完整的模型训练套路(二)————PyTorch(注释最全)
哔哩大学的PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】
的P28讲继续进行完整的训练模型套路练习。
完整的模型训练套路(二)接(一)做了完善,包括保存tensorboad等。
代码注释如下:注释很全,就不写总结了
import torch
import torchvision
from torch.utils.tensorboard import SummaryWriter
from model import *
from torch import nn
from torch.utils.data import DataLoader
# 创建训练集
train_data = torchvision.datasets.CIFAR10(root="data", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
# 创建测试集
test_data = torchvision.datasets.CIFAR10(root="data", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
train_data_size = len(test_data)
test_data_size = len(test_data)
# 如果训练数据集的长度train_data_size=10,则会输出 训练数据集的长度为:10
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))
# 利用DataLoader来加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)
# 创建网络模型
tudui = Tudui()
# 创建损失函数
loss_fn = nn.CrossEntropyLoss()
# 定义优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate) # SGD为随机梯度下降优化器,学习速率为learning_rate = 0.01
# 设置训练网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的轮数
epoch = 10
writer = SummaryWriter("logs_train") # tensorboard的使用
for i in range(epoch):
print("------第 {} 轮训练开始------".format(i+1)) # 为了符合阅读习惯,写成i+1
# 训练步骤开始
for data in train_dataloader:
imgs, targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs, targets) # 输出和目标之间的损失值
# 优化器调优优化模型
optimizer.zero_grad() # 优化前梯度清零
loss.backward() # 调用损失的反向传播,得到每个参数检验的梯度
optimizer.step()# 调用优化器
# 一次训练完成,训练次数+1
total_train_step = total_train_step + 1
if total_train_step %100 == 0: # total_train_step为100的整数时则输出
print("训练次数: {},Loss: {}".format(total_train_step, loss.item()))
# 因为有两个{}需要替换,所以format有两个量
writer.add_scalar("train_loss", loss.item(), total_train_step) # tensorboard的使用
# 为了知道每轮的训练结果如何,进行测试,以测试数据集上的损失或者正确率来评估模型有没有训练好
# 为保证在测试的时候不再进行调优,用 with torch.no_grad():
total_test_loss = 0
total_accuracy = 0 # z整体正确率
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
outputs = tudui(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
# 测试集中的每次loss相加得到total_test_loss
accuracy = (outputs.argmax(1) == targets).sum() # 正确率的内容
total_accuracy = total_accuracy + accuracy # 正确率的内容
print("整体测试集上的Loss: {}".format(total_test_loss))
print("整体测试集上的正确率: {}".format(total_accuracy/test_data_size)) # 正确率的内容,测试的正确的比上总的
writer.add_scalar("test_loss", total_test_loss, total_test_step) # tensorboard的使用
writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)# tensorboard正确率和步进
total_test_step = total_test_step + 1
# 保存每一轮训练的模型
torch.save(tudui, "tudui_{}.pth".format(i))
print("模型已保存")
writer.close()
运行结果如图:
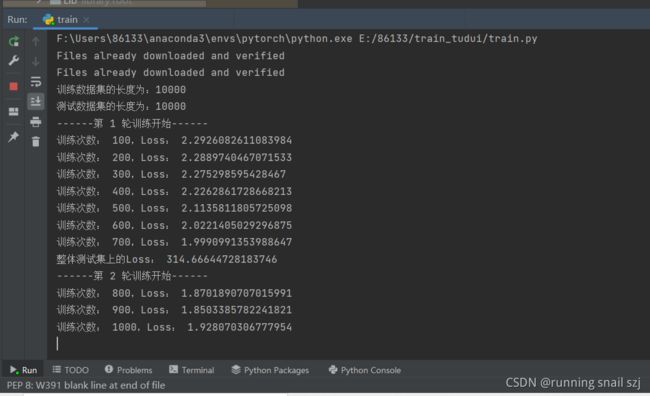
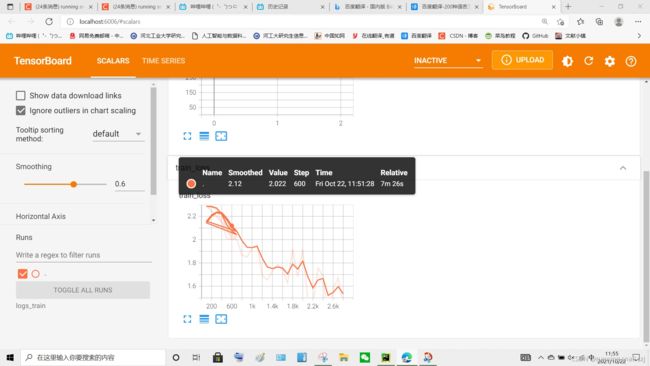
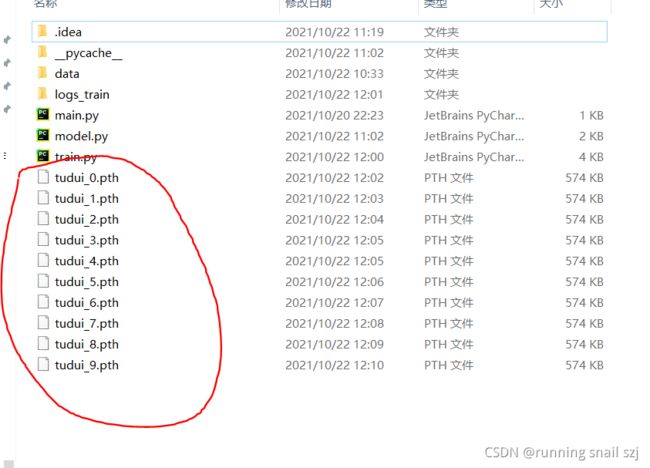
加上正确率的问题
可以在代码中再进行一个优化,来计算代码的正确率
其原理为:
import torch
outputs = torch.tensor([[0.1, 0.2],
[0.3, 0.4]])
print(outputs.argmax(1))
preds = outputs.argmax(1)
targets = torch.tensor([0, 1])
print((preds ==targets).sum())
结果为:

看不懂,想了解可以看开头的链接,视频后半部分有讲解
小土堆的训练套路(三)
在小土堆的训练套路(三)里讲解了,tudui.train() 和 tuidui.eval()的添加用法。可以在官网中docs—pytorch—torch.nn—containers—module中查看。
一:该网页按下ctrl+F,搜索train如下:

tudui.train():网络模型中有dropout、batchnorm模型时可以用到
tudui.train() 在最上边train代码中的用法:
for i in range(epoch):
print("------第 {} 轮训练开始------".format(i+1)) # 为了符合阅读习惯,写成i+1
tudui.train() # 此处有添加!!!
# 训练步骤开始
for data in train_dataloader:
二:eval的用法如下:之对特定层有作用,例如dropout
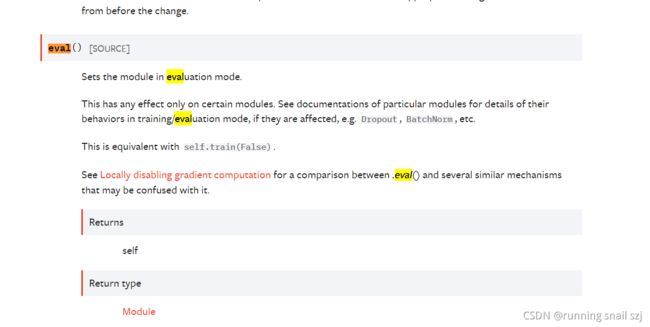
tuidui.eval()在最上边代码中的用法:
# 为了知道每轮的训练结果如何,进行测试,以测试数据集上的损失或者正确率来评估模型有没有训练好
# 为保证在测试的时候不再进行调优,用 with torch.no_grad():
tudui.eval() # 此处添加!!!
total_test_loss = 0
total_accuracy = 0 # z整体正确率
没有这些层也可以添加上。