张量,则为 f f f 在 ( a , b ) (a, b) (a,b) 和 g g g 在 ( i − a , j − b ) (i-a, j-b) (i−a,j−b) 上的对应和:
( f ∗ g ) ( i , j ) = ∑ a ∑ b f ( a , b ) g ( i − a , j − b ) . (f * g)(i, j) = \sum_a\sum_b f(a, b) g(i-a, j-b). (f∗g)(i,j)=a∑b∑f(a,b)g(i−a,j−b).
2、图像卷积
如果想看更直观的图像演示请参考:非常全的CNN卷积神经网络整理
严格来说,卷积层是个错误的叫法,因为它所表达的运算其实是 互相关运算 (cross-correlation),而不是卷积运算。(因为之前学过数字信号处理的一些基础知识,下意识将两个卷积等价了,但是其实二者是有一定区别的,这是我个人之前没有注意到的地方)
在卷积层中,输入张量和核张量通过(互相关运算)产生输出张量。
首先,我们暂时忽略通道(第三维)这一情况,看看如何处理二维图像数据和隐藏表示。在下图中,输入是高度为 3 3 3 、宽度为 3 3 3 的二维张量(即形状为 3 × 3 3 \times 3 3×3 )。卷积核的高度和宽度都是 2 2 2 ,而卷积核窗口(或卷积窗口)的形状由内核的高度和宽度决定(即 2 × 2 2 \times 2 2×2 )。
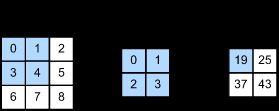
在二维互相关运算中,卷积窗口从输入张量的左上角开始,从左到右、从上到下滑动。
当卷积窗口滑动到新一个位置时,包含在该窗口中的部分张量与卷积核张量进行按元素相乘,得到的张量再求和得到一个单一的标量值,由此我们得出了这一位置的输出张量值。
在如上例子中,输出张量的四个元素由二维互相关运算得到,这个输出高度为 2 2 2 、宽度为 2 2 2 ,如下所示:
0 × 0 + 1 × 1 + 3 × 2 + 4 × 3 = 19 , 1 × 0 + 2 × 1 + 4 × 2 + 5 × 3 = 25 , 3 × 0 + 4 × 1 + 6 × 2 + 7 × 3 = 37 , 4 × 0 + 5 × 1 + 7 × 2 + 8 × 3 = 43. 0\times0+1\times1+3\times2+4\times3=19,\\ 1\times0+2\times1+4\times2+5\times3=25,\\ 3\times0+4\times1+6\times2+7\times3=37,\\ 4\times0+5\times1+7\times2+8\times3=43. 0×0+1×1+3×2+4×3=19,1×0+2×1+4×2+5×3=25,3×0+4×1+6×2+7×3=37,4×0+5×1+7×2+8×3=43.
注意,输出大小略小于输入大小。这是因为卷积核的宽度和高度大于1,
而卷积核只与图像中每个大小完全适合的位置进行互相关运算。
所以,输出大小等于输入大小 n h × n w n_h \times n_w nh×nw 减去卷积核大小 k h × k w k_h \times k_w kh×kw,即:
( n h − k h + 1 ) × ( n w − k w + 1 ) . (n_h-k_h+1) \times (n_w-k_w+1). (nh−kh+1)×(nw−kw+1).
这是因为我们需要足够的空间在图像上“移动”卷积核。稍后,我们将看到如何通过在图像边界周围填充零来保证有足够的空间移动内核,从而保持输出大小不变。
接下来,我们在 corr2d 函数中实现如上过程,该函数接受输入张量 X 和卷积核张量 K ,并返回输出张量 Y 。
import torch
from torch import nn
from d2l import torch as d2l
def corr2d(X,K):
h,w = K.shape
Y = torch.zeros(X.shape[0]-h +1 ,X.shape[1]-w+1)
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i,j] = (X[i:i+h,j:j+w]*K).sum()
return Y
# 验证二维卷积输出
X = torch.tensor([[0.0,1.0,2.0],[3.0,4.0,5.0],[6.0,7.0,8.0]])
K = torch.tensor([[0.0,1.0],[2.0,3.0]])
corr2d(X,K)
tensor([[19., 25.],
[37., 43.]])
2.1 卷积层
卷积层对输入和卷积核权重进行互相关运算,并在添加标量偏置之后产生输出。
所以,卷积层中的两个被训练的参数是卷积核权重和标量偏置。
就像我们之前随机初始化全连接层一样,在训练基于卷积层的模型时,我们也随机初始化卷积核权重。
基于上面定义的 corr2d 函数[实现二维卷积层]。在 __init__ 构造函数中,将 weight 和 bias 声明为两个模型参数。前向传播函数调用 corr2d 函数并添加偏置。
# 实现二维卷积层
class Conv2D(nn.Module):
def __init__(self,kernel_size):
super().__init__()
self.weight = nn.Parameter(torch.rand(kernel_size))
self.bias = nn.Parameter(torch.zeros(1))
def forward(self,x):
return corr2d(x,self.weight)+self.bias
2.1.1简单应用:检测图片中不同颜色的边缘
如下是[卷积层的一个简单应用:]通过找到像素变化的位置,来(检测图像中不同颜色的边缘)。
首先,我们构造一个 6 × 8 6\times 8 6×8 像素的黑白图像。中间四列为黑色( 0 0 0),其余像素为白色( 1 1 1)。
X = torch.ones((6,8))
X[:,2:6] = 0
X
tensor([[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.],
[1., 1., 0., 0., 0., 0., 1., 1.]])
接下来,我们构造一个高度为 1 1 1 、宽度为 2 2 2 的卷积核 K 。当进行互相关运算时,如果水平相邻的两元素相同,则输出为零,否则输出为非零。
K = torch.tensor([[1.0,-1.0]])
现在,我们对参数 X (输入)和 K (卷积核)执行互相关运算。
如下所示,[输出Y中的1代表从白色到黑色的边缘,-1代表从黑色到白色的边缘],其他情况的输出为 0 0 0。
Y = corr2d(X,K)
Y
tensor([[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.],
[ 0., 1., 0., 0., 0., -1., 0.]])
现在我们将输入的二维图像转置,再进行如上的互相关运算。
其输出如下,之前检测到的垂直边缘消失了。
不出所料,这个[卷积核K只可以检测垂直边缘],无法检测水平边缘。
corr2d(X.t(),K)
tensor([[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.]])
2.2 卷积核
如果我们只需寻找黑白边缘,那么以上 [1, -1] 的边缘检测器足以。然而,当有了更复杂数值的卷积核,或者连续的卷积层时,我们不可能手动设计过滤器。那么我们是否可以[学习由X生成Y的卷积核]呢?
现在让我们看看是否可以通过仅查看“输入-输出”对来学习由 X 生成 Y 的卷积核。
我们先构造一个卷积层,并将其卷积核初始化为随机张量。接下来,在每次迭代中,我们比较 Y 与卷积层输出的平方误差,然后计算梯度来更新卷积核。为了简单起见,我们在此使用内置的二维卷积层,并忽略偏置。
conv2d = nn.Conv2d(1,1,kernel_size=(1,2),bias=False)
X = X.reshape(1,1,6,8)
Y = Y.reshape(1,1,6,7)
for i in range(10):
Y_hat = conv2d(X)
l = (Y_hat-Y)**2
conv2d.zero_grad()
l.sum().backward()
conv2d.weight.data[:] -= 3e-2 * conv2d.weight.grad
if (i+1)%2 == 0:
print(f'batch {i+1},loss {l.sum():.3f}')
batch 2,loss 1.492
batch 4,loss 0.251
batch 6,loss 0.043
batch 8,loss 0.007
batch 10,loss 0.001
conv2d.weight.data.reshape((1,2))
tensor([[ 0.9947, -0.9926]])
2.3 互相关和卷积
为了得到严格卷积运算输出,我们需要执行定义的严格卷积运算,而不是互相关运算。
幸运的是,它们差别不大,我们只需水平和垂直翻转二维卷积核张量,然后对输入张量执行互相关运算。
值得注意的是,由于卷积核是从数据中学习到的,因此无论这些层执行严格的卷积运算还是互相关运算,卷积层的输出都不会受到影响。
为了说明这一点,假设卷积层执行互相关运算并学习中的卷积核,该卷积核在这里由矩阵 K \mathbf{K} K 表示。
假设其他条件不变,当这个层执行严格的卷积时,学习的卷积核 K ′ \mathbf{K}' K′ 在水平和垂直翻转之后将与 K \mathbf{K} K 相同。
为了与深度学习文献中的标准术语保持一致,我们将继续把“互相关运算”称为卷积运算,尽管严格地说,它们略有不同。
此外,对于卷积核张量上的权重,我们称其为元素。
2.4 特征映射和感受野
输出的卷积层有时被称为 特征映射 (Feature Map),因为它可以被视为一个输入映射到下一层的空间维度的转换器。
在CNN中,对于某一层的任意元素 x x x ,其 感受野 (Receptive Field)是指在前向传播期间可能影响 x x x 计算的所有元素(来自所有先前层)。
注意,感受野的覆盖率可能大于某层输入的实际区域大小。
给定 2 × 2 2 \times 2 2×2 卷积核,阴影输出元素值 19 19 19 的接收域是输入阴影部分的四个元素。
假设之前输出为 Y \mathbf{Y} Y ,其大小为 2 × 2 2 \times 2 2×2 ,现在我们在其后附加一个卷积层,该卷积层以 Y \mathbf{Y} Y 为输入,输出单个元素 z z z。
在这种情况下, Y \mathbf{Y} Y 上的 z z z 的接收字段包括 Y \mathbf{Y} Y 的所有四个元素,而输入的感受野包括最初所有九个输入元素。
因此,当一个特征图中的任意元素需要检测更广区域的输入特征时,我们可以构建一个更深的网络。
2.5 填充和步幅
在应用多层卷积时,我们常常丢失边缘像素。
由于我们通常使用小卷积核,因此对于任何单个卷积,我们可能只会丢失几个像素。
但随着我们应用许多连续卷积层,累积丢失的像素数就多了。
解决这个问题的简单方法即为填充(padding):在输入图像的边界填充元素(通常填充元素是 0 0 0 )。
例如,将 3 × 3 3 \times 3 3×3 输入填充到 5 × 5 5 \times 5 5×5,那么它的输出就增加为 4 × 4 4 \times 4 4×4。阴影部分是第一个输出元素以及用于输出计算的输入和核张量元素:
0 × 0 + 0 × 1 + 0 × 2 + 0 × 3 = 0 0\times0+0\times1+0\times2+0\times3=0 0×0+0×1+0×2+0×3=0。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IIcVKEaA-1628233284135)(attachment:image.png)]
通常,如果我们添加 p h p_h ph 行填充(大约一半在顶部,一半在底部)和 p w p_w pw 列填充(左侧大约一半,右侧半),则输出形状将为
( n h − k h + p h + 1 ) × ( n w − k w + p w + 1 ) 。 (n_h-k_h+p_h+1)\times(n_w-k_w+p_w+1)。 (nh−kh+ph+1)×(nw−kw+pw+1)。
这意味着输出的高度和宽度将分别增加 p h p_h ph 和 p w p_w pw。
在许多情况下,我们需要设置 p h = k h − 1 p_h=k_h-1 ph=kh−1 和 p w = k w − 1 p_w=k_w-1 pw=kw−1,使输入和输出具有相同的高度和宽度。
这样可以在构建网络时更容易地预测每个图层的输出形状。假设 k h k_h kh 是奇数,我们将在高度的两侧填充 p h / 2 p_h/2 ph/2 行。
如果 k h k_h kh 是偶数,则一种可能性是在输入顶部填充 ⌈ p h / 2 ⌉ \lceil p_h/2\rceil ⌈ph/2⌉ 行,在底部填充 ⌊ p h / 2 ⌋ \lfloor p_h/2\rfloor ⌊ph/2⌋ 行。同理,我们填充宽度的两侧。
卷积神经网络中卷积核的高度和宽度通常为奇数,例如 1、3、5 或 7。
选择奇数的好处是,保持空间维度的同时,我们可以在顶部和底部填充相同数量的行,在左侧和右侧填充相同数量的列。
此外,使用奇数核和填充也提供了书写上的便利。对于任何二维张量 X,当满足:
- 内核的大小是奇数;
- 所有边的填充行数和列数相同;
- 输出与输入具有相同高度和宽度
则可以得出:输出Y[i, j]是通过以输入X[i, j]为中心,与卷积核进行互相关计算得到的。
比如,在下面的例子中,我们创建一个高度和宽度为3的二维卷积层,并(在所有侧边填充1个像素)。给定高度和宽度为8的输入,则输出的高度和宽度也是8。
2.5.1 填充
:是在输入的周围添加额外的行/列
# 为了方便起见,我们定义了一个计算卷积层的函数。
# 此函数初始化卷积层权重,并对输入和输出提高和缩减相应的维数
def comp_conv2d(conv2d, X):
# 这里的(1,1)表示批量大小和通道数都是1
X = X.reshape((1, 1) + X.shape)
Y = conv2d(X)
# 省略前两个维度:批量大小和通道
return Y.reshape(Y.shape[2:])
# 请注意,这里每边都填充了1行或1列,因此总共添加了2行或2列
conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1)
X = torch.rand(size=(8, 8))
comp_conv2d(conv2d, X).shape
torch.Size([8, 8])
当卷积内核的高度和宽度不同时,我们可以[填充不同的高度和宽度],使输出和输入具有相同的高度和宽度。在如下示例中,我们使用高度为5,宽度为3的卷积核,高度和宽度两边的填充分别为2和1。
conv2d = nn.Conv2d(1, 1, kernel_size=(5, 3), padding=(2, 1))
comp_conv2d(conv2d, X).shape
torch.Size([8, 8])
2.5.2 步幅
在计算互相关时,卷积窗口从输入张量的左上角开始,向下和向右滑动。
在前面的例子中,我们默认每次滑动一个元素。
但是,有时候为了高效计算或是缩减采样次数,卷积窗口可以跳过中间位置,每次滑动多个元素。
我们将每次滑动元素的数量称为 步幅 (stride)。到目前为止,我们只使用过高度或宽度为 1 1 1 的步幅,那么如何使用较大的步幅呢?
下图是垂直步幅为 3 3 3,水平步幅为 2 2 2 的二维互相关运算。着色部分是输出元素以及用于输出计算的输入和内核张量元素: 0 × 0 + 0 × 1 + 1 × 2 + 2 × 3 = 8 0\times0+0\times1+1\times2+2\times3=8 0×0+0×1+1×2+2×3=8、 0 × 0 + 6 × 1 + 0 × 2 + 0 × 3 = 6 0\times0+6\times1+0\times2+0\times3=6 0×0+6×1+0×2+0×3=6。
可以看到,为了计算输出中第一列的第二个元素和第一行的第二个元素,卷积窗口分别向下滑动三行和向右滑动两列。但是,当卷积窗口继续向右滑动两列时,没有输出,因为输入元素无法填充窗口(除非我们添加另一列填充)。
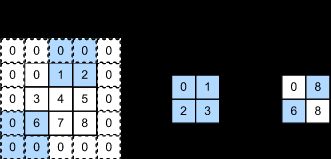
通常,当垂直步幅为 s h s_h sh 、水平步幅为 s w s_w sw 时,输出形状为
⌊ ( n h − k h + p h + s h ) / s h ⌋ × ⌊ ( n w − k w + p w + s w ) / s w ⌋ . \lfloor(n_h-k_h+p_h+s_h)/s_h\rfloor \times \lfloor(n_w-k_w+p_w+s_w)/s_w\rfloor. ⌊(nh−kh+ph+sh)/sh⌋×⌊(nw−kw+pw+sw)/sw⌋.
如果我们设置了 p h = k h − 1 p_h=k_h-1 ph=kh−1 和 p w = k w − 1 p_w=k_w-1 pw=kw−1,则输出形状将简化为 ⌊ ( n h + s h − 1 ) / s h ⌋ × ⌊ ( n w + s w − 1 ) / s w ⌋ \lfloor(n_h+s_h-1)/s_h\rfloor \times \lfloor(n_w+s_w-1)/s_w\rfloor ⌊(nh+sh−1)/sh⌋×⌊(nw+sw−1)/sw⌋。
更进一步,如果输入的高度和宽度可以被垂直和水平步幅整除,则输出形状将为 ( n h / s h ) × ( n w / s w ) (n_h/s_h) \times (n_w/s_w) (nh/sh)×(nw/sw)。
下面,我们[将高度和宽度的步幅设置为2],从而将输入的高度和宽度减半。
conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1, stride=2)
comp_conv2d(conv2d, X).shape
torch.Size([4, 4])
接下来,看(一个稍微复杂的例子)。
conv2d = nn.Conv2d(1, 1, kernel_size=(3, 5), padding=(0, 1), stride=(3, 4))
comp_conv2d(conv2d, X).shape
torch.Size([2, 2])
2.6 多输入多输出通道
2.6.1 多输入通道
当输入包含多个通道时,需要构造一个与输入数据具有相同输入通道数目的卷积核,以便与输入数据进行互相关运算。假设输入的通道数为 c i c_i ci,那么卷积核的输入通道数也需要为 c i c_i ci 。如果卷积核的窗口形状是 k h × k w k_h\times k_w kh×kw,那么当 c i = 1 c_i=1 ci=1 时,我们可以把卷积核看作形状为 k h × k w k_h\times k_w kh×kw 的二维张量。
然而,当 c i > 1 c_i>1 ci>1 时,我们卷积核的每个输入通道将包含形状为 k h × k w k_h\times k_w kh×kw 的张量。将这些张量 c i c_i ci 连结在一起可以得到形状为 c i × k h × k w c_i\times k_h\times k_w ci×kh×kw 的卷积核。由于输入和卷积核都有 c i c_i ci 个通道,我们可以对每个通道输入的二维张量和卷积核的二维张量进行互相关运算,再对通道求和(将 c i c_i ci 的结果相加)得到二维张量。这是多通道输入和多输入通道卷积核之间进行二维互相关运算的结果。
在下图中,我们演示了一个具有两个输入通道的二维互相关运算的示例。阴影部分是第一个输出元素以及用于计算这个输出的输入和核张量元素: ( 1 × 1 + 2 × 2 + 4 × 3 + 5 × 4 ) + ( 0 × 0 + 1 × 1 + 3 × 2 + 4 × 3 ) = 56 (1\times1+2\times2+4\times3+5\times4)+(0\times0+1\times1+3\times2+4\times3)=56 (1×1+2×2+4×3+5×4)+(0×0+1×1+3×2+4×3)=56。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yfUsBBRu-1628233284136)(attachment:image.png)]
为了加深理解,我们将(实现一下多输入通道互相关运算)。
简而言之,我们所做的就是对每个通道执行互相关操作,然后将结果相加。
import torch
from d2l import torch as d2l
def corr2d_multi_in(X, K):
# 先遍历 “X” 和 “K” 的第0个维度(通道维度),再把它们加在一起
return sum(d2l.corr2d(x, k) for x, k in zip(X, K))
# 验证互相关运算的输出
X = torch.tensor([[[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]],
[[1.0, 2.0, 3.0], [4.0, 5.0, 6.0], [7.0, 8.0, 9.0]]])
K = torch.tensor([[[0.0, 1.0], [2.0, 3.0]], [[1.0, 2.0], [3.0, 4.0]]])
corr2d_multi_in(X, K)
tensor([[ 56., 72.],
[104., 120.]])
2.6.2 多输出通道
到目前为止,不论有多少输入通道,我们还只有一个输出通道。然而,每一层有多个输出通道是至关重要的。在最流行的神经网络架构中,随着神经网络层数的加深,我们常会增加输出通道的维数,通过减少空间分辨率以获得更大的通道深度。直观地说,我们可以将每个通道看作是对不同特征的响应。而现实可能更为复杂一些,因为每个通道不是独立学习的,而是为了共同使用而优化的。因此,多输出通道并不仅是学习多个单通道的检测器。
用 c i c_i ci 和 c o c_o co 分别表示输入和输出通道的数目,并让 k h k_h kh 和 k w k_w kw 为卷积核的高度和宽度。为了获得多个通道的输出,我们可以为每个输出通道创建一个形状为 c i × k h × k w c_i\times k_h\times k_w ci×kh×kw 的卷积核张量,这样卷积核的形状是 c o × c i × k h × k w c_o\times c_i\times k_h\times k_w co×ci×kh×kw。在互相关运算中,每个输出通道先获取所有输入通道,再以对应该输出通道的卷积核计算出结果。
如下所示,我们实现一个[计算多个通道的输出的互相关函数]。
def corr2d_multi_in_out(X, K):
# 迭代“K”的第0个维度,每次都对输入“X”执行互相关运算。
# 最后将所有结果都叠加在一起
return torch.stack([corr2d_multi_in(X, k) for k in K], 0)
K = torch.stack((K, K + 1, K + 2), 0)
K.shape
torch.Size([3, 2, 2, 2])
X.shape
torch.Size([2, 3, 3])
corr2d_multi_in_out(X, K)
tensor([[[ 56., 72.],
[104., 120.]],
[[ 76., 100.],
[148., 172.]],
[[ 96., 128.],
[192., 224.]]])
2.7 1 X 1卷积
[1x1卷积]
1 × 1 1\times 1 1×1 卷积,即 k h = k w = 1 k_h = k_w = 1 kh=kw=1,看起来似乎没有多大意义。
毕竟,卷积的本质是有效提取相邻像素间的相关特征,而 1 × 1 1 \times 1 1×1 卷积显然没有此作用。
尽管如此, 1 × 1 1 \times 1 1×1 仍然十分流行,时常包含在复杂深层网络的设计中。下面,让我们详细地解读一下它的实际作用。
因为使用了最小窗口, 1 × 1 1\times 1 1×1 卷积失去了卷积层的特有能力——在高度和宽度维度上,识别相邻元素间相互作用的能力。
其实 1 × 1 1\times 1 1×1 卷积的唯一计算发生在通道上。
展示了使用 1 × 1 1\times 1 1×1 卷积核与 3 3 3 个输入通道和 2 2 2 个输出通道的互相关计算。
这里输入和输出具有相同的高度和宽度,输出中的每个元素都是从输入图像中同一位置的元素的线性组合。
我们可以将 1 × 1 1\times 1 1×1 卷积层看作是在每个像素位置应用的全连接层,以 c i c_i ci 个输入值转换为 c o c_o co 个输出值。
因为这仍然是一个卷积层,所以跨像素的权重是一致的。
同时, 1 × 1 1\times 1 1×1 卷积层需要的权重维度为 c o × c i c_o\times c_i co×ci ,再额外加上一个偏置。

下面,我们使用全连接层实现 1 × 1 1 \times 1 1×1 卷积。
请注意,我们需要对输入和输出的数据形状进行微调。
def corr2d_multi_in_out_1x1(X, K):
c_i, h, w = X.shape
c_o = K.shape[0]
X = X.reshape((c_i, h * w))
K = K.reshape((c_o, c_i))
# 全连接层中的矩阵乘法
Y = torch.matmul(K, X)
return Y.reshape((c_o, h, w))
当执行 1 × 1 1\times 1 1×1 卷积运算时,上述函数相当于先前实现的互相关函数corr2d_multi_in_out。让我们用一些样本数据来验证这一点。
X = torch.normal(0, 1, (3, 3, 3))
K = torch.normal(0, 1, (2, 3, 1, 1))
Y1 = corr2d_multi_in_out_1x1(X, K)
Y2 = corr2d_multi_in_out(X, K)
assert float(torch.abs(Y1 - Y2).sum()) < 1e-6
Y1
tensor([[[-0.4079, -1.3178, -0.2883],
[-0.7815, -1.2747, 1.3186],
[ 0.1661, -1.2738, 0.0152]],
[[-2.5953, -1.8065, 0.2015],
[-0.6631, -0.3564, 0.9317],
[ 0.4477, -1.6091, 1.5041]]])
Y2
tensor([[[-0.4079, -1.3178, -0.2883],
[-0.7815, -1.2747, 1.3186],
[ 0.1661, -1.2738, 0.0152]],
[[-2.5953, -1.8065, 0.2015],
[-0.6631, -0.3564, 0.9317],
[ 0.4477, -1.6091, 1.5041]]])
3、参考:
【1】李沐老师动手学深度学习V2
【2】个人博客非常全的CNN卷积神经网络整理