机器学习分析平台开发
文章目录
- 1.机器学习分析平台功能概述
- 2.运用的框架和Python包的接口
- 3.程序文件目录
- 4.思路和设计
-
- (1).程序的思路
- (2).程序的设计
- 5.机器学习分析平台的部分功能介绍
-
- (1).项目的部署和数据集的读取分析
- (2).机器学习建模和查看系统日志
- 6.机器学习分析平台的部分代码讲解
- 7.机器学习分析平台的全部代码呈现
- 8.参考资料
1.机器学习分析平台功能概述
为了实现RAInS项目(AI问责系统项目:RAInS Project Website)中数据分析和训练数据基本信息,将要使用Python来构建一个机器学习分析平台来帮助数据分析和数据建模。该平台会实现一些功能:设计一个网页版的用户界面,支持交互。支持从本地选取数据集,支持自动化可视化分析,支持回归分析和分类分析,支持查看训练记录,支持查看训练模型的参数和结果并且绘图。生成所需要的JSON文件,还可以预测新数据集,有异常检测,规则关联和其他细节功能。
2.运用的框架和Python包的接口
使用前请通过Conda或者Pip安装所需要的Python包
import os
import mlflow
# use streamlit to achieve interactive use on the web side
import streamlit as st
import pandas as pd
# used to display the report in the web page
from streamlit_pandas_profiling import st_profile_report
# used to generate reports
from pandas_profiling import ProfileReport
# machine learning classification
import pycaret.classification as pc_cl
# machine learning regression
import pycaret.regression as pc_rg
3.程序文件目录
![]()
data: 用来存放训练数据集和测试数据集
logs.log: 用于记录平台运行过程中系统产生的日志信息
mlruns: 用来管理训练的机器学习模板记录信息,可以作用到mlflow中
main.py: 机器学习分析平台的主程序代码
4.思路和设计
(1).程序的思路
最开始我是希望实现一个可以捕获到机器学习(ML)中数据流(训练数据基本信息,对训练数据是否进行处理,在ML部署后实际输入ML的真实数据,以及ML对这些真实数据的预测结果,预测花费的时间.) 并且要尝试获取信息如下:运行时是否出现异常,比如内存溢出,CPU超负荷等。硬件是否报错.还有真实输入数据格式,尺寸异常等。然后记录这些数据并且生成JSON文件作为一个接口来完成项目中的其他部分的工作。于是我就基于OpenCV完成了摄像头信息,物体运动时间和异常信息的捕获。很快,我就意识到一个严重的问题,基于特定的机器学习尝试这项工作只能使用特定的方法和参数,机器学习不全是通过同一个模板或者一个标准来完成每一项的任务的。有没有一个通用的方法将特殊的方法作为一个子集也能满足需求呢?
(2).程序的设计
机器学习离不开数据科学的辅助和加成。我使用UCI数据集获得所需要的数据源,并且可以让开发人员自己定义这些数据集,通过pandas-profiling来完成数据定义和分析,将机器学习原有的数据进行数据的可视化,并且可以通过JSON文件来保存生成的报告,这样的操作为工程师们在后期建模和问责提供了信息和帮助。
机器学习一般流程大致分为收集数据、探索数据、预处理数据,对数据处理后,接下来开始训练模型、评估模型,然后优化模型等步骤。
因为要获得一个完整的机器学习流程中的信息和记录,我用到了pycaret库来完成机器学习建模和分析,利用其中的回归分析和分类预测来实现机器学习的分析。首先从需要的数据集中获取所有的列名,可以让开发人员自由选择所需要的信息,也需要根据选好的任务中来获取算法。最后通过pycaret来使整个过程的日志保存到logs.log文件中。
对于管理整个模型还有预测工作,我想到了使用mlflow (MLflow Website). 这个工具中的Tracking功能可以记录每一次运行的参数和结果,模型可视化的绘制等数据。很惊喜的是,在pycaret中已经包含了mlflow的模板,当我在执行pycaret的时候会自动使用到mlflow管理运行记录和日志还有模型信息等。可以通过调用模板中的load_model函数来获取更多的模型信息和数据,最后很方便的一点开发人员只需要输入数据集就可以完成模型的预测工作。
MLflow 是 Databricks(spark) 推出的面对端到端机器学习的生命周期管理工具,它有如下四方面的功能:
跟踪、记录实验过程,交叉比较实验参数和对应的结果(MLflow Tracking).
把代码打包成可复用、可复现的格式,可用于成员分享和针对线上部署(MLflow Project).
管理、部署来自多个不同机器学习框架的模型到大部分模型部署和推理平台(MLflow Models).
针对模型的全生命周期管理的需求,提供集中式协同管理,包括模型版本管理、模型状态转换、数据标注(MLflow Model Registry).
MLflow 独立于第三方机器学习库,可以跟任何机器学习库、任何语言结合使用,因为 MLflow 的所有功能都是通过 REST API 和 CLI 的方式调用的,为了调用更方便,还提供了针对 Python、R、和 Java 语言的 SDK。
最后为了实现程序的可视化和UI交互,我使用了streamlit(Streamlit Website)来完成这项工作。streamlit库包含的组件满足大部分开发者需求,在设计网页UI只需要使用单个函数就可以完成html的设计和部署。
Streamlit是一个基于Python的可视化工具,和其他可视化工具不同的是,它生成的是一个可交互的站点(页面)。但同时它又不是我们常接触的类似Django、Flask这样的WEB框架。
平台的UI设计如下:

5.机器学习分析平台的部分功能介绍
(1).项目的部署和数据集的读取分析
首先我们使用git将Github中的项目用git clone仓库克隆到本地.通过pip或者Conda完成所需要Python包的安装.可以使用Python的IDE来编写或者Debug程序.使用streamlit来运行项目中的main.py程序.在终端中输入**‘streamlit run main.py’**.看到下图信息说明8501端口已经开启(在local URL还会有一个Network URL),我们可以在浏览器中使用程序进入UI页面.
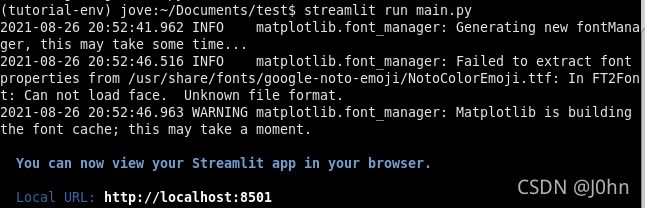
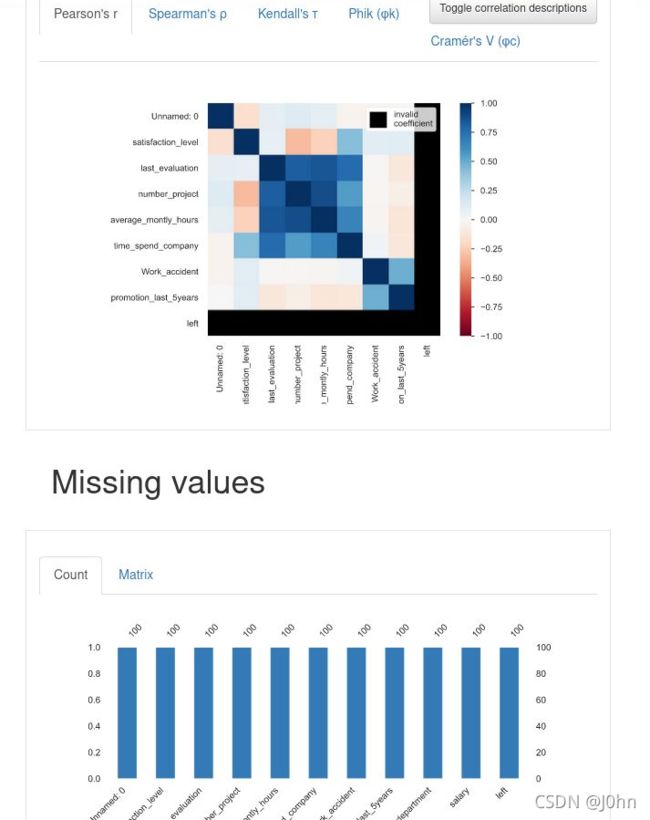
进入浏览器,在左侧的页面可以看见四个功能(定义数据源,数据集分析,建模,查看系统日志).用户需要将用户所需要用到的数据集放在./data目录下,用户可以自己选择需要的模型来完成机器学习训练和建模.用户也可以自己选择需要读取的行数,并且可以通过生成报告完成数据集可视化.如图所示:

对于数据的探索性分析会分为以下几个方面分析:
- 是否有缺失值?
- 是否有异常值?
- 是否有重复值?
- 样本是否均衡?
- 是否需要抽样?
- 变量是否需要转换?
- 是否需要增加新的特征?
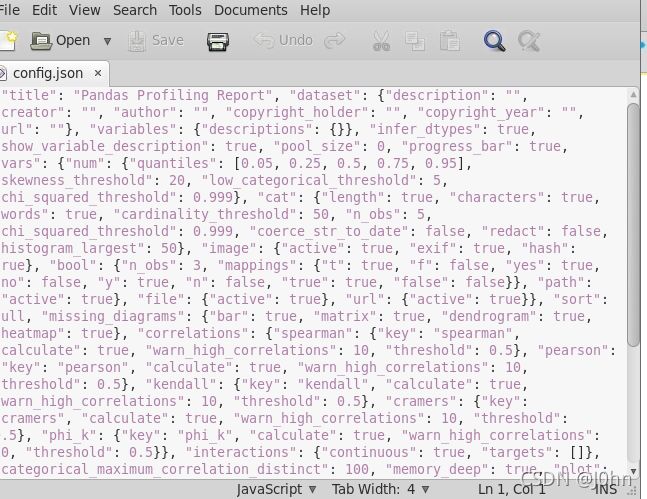
当开发人员需要用到平台这部分功能的数据和记录时候,只要选择Reproduction选项就可以看见关于系统的所有配置文件,并且可以随时下载config.json文件来完成其他的工作.
(2).机器学习建模和查看系统日志
定义和分析完了用户所需要的数据源,现在需要进行建模了.项目对于建模这一部分功能是非常方便的,并且可用性很高.在建模时候用到了数据科学中最常用的两个算法:回归和分类.在我的观点里这两种算法最大的不一样是损失函数的形式不同,定量输出称为回归算法,属于连续变量预测.分类算法属于定性,是离散变量预测。然后开发人员可以添加模型算法,例如xgboost,svm,lr等常用算法.最后开发人员选择需要预测数据集中的一个对象(目前项目还不能支持同时预测多个对象,交叉验证等).对于这部分功能,代码里创建了三个列表来储存这些将要用到的建模参数.

在机器学习建模工作完成后,开发人员可以自己选择自己已经训练好的模型和数据集,并且可以直接使用模型.开发人员还可以查看系统日志来帮助分析和改进.用户可以自己选择读取并查看多少行的系统日志.如图所示:

6.机器学习分析平台的部分代码讲解
在主函数之前存在多个拥有辅助功能的函数:
concatFilePath(file_folder, file_selected)用于获取数据的完整路径,然后读取数据集:
# get the full path of the file, used to read the dataset
def concatFilePath(file_folder, file_selected):
if str(file_folder)[-1] != '/':
fileSelectedPath = file_folder + '/' + file_selected
else:
fileSelectedPath = file_folder + file_selected
return fileSelectedPath
在getModelTrainingLogs(n_lines = 10)函数里读取logs.log,显示最后选择的行数,用户可设置行数:
# read logs.log, display the number of the last
# selected line, the user can set the number of lines
def getModelTrainingLogs(n_lines = 10):
file = open('logs.log', 'r')
lines = file.read().splitlines()
file.close()
return lines[-n_lines:]
最后针对程序的性能使用,在加载数据集的函数load_csv中会将数据集放入缓存,重复加载之前使用过的数据集不会重复再次占用系统资源。
# load the data set, put the data set into the cache
@st.cache(suppress_st_warning=True)
def load_csv(file_selected_path, nrows):
try:
if nrows == -1:
df = pd.read_csv(file_selected_path)
else:
df = pd.read_csv(file_selected_path, nrows=nrows)
except Exception as ex:
df = pd.DataFrame([])
st.exception(ex)
return df
7.机器学习分析平台的全部代码呈现
"""
RAInS Project: machine-learning analysis platform
Author: Junhao Song
Email: [email protected]
Website: http://junhaosong.com/
"""
import os
import mlflow
# use streamlit to achieve interactive use on the web side
import streamlit as st
import pandas as pd
# used to display the report in the web page
from streamlit_pandas_profiling import st_profile_report
# used to generate reports
from pandas_profiling import ProfileReport
# machine learning classification
import pycaret.classification as pc_cl
# machine learning regression
import pycaret.regression as pc_rg
# store some commonly used machine learning modeling techniques
ML_LIST = ['Regression', 'Classification']
RG_LIST = ['lr', 'svm', 'rf', 'xgboost', 'lightgbm']
CL_LIST = ['lr', 'dt', 'svm', 'rf', 'xgboost', 'lightgbm']
# list certain extension files in the folder
def listFiles(directory, extension):
return [f for f in os.listdir(directory) if f.endswith('.' + extension)]
# read logs.log, display the number of the last
# selected line, the user can set the number of lines
def getModelTrainingLogs(n_lines = 10):
file = open('logs.log', 'r')
lines = file.read().splitlines()
file.close()
return lines[-n_lines:]
# get the full path of the file, used to read the dataset
def concatFilePath(file_folder, file_selected):
if str(file_folder)[-1] != '/':
fileSelectedPath = file_folder + '/' + file_selected
else:
fileSelectedPath = file_folder + file_selected
return fileSelectedPath
# load the data set, put the data set into the cache
@st.cache(suppress_st_warning=True)
def load_csv(file_selected_path, nrows):
try:
if nrows == -1:
df = pd.read_csv(file_selected_path)
else:
df = pd.read_csv(file_selected_path, nrows=nrows)
except Exception as ex:
df = pd.DataFrame([])
st.exception(ex)
return df
def app_main():
st.title("Machine learning analysis platform")
if st.sidebar.checkbox('Define Data Source'):
filesFolder = st.sidebar.text_input('folder', value="data")
dataList = listFiles(filesFolder, 'csv')
if len(dataList) ==0:
st.warning('No data set available')
else:
file_selected = st.sidebar.selectbox(
'Select a document', dataList)
file_selected_path = concatFilePath(filesFolder, file_selected)
nrows = st.sidebar.number_input('Number of lines', value=-1)
n_rows_str = 'All' if nrows == -1 else str(nrows)
st.info('Selected file:{file_selected_path},The number of rows read is{n_rows_str}')
else:
file_selected_path = None
nrows = 100
st.warning('The currently selected file is empty, please select:')
if st.sidebar.checkbox('Exploratory Analysis'):
if file_selected_path is not None:
if st.sidebar.button('Report Generation'):
df = load_csv(file_selected_path, nrows)
pr = ProfileReport(df, explorative=True)
st_profile_report(pr)
else:
st.info('No file selected, analysis cannot be performed')
if st.sidebar.checkbox('Modeling'):
if file_selected_path is not None:
task = st.sidebar.selectbox('Select Task', ML_LIST)
if task == 'Regression':
model = st.sidebar.selectbox('Select Model', RG_LIST)
elif task == 'Classification':
model = st.sidebar.selectbox('Select Model', RG_LIST)
df = load_csv(file_selected_path, nrows)
try:
cols = df.columns.to_list()
target_col = st.sidebar.selectbox('Select Prediction Object', cols)
except BaseException:
st.sidebar.warning('The data format cannot be read correctly')
target_col = None
if target_col is not None and st.sidebar.button('Training Model'):
if task == 'Regression':
st.success('Data preprocessing...')
pc_rg.setup(
df,
target=target_col,
log_experiment=True,
experiment_name='ml_',
log_plots=True,
silent=True,
verbose=False,
profile=True)
st.success('Data preprocessing is complete')
st.success('Training model. . .')
pc_rg.create_model(model, verbose=False)
st.success('The model training is complete. . .')
#pc_rg.finalize_model(model)
st.success('Model has been created')
elif task == 'Classification':
st.success('Data preprocessing. . .')
pc_cl.setup(
df,
target=target_col,
fix_imbalance=True,
log_experiment=True,
experiment_name='ml_',
log_plots=True,
silent=True,
verbose=False,
profile=True)
st.success('Data preprocessing is complete.')
st.success('Training model. . .')
pc_cl.create_model(model, verbose=False)
st.success('The model training is complete. . .')
#pc_cl.finalize_model(model)
st.success('Model has been created')
if st.sidebar.checkbox('View System Log'):
n_lines =st.sidebar.slider(label='Number of lines',min_value=3,max_value=50)
if st.sidebar.button("Check View"):
logs = getModelTrainingLogs(n_lines=n_lines)
st.text('System log')
st.write(logs)
try:
allOfRuns = mlflow.search_runs(experiment_ids=0)
except:
allOfRuns = []
if len(allOfRuns) != 0:
if st.sidebar.checkbox('Preview model'):
ml_logs = 'http://kubernetes.docker.internal:5000/ -->Open mlflow, enter the command line: mlflow ui'
st.markdown(ml_logs)
st.dataframe(allOfRuns)
if st.sidebar.checkbox('Choose a model'):
selected_run_id = st.sidebar.selectbox('Choose from saved models', allOfRuns[allOfRuns['tags.Source'] == 'create_model']['run_id'].tolist())
selected_run_info = allOfRuns[(
allOfRuns['run_id'] == selected_run_id)].iloc[0, :]
st.code(selected_run_info)
if st.sidebar.button('Forecast data'):
model_uri = 'runs:/' + selected_run_id + '/model/'
model_loaded = mlflow.sklearn.load_model(model_uri)
df = pd.read_csv(file_selected_path, nrows=nrows)
#st.success('Model prediction. . .')
pred = model_loaded.predict(df)
pred_df = pd.DataFrame(pred, columns=['Predictive Data'])
st.dataframe(pred_df)
pred_df.plot()
st.pyplot()
else:
st.sidebar.warning('Did not find a trained model')
if __name__ == '__main__':
app_main()
该项目的演示视频链接如下:
Demo Video
最后本项目感谢我的导师Wei Pang(Github)的学术指导和Danny(Github)的技术帮助.
版权声明
本文被以下参考引用内容外均为J0hn原创内容,最终解释权归原作者所有。如有侵权,请联系删除。未经本人授权,请勿私自转载!
8.参考资料
[1]. Kaggle XGboost https://www.kaggle.com/alexisbcook/xgboost
[2]. Kaggle MissingValues https://www.kaggle.com/alexisbcook/missing-values
[3]. MLflow Tracking https://mlflow.org/docs/latest/tracking.html
[4]. Google AutoML https://cloud.google.com/automl-tables/docs/beginners-guide
[5]. 7StepML https://towardsdatascience.com/the-7-steps-of-machine-learning-2877d7e5548e
[6]. ScikitLearn https://scikit-learn.org/stable/getting_started.html#model-evaluation
[7]. UCIDataset https://archive.ics.uci.edu/ml/datasets.php
[8]. Wikipedia https://en.wikipedia.org/wiki/Gradient_boosting
[9]. ShuhariBlog https://shuhari.dev/blog/2020/02/streamlit-intro