【图像超分辨率重建】——EDSR论文精读笔记
2017-Enhanced Deep Residual Networks for Single Image Super-Resolution(EDSR)
基本信息
作者: Bee Lim Sanghyun Son Heewon Kim Seungjun Nah Kyoung Mu Lee
期刊: CVPR2017
引用: *
摘要: 随着深度卷积神经网络(DCNN)的发展,最近对超分辨率的研究取得了进展。 特别是,残差学习技术表现出改进的性能。 在本文中,我们开发了一种增强的深度超分辨率网络(EDSR),其性能超过了当前最先进的 SR 方法。 我们模型的显着性能改进是由于通过删除传统残差网络中不必要的模块进行的优化。 在我们稳定训练过程的同时,通过扩大模型大小进一步提高了性能。 我们还提出了一种新的多尺度深度超分辨率系统(MDSR)和训练方法,可以在单个模型中重建不同放大因子的高分辨率图像。 所提出的方法在基准数据集上显示出优于最先进方法的性能,并通过赢得 NTIRE2017 超分辨率挑战赛证明了其卓越性。
1.简介
介绍SISR的基本概念,并指出在大部分SISR研究中,HR和LR之间都是使用Bicubic,但在实际应用中也可以考虑其他退化因素,例如模糊、抽取或噪声。
近期的作品VDSR、DRCN、SRResNet等模型在PSNR上表现很好,但是仍有以下局限性:
- 神经网络模型的重建性能对微小的架构变化很敏感。此外,相同的模型通过不同的初始化和训练技术实现不同级别的性能。因此,精心设计的模型架构和复杂的优化方法对于训练神经网络至关重要。
- 大多数现有的SR算法将不同尺度因素的超分辨率视为独立问题,而没有考虑和利用SR中不同尺度之间的相互关系。因此,这些算法需要许多特定尺度的网络,需要独立训练以处理各种尺度的问题。
- VDSR用多种尺度训练VDSR模型可以大幅提高性能,并优于特定尺度训练,这意味着特定尺度模型之间存在冗余。然而,VDSR风格的架构需要双三次插值的图像作为输入,这导致了与具有特定尺度上采样方法的架构相比更多的计算时间和内存
- SRResNet成功地解决了这些时间和内存问题,并具有良好的性能,但它只是简单地采用了He等人的ResNet架构,没有做太多修改。然而,最初的ResNet是为了解决更高层次的计算机视觉问题,如图像分类和检测。因此,将ResNet结构直接应用于低层次的视觉问题,如超分辨率,可能是次优的。
为了解决以上问题,基于SRResNet,本文作者进行了如下改进:
- 先通过分析和删除不必要的模块来优化它,以简化网络架构。用适当的损失函数训练网络,并在训练时仔细修改模型。
- 其次,我们研究了从其他尺度训练的模型转移知识的模型训练方法。为了在训练中利用与尺度无关的信息,我们从预先训练的低尺度模型中训练高尺度模型。
- 此外,我们提出了一个新的多尺度结构,在不同尺度之间共享大部分参数。与多个单尺度模型相比,所提出的多尺度模型使用的参数要少得多,但却显示出相当的性能
本文的方法是NITRE2017比赛的冠亚军。
2.相关工作
- 插值法、统计学方法:预测详细、真实的纹理方面表现出局限性。
- 传统机器学习:邻域嵌入、稀疏编码等
- 深度学习方法:SRCNN,VDSR,DRCN(跳连接和递归卷积等)
在模型中,图像上采用一般有双三次预上采用和网络层上采用两种方式
- 预上采样:在一个单一的框架中处理多尺度问题。
- 网络层上采用:不损失模型容量的情况下减少很多计算,特征的大小减少。
本文解决了多尺度训练和计算效率的两难问题。我们不仅利用了每个尺度的学习特征的相互关系,还提出了一个新的多尺度模型,有效地重建了各种尺度的高分辨率图像。此外,我们开发了一种适当的训练方法,对单尺度和多尺度模型都使用了多尺度。
3.超分辨EDSR方法
3.1.残差块
残差网络在计算机视觉问题上表现出了从低级到高级任务的优异性能。成功地将ResNet结构应用于SRResNet的超分辨率问题,但我们通过采用更好的ResNet结构进一步提高了性能。
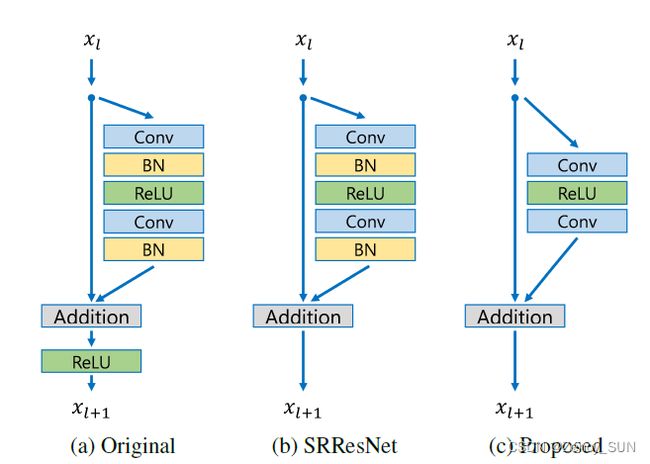
本文残差块示意图如图所示,我们从网络中删除了批量归一化层。由于批量归一化层对特征进行了归一化处理,它们通过对特征的归一化处理摆脱了网络的范围灵活性,因此最好将它们删除。我们的实验表明,这个简单的修改大大增加了性能。此外,由于批处理归一化层与前面的卷积层消耗相同的内存,因此GPU内存的使用也得到了充分的减少。
3.2.单尺度模型EDSR
提高网络模型性能的最简单方法是增加参数的数量。在卷积神经网络中,可以通过堆叠许多层或增加过滤器的数量来提高模型性能。残差块层数B(n_resblocks),卷积层特征通道数F(n_feats),占用O(BF)内存,参数有O(BF²),考虑到计算机内存,应该增加F。
然而,将F增加到一定程度以上会使训练过程在数值上不稳定。我们通过采用因子为0.1的残差缩放Mult(res_scale) 来解决这个问题。在每个残差块中,恒定的缩放层被放置在最后的卷积层之后。当使用大量的过滤器时,这些模块大大稳定了训练过程。在测试阶段,为了提高计算效率,该层可以被整合到前一个卷积层中。
- EDSR-baseline模型——B=16,F=64,无残差缩放
- EDSR模型——B=32,F=256,残差缩放因子=0.1
训练加速:当训练我们的模型用于上采用系数3和4时,我们用预训练的2个网络初始化模型参数。这种预训练策略加速了训练,并提高了最终的性能。

3.3.多尺度模型MDSR
本文认为,多尺度的超分辨率是相互关联的任务。我们通过建立一个多尺度架构来进一步探索这个想法,该架构像VDSR一样利用尺度间的相关性的优势。
首先,预处理模块位于网络的头部,以减少来自不同尺度的输入图像的差异。每个预处理模块由两个具有5×5的内核的残差块组成。通过对预处理模块采用较大的内核,我们可以保持特定尺度部分的浅层,而在网络的早期阶段覆盖较大的感受野。在多尺度模型的末端,特定尺度的上采样模块被平行放置以处理多尺度重建。上采样模块的结构与上节所述的单尺度模型的结构相似。
- MDSR-baseline模型——B=16,F=64,无残差缩放
- MDSR模型——B=80,F=64,无残差缩放
模型比较的结论:
-
从参数角度来看,3个不同尺度的EDSR-baseline模型共4.5M个参数,而MDSR-baseline模型只有3.2M个参数,参数少了很多,而可以达到相当的效果。
-
从模型的角度来看,MDSR和MDSR-baseline相比,MDSR的深度是MDSR-baseline的5倍,但只需要2.5倍的参数,因为残余块比特定尺度的部分要轻。同时,MDSR也显示出与特定尺度EDSR相当的性能。


| 模型 | 基本参数 | 特点 | 上采样 | 批量标准化 | 残差缩放 | 损失函数 | Self-ensemble |
|---|---|---|---|---|---|---|---|
| EDSR | B=32;F=256 | 全局跳链接 | 后上采样 | 无 | 有 | L1损失 | 支持 |
| MDSR | B=80 | 主题部分参数共享 | 后上采样 | 无 | 无 | L1损失 | 支持 |
4.实验
4.1.数据集
本文使用DIV2K数据集(800Train,100Val,100Test),在Val上评估性能,同时也在另外四个标准基准数据集的性能:Set5 、Set14 、B100和 Urban100。
4.2.训练细节
- 使用LR的RGB图像的48×48Patch(HR对应),随机水平翻转与90°旋转,ADAM优化器,Batch=16…
- 单尺度(EDSR×2/3/4)训练:×2是从头训练,×3/4基于×2进行训练
- 多尺度(MDSR)训练:用2、3和4中随机选择的尺度构建miniBatch。只有对应于所选尺度的模块被启用和更新。因此,对应于所选尺度以外的不同尺度的特定尺度残差块和上采样模块不会被启用或更新。
- 使用L1损失来训练我们的网络。最小化L2通常是首选,因为它能使PSNR最大化。然而,L1损失比L2提供更好的收敛性。
- 使用Torch7实现,NVIDIA Titan X GPU训练
4.3.几何自集成(Self_ensemble)
为了最大限度地提高我们模型的潜在性能,我们采用Self_ensemble策略。具体流程如下:
测试时,翻转和旋转输入LR图像,生成7个图像(共8个),输入网络后得到8个相应的SR图像,对这些图像进行逆变换得到原始的LRs*,最后对LRs*求平均得到LRnew。
这种自集成方法比其他集成方法具有优势,因为它不需要对单独的模型进行额外的训练。特别是当模型大小或培训时间很重要时,这是有益的。尽管自集成策略使参数总数保持不变,但与需要单独训练模型的传统模型集成方法相比,它提供了大致相同的性能增益。本文使用“+”表示。几何自集成仅对对称下采样方法有效,例如双三次下采样。
4.4.验证(DIV2K)
- 本文在DIV2K数据集上测试我们提出的网络。从SRResNet开始,我们逐渐更改各种设置以执行消融测试。我们自己训练SRResNet。首先,我们将损失函数从L2改为L1,然后按照上一节所述和表1所示对网络结构进行更改。上图为各模型的区别。
- 在实验中对模型进行了30w次更新,评估DIV2K-Val的801-811共10张图片,使用PSNR(RGB,忽略6+scale边界)和SSIM参数
- 结论1:对于所有比例因子,用L1训练的SRResNet比用L2训练的原始SRResNets的结果稍好。
- 结论2:最后两列显示了我们最终的更大型号EDSR+和MDSR+使用几何自集成技术的显著性能提升。

4.5.基准测试结果
使用本文最终的模型(EDSR、EDSR+,MDSR、MDSR+)与Bicubic,A+,SRCNN,VDSR,SRResNet等模型比较。模型使用100W次更新,Batch=16,其他设置和baseline相同,评估Set5 、Set14 、B100,Urban100,DIV2K数据集,使用PSNR(Y通道,忽略Scale边界)SSIM参数,使用Matlab进行评估结果(DIV2K验证结果是从发布的演示代码中获得的。)。结果可以看到效果还是很不错的。

5.NITRE2017超分辨挑战赛
比赛首页:https://data.vision.ee.ethz.ch/cvl/ntire17//
数据集首页:https://data.vision.ee.ethz.ch/cvl/DIV2K/
比赛详情:
- 2017Track1:Bicubic赛道(×2/3/4)
- 2017Track2:Unknown赛道(×2/3/4)
- 2018Track1:Bicubic赛道(×8)
- 2018Track2:Mild赛道(x4)
- 2018Track3:Diffcult赛道(x4)
- 2018Track4:Realistic赛道(x4)
本文为2017年的比赛的2个任务6个赛道均提交了2个模型(EDSR、MDSR),模型在所有6个赛道均中取得了第一第二的成绩。

6.结论
- 本文提出了一种增强的超分辨率算法。通过从传统的 ResNet 架构中删除不必要的模块,我们在使模型紧凑的同时取得了改进的结果。我们还采用残差缩放技术来稳定地训练大型模型。我们提出的单尺度模型超越了当前模型并达到了最先进的性能。
- 本文开发了一个多尺度超分辨率网络来减少模型大小和训练时间。通过尺度依赖模块和共享主网络,我们的多尺度模型可以在一个统一的框架中有效地处理各种尺度的超分辨率。虽然与一组单尺度模型相比,多尺度模型保持紧凑,但它显示出与单尺度 SR 模型相当的性能。
本文提出的单尺度和多尺度模型在标准基准数据集和 DIV2K 数据集中都取得了最高排名
代码实现
Torch版本代码:https://github.com/LimBee/NTIRE2017
Pytorch代码:https://github.com/sanghyun-son/EDSR-PyTorch/