pytorch深度学习代码中遇到的各种知识点集合
每天都加一点点
ps:ctrl+F查找
A
argparse.ArgumentParser()
argparse是一个Python模块:解析命令行参数(参数解析工具)
import argparse
# (1)【解析传入参数】声明一个parser,创建 ArgumentParser() 对象
parser = argparse.ArgumentParser()
# (2) 添加参数,调用 add_argument() 方法添加参数
parser.add_argument("parg") # 位置参数,这里表示第一个出现的参数赋值给parg
parser.add_argument("--digit",type=int,help="输入数字") # 通过 --echo xxx声明的参数,为int类型
parser.add_argument("--name",help="名字",default="cjf") # 同上,default 表示默认值
# (3) 读取命令行参数,使用 parse_args() 解析添加的参数
args = parser.parse_args()
# (4) 调用这些参数
print(args.parg)
print("echo ={0}".format(args.digit))
print("name = {}".format(args.name))
add_subparsers()
添加子命令(当程序复杂,不同功能需要不同参数时)
subparsers = parser.add_subparsers(dest='processor')
for k, p in processors.items():
subparsers.add_parser(k, parents=[p.get_parser()])
import argparse
parser = argparse.ArgumentParser(prog='PROG')
subparsers = parser.add_subparsers(help='sub-command help')
#添加子命令 add
parser_a = subparsers.add_parser('add', help='add help')
parser_a.add_argument('-x', type=int, help='x value')
parser_a.add_argument('-y', type=int, help='y value')
#添加子命令 sub
parser_s = subparsers.add_parser('sub', help='sub help')
parser_s.add_argument('-x', type=int, help='x value')
parser_s.add_argument('-y', type=int, help='y value')
args = parser.parse_args()
print('x', args.x, 'y', y
sys.argv[]
可以看作是一个列表,里边的项为用户输入的参数个数。所以才能用[]提取其中的元素。一个元素是程序本身,随后才依次是外部给予的参数。(我理解的相当于切片)
a = sys.argv[2:]
#保存后,在命令行中输入python test.py naruto sasuke sakura kakashi
#输出为一个列表——[‘sasuke’, ‘sakura’, ‘kakashi’]
B
build
1)__init__主要用来做参数初始化用,比如我们要初始化卷积的一些参数,就可以放到这里面
2)call可以把类型的对象当做函数来使用,这个对象可以是在__init__里面也可以是在build里面
3)build一般是和call搭配使用,这个时候,它的功能和__init__很相似,当build中存放本层需要初始化的变量,当call被第一次调用的时候,会先执行build()方法初始化变量,但后面再调用到call的时候,是不会再去执行build()方法初始化变量
—init—函数:这个函数用于对所有独立的输入进行初始化。(独立的输入:特指和训练数据无关的输入)(这个函数仅被执行一次)
build函数:在call()函数第一次执行时会被调用一次,这时候可以知道输入数据的shape。返回去看一看,果然是__init__()函数中只初始化了输出数据的shape,而输入数据的shape需要在build()函数中动态获取,这也解释了为什么在有__init__()函数时还需要使用build()函数
call函数:这个函数就是用来前向计算的函数了
init先被执行,且仅执行一次。build也是,第一次调用Call函数执行。call每次被调用都会被执行。
import tensorflow as tf
class MyDenseLayer(tf.keras.layers.Layer):
def __init__(self, num_outputs):
super(MyDenseLayer, self).__init__()
print('init 被执行')
self.num_outputs = num_outputs
self.i = 0
print('Init:This is i',self.i)
self.i = self.i +1
def build(self,input_shape):
print('build 被执行')
print('input_shape',input_shape)
print('Build:This is i',self.i)
self.kernel = self.add_weight("kernel",shape=[int(input_shape[-1]),
self.num_outputs])
def call(self, input):
print('call 被执行')
return tf.matmul(input, self.kernel)
layer = MyDenseLayer(10)
_ = layer(tf.zeros([10, 5])) # Calling the layer `.builds` it.
print([var.name for var in layer.trainable_variables])
_ = layer(tf.ones([10, 5]))
print([var.name for var in layer.trainable_variables])
输出结果:
init 被执行
Init:This is i 0
build 被执行
input_shape (10, 5)
Build:This is i 1
call 被执行
['my_dense_layer/kernel:0']
call 被执行
['my_dense_layer/kernel:0']
C
ceil()
math.ceil()“向上取整”, 即小数部分直接舍去,并向正数部分进1
contiguous()
将tensor的内存变为连续的。
有些tensor并不是占用一整块内存,而是由不同的数据块组成,而tensor的view()操作依赖于内存是整块的,这时只需要执行contiguous()这个函数,把tensor变成在内存中连续分布的形式。
注:在pytorch的最新版本0.4版本中,增加了torch.reshape(), 这与 numpy.reshape 的功能类似。它大致相当于 tensor.contiguous().view()。
def forward(self, x): # [B, N, F]
b, n, f = x.shape
x = x.permute(0, 2, 1).contiguous().view(-1,n) # [b*f,n]
x_part = []
for i in range(len(self.part_list)):
x_part.append(self.mlps[i](x[:, self.part_list[i]])) # [b*f,3]
x_part = torch.cat(x_part, dim=-1) # [b*f,30]
x_part = x_part.view(b,f,-1).permute(0,2,1).contiguous() # [b,30,f]
return x_part
torch.nn.Conv2d
对由多个输入平面组成的输入信号进行二维卷积:torch.nn.Conv2d
ckpt文件
ckpt文件是二进制文件,保存了所有的weights、biases、gradients等变量。
def save_ckpt(state, ckpt_path, is_best=True):
if is_best:
file_path = os.path.join(ckpt_path, 'ckpt_best.pth.tar')
torch.save(state, file_path)
else:
file_path = os.path.join(ckpt_path, 'ckpt_last.pth.tar')
torch.save(state, file_path)
clone()
参考
Torch 为了提高速度,向量或是矩阵的赋值是指向同一内存的,这不同于 Matlab。如果需要保存旧的tensor即需要开辟新的存储地址而不是引用,可以用 clone() 进行深拷贝
import torch
# 原始a:tensor(3., requires_grad=True)
a = torch.tensor(1.0, requires_grad=True)
#grad_fn=,表示clone后的返回值是个中间变量,因此支持梯度的回溯。clone操作在一定程度上可以视为是一个identity-mapping函数。
b = a.clone()
#detach()操作后的tensor与原始tensor共享数据内存,当原始tensor在计算图中数值发生反向传播等更新之后,detach()的tensor值也发生了改变。
c = a.detach()
a.data *= 3
b += 1
print(a) # tensor(3., requires_grad=True)
print(b)
print(c)
'''
输出结果:
tensor(3., requires_grad=True)
tensor(2., grad_fn=)
tensor(3.) # detach()后的值随着a的变化出现变化
'''
nn.init.constant_(conv.bias, 0)
torch.nn.init.constant_(tensor, val)
用值val填充向量。
参数:
tensor – an n-dimensional torch.Tensor
val – the value to fill the tensor with
D
dot
ST-GCN中的构造卷积核的代码:
def normalize_digraph(A): #A为节点邻接矩阵
#按照axis=0对A进行所有特征向量的求和,形成[1,number_node]的向量V
Dl = np.sum(A, 0)
num_node = A.shape[0] #节点数
#初始化对角矩阵Dn[number_node,number_node]
Dn = np.zeros((num_node, num_node))
#依次遍历每个元素,若第i个元素大于0,则我们为Dn的对角元素Dn_ii赋值为V**-1
for i in range(num_node): #遍历DI中的每个元素
if Dl[i] > 0:#若当前元素>0
Dn[i, i] = Dl[i]**(-1) #求逆后赋值为Dn的对角元素
#在st-gcn中卷积核返回为:A左乘Dn(实际上在图卷积过程中,使用的爱因斯坦求和策略中,已经把卷积核转换成(Dn^(-1))A)
AD = np.dot(A, Dn) #卷积核
return AD
其中D(-1)A为卷积核,在st-gcn的图卷积操作中,作者已经利用爱因斯坦求和约定表示把上述代码中返回的AD转为D(-1)A。
该代码在tgcn.py中,对应的代码段如下:
def forward(self, x, A):
assert A.size(0) == self.kernel_size
x = self.conv(x)
n, kc, t, v = x.size()
x = x.view(n, self.kernel_size, kc//self.kernel_size, t, v)
x = torch.einsum('nkctv,kvw->nctw', (x, A))
return x.contiguous(), A
copy.deepcopy()
深拷贝
- 将被复制对象完全再复制一遍作为独立的新个体单独存在。所以改变原有被复制对象不会对已经复制出来的新对象产生影响。(寻常意义的复制就是深复制)
- 而浅复制并不会产生一个独立的对象单独存在,他只是将原有的数据块打上一个新标签,所以当其中一个标签被改变的时候,数据块就会发生变化,另一个标签也会随之改变。这就和我们寻常意义上的复制有所不同了
self.config = copy.deepcopy(config)
E
torch.einsum()
爱因斯坦求和:给定两个矩阵A和B,我们想对它们做一些操作,比如 multiply、sum或者transpose等。虽然numpy里面有可以直接使用的接口,能够实现这些功能,但是使用enisum可以做的更快、更节省空间。
爱因斯坦求和 einsum
F
G
get_dummies()
实现one hot encode的方式
可以对Dataframe中字段类型是Object的列进行独热编码;一般会使特征的维度数增加;
在数据预处理阶段可能会用到该函数.主要思想是将一个分类变量多种取值(A、B、C……)的列,
替换多个列(列名为:A、B、C……),每一行的值从原来的A、B、C……变换为0或者1,
因为计算机更擅长处理0或1
get_config用于获取配置信息
工具类来读取配置文件中的配置参数
class Linear(keras.layers.Layer):
def __init__(self, units=32, **kwargs):
super(Linear, self).__init__(**kwargs)
self.units = units
def build(self, input_shape):
self.w = self.add_weight(
shape=(input_shape[-1], self.units),
initializer="random_normal",
trainable=True,
)
self.b = self.add_weight(
shape=(self.units,), initializer="random_normal", trainable=True
)
def call(self, inputs):
return tf.matmul(inputs, self.w) + self.b
def get_config(self):
config = super(Linear, self).get_config()
config.update({"units": self.units})
return config
layer = Linear(64)
config = layer.get_config()
print(config)
new_layer = Linear.from_config(config)
H
histc(scores, bins=self.args.bins)
进行直方图的统计,args.bins=16表示有16个区间
hist = torch.histc(scores, bins=self.args.bins)
I
items()
以列表返回可遍历的(键, 值) 元组数组
dict = {'1':'15岁',
'2':'14岁',
'3':'1岁',
}
print(dict.items())
for key,values in dict.items():
print(key + '已经' + values + '了')
===================================================
dict_items([('1', '15岁'), ('2', '14岁'), ('3', '1岁')])
1已经15岁了
2已经14岁了
3已经1岁了
isinstance
判断一个对象是否是一个已知的类型,类似 type()

J
os.path.join()
join()是连接字符串数组,而os.path.join()是将多个路径组合后返回
os.path.join()函数用于路径拼接文件路径。
os.path.join()函数中可以传入多个路径:
1.会从第一个以”/”开头的参数开始拼接,之前的参数全部丢弃。
2.以上一种情况为先。在上一种情况确保情况下,若出现”./”开头的参数,会从”./”开头的参数的上一个参数开始拼接。原文
还不懂看这个
import os
print("1:",os.path.join('aaaa','/bbbb','ccccc.txt'))
print("2:",os.path.join('/aaaa','/bbbb','/ccccc.txt'))
print("3:",os.path.join('aaaa','./bbb','ccccc.txt'))
1: /bbbb\ccccc.txt
2: /ccccc.txt
3: aaaa\./bbb\ccccc.txt
def save_ckpt(state, ckpt_path, is_best=True):
if is_best:
file_path = os.path.join(ckpt_path, 'ckpt_best.pth.tar')
torch.save(state, file_path)
else:
file_path = os.path.join(ckpt_path, 'ckpt_last.pth.tar')
torch.save(state, file_path)
K
L
load_state_dict()
加载模型:在Pytorch中构建好一个模型后,一般需要进行预训练权重中加载。torch.load_state_dict()函数就是用于将预训练的参数权重加载到新的模型之中
这两个不一样:
model.load_state_dict(ckpt['state_dict'])
optimizer.load_state_dict(ckpt['optimizer'])
MN
O
optimzer优化器模块
optimzer=optim.SGD(params=train_net.parameters(),#全部层可用参数
lr=0.01,#学习率
momentum=0.9,#梯度下降的动量,用于加速训练
weight_decay=le-4)#全衰量,防止过拟合
P
permute()
permute将tensor中任意维度利用索引调换。b=a.permute(2,0,1),permute里的参数对应的是张量a的维度索引,利用索引来对内部数据调换。
a.permute(2,0,1):把a的最后一个维度放到最前面(2对应的最后一个,位置发生了改变)。
parameters()
获取Module所保留的参数
for param in MyModel().parameters():
print(param)
nn.Parameter
通常,我们的参数都是一些常见的结构(卷积、全连接等)里面的计算参数。而当我们的网络有一些其他的设计时,会需要一些额外的参数同样很着整个网络的训练进行学习更新,最后得到最优的值。
Parameter实际上也是Tensor,也就是说是一个多维矩阵,是Variable类中的一个特殊类。当我们创建一个model时, parameter会自动累加到Parameter 列表中。(这样就可以自动计算梯度等)
与torch.Tensor的区别就是nn.Parameter会自动被认为是module的可训练参数,即加入到parameter()这个迭代器中去;而module中非nn.Parameter()的普通tensor是不在parameter中的。
## 导入库
import numpy as np
import torch
import torch.nn as nn
## 建立一个空间注意力层
class Spatial_Attention_layer(nn.Module):
def __init__(self, DEVICE, in_channels, num_of_vertices, num_of_timesteps):
super(Spatial_Attention_layer, self).__init__()
self.W1 = nn.Parameter(torch.FloatTensor(num_of_timesteps).to(DEVICE)) # (12)
self.W2 = nn.Parameter(torch.FloatTensor(in_channels, num_of_timesteps).to(DEVICE)) # (1, 12)
self.W3 = nn.Parameter(torch.FloatTensor(in_channels).to(DEVICE)) # (1)
self.bs = nn.Parameter(torch.FloatTensor(1, num_of_vertices, num_of_vertices).to(DEVICE)) # (1,307, 307)
self.Vs = nn.Parameter(torch.FloatTensor(num_of_vertices, num_of_vertices).to(DEVICE)) # (307, 307)
def reset_parameters(self):
# 初始化方法
for p in self.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p) # Xavier 初始化确保权重“恰到好处”
else:
nn.init.uniform_(p)
def forward(self, x):
'''
x(B,N,F,T)–-×W1(T,)–-> (B,N,F) —-×W2(F,T) –->lhs(B,N,T)
x(B,N,F,T)—- 转置 -–> x(B,T,N,F) —-×W3(F,) –->rhs(B,T,N)
product=lhs × rhs:(B,N,N)
'''
lhs = torch.matmul(torch.matmul(x, self.W1), self.W2)
rhs = torch.matmul(self.W3, x).transpose(-1, -2)
product = torch.matmul(lhs, rhs)
S = torch.matmul(self.Vs, torch.sigmoid(product + self.bs))
# normalization
S_normalized = F.softmax(S, dim=1) # (32, 307, 307)
return S_normalized
通过.parameters()获得model的parameter的迭代序列,不是真的List
self._encoder_pos_encodings = nn.Parameter(
encoder_pos_encodings, requires_grad=False)
self._decoder_pos_encodings = nn.Parameter(
decoder_pos_encodings, requires_grad=False)
self._mask_look_ahead = nn.Parameter(
mask_look_ahead, requires_grad=False)
tf.placeholder
tf.placeholder(
dtype,
shape=None,
name=None
)
参数:
dtype:数据类型。常用的是tf.float32,tf.float64等数值类型
shape:数据形状。默认是None,就是一维值,也可以是多维(比如[2,3], [None, 3]表示列是3,行不定)
name:名称
Tensorflow的设计理念称之为计算流图,在编写程序时,首先构筑整个系统的graph,代码并不会直接生效,这一点和python的其他数值计算库(如Numpy等)不同,graph为静态的,类似于docker中的镜像。然后,在实际的运行时,启动一个session,程序才会真正的运行。这样做的好处就是:避免反复地切换底层程序实际运行的上下文,tensorflow帮你优化整个系统的代码。我们知道,很多python程序的底层为C语言或者其他语言,执行一行脚本,就要切换一次,是有成本的,tensorflow通过计算流图的方式,帮你优化整个session需要执行的代码,还是很有优势的。
所以placeholder()函数是在神经网络构建graph的时候在模型中的占位,此时并没有把要输入的数据传入模型,它只会分配必要的内存。等建立session,在会话中,运行模型的时候通过feed_dict()函数向占位符喂入数据。
# tf Graph input
x = tf.placeholder(dtype=tf.float32, shape=[None, config.input_window_size - 1, config.input_size], name="input_sequence")
y = tf.placeholder(dtype=tf.float32, shape=[None, config.output_window_size, config.input_size], name="raw_labels")
dec_in = tf.placeholder(dtype=tf.float32, shape=[None, config.output_window_size, config.input_size], name="decoder_input")
labels = tf.transpose(y, [1, 0, 2])
labels = tf.reshape(labels, [-1, config.input_size])
labels = tf.split(labels, config.output_window_size, axis=0, name='labels')
# Define model
prediction = models.seq2seq(x, dec_in, config, True)
sess_config = tf.ConfigProto()
sess_config.gpu_options.allow_growth = True
sess_config.gpu_options.per_process_gpu_memory_fraction = 0.6
sess_config.allow_soft_placement = True
sess_config.log_device_placement = False
sess = tf.Session(config=sess_config)
Q
R
rpartition()
在最后一次出现参数字符串时分割字符串,并返回一个元组,其中包含部分前分隔符,参数字符串和后分隔符。
1:
string = "Python is fun"
print(string.rpartition('is '))
print(string.rpartition('not '))
string = "Python is fun, isn't it"
print(string.rpartition('is'))
输出:
('Python ', 'is ', 'fun')
('', '', 'Python is fun')
('Python is fun, ', 'is', "n't it")
==============================================================
2:
mod_str, _sep, class_str = import_str.rpartition('.')
rearrange
einops库中rearrange,reduce和repeat的介绍
rearrange: 用于对张量的维度进行重新变换排序,可用于替换pytorch中的reshape,view,transpose和permute等操作
def rearrange(inputs, pattern, **axes_lengths)⟶ transform_inputs
inputs (tensor): 表示输入的张量
pattern (str): 表示张量维度变换的映射关系
**axes_lengths: 表示按照指定的规格形式进行变换
def __init__(self, config):
self.config = copy.deepcopy(config)
super(siMLPe, self).__init__()
seq = self.config.motion_mlp.seq_len
self.arr0 = Rearrange('b n d -> b d n')
self.arr1 = Rearrange('b d n -> b n d')
S
set()
设置新的空对象的集合
self.global_labels = set()#新的空集合对象
同时也可去重
#通过set集合去重,global_labels记录去重之后的标签值(特征维度)
self.global_labels = self.global_labels.union(set(data["labels_1"]))
self.global_labels = self.global_labels.union(set(data["labels_2"]))
T
tf.transpose(input, [dimension_1, dimenaion_2,…,dimension_n])
这个函数主要适用于交换输入张量的不同维度用的,如果输入张量是二维,就相当是转置。dimension_n是整数,如果张量是三维,就是用0,1,2来表示。这个列表里的每个数对应相应的维度。如果是[2,1,0],就把输入张量的第三维度和第一维度交换。
import tensorflow as tf;
import numpy as np;
A = np.array([[1,2,3],[4,5,6]])
x = tf.transpose(A, [1,0])
B = np.array([[[1,2,3],[4,5,6]]])
y = tf.transpose(B, [2,1,0])
with tf.Session() as sess:
print A[1,0]
print sess.run(x[0,1])
print B[0,1,2]
print sess.run(y[2,1,0])
输出:
4
4
6
6
input_x = [
[
[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12]
],
[
[13, 14, 15, 16],
[17, 18, 19, 20],
[21, 22, 23, 24]
]
]
output1=tf.transpose(input_x,(1,0,2))
output1=
[
[
[ 1 2 3 4]
[13 14 15 16]
]
[
[ 5 6 7 8]
[17 18 19 20]
]
[
[ 9 10 11 12]
[21 22 23 24]
]
]
output2=tf.transpose(input_x,(0,2,1))#变成2*4*3
output2=[
[
[ 1 5 9]
[ 2 6 10]
[ 3 7 11]
[ 4 8 12]
]
[
[13 17 21]
[14 18 22]
[15 19 23]
[16 20 24]
]
]
np.triu()
对上下三角矩阵的操作:
np.triu([[1,2,3],[4,5,6],[7,8,9],[10,11,12]], -1)
>>>array([[ 1, 2, 3],
[ 4, 5, 6],
[ 0, 8, 9],
[ 0, 0, 12]])
np.triu([[1,2,3],[4,5,6],[7,8,9],[10,11,12]], 1)
>>>array([[0, 2, 3],
[0, 0, 6],
[0, 0, 0],
[0, 0, 0]])
np.triu([[1,2,3],[4,5,6],[7,8,9],[10,11,12]], 0)
>>>array([[1, 2, 3],
[0, 5, 6],
[0, 0, 9],
[0, 0, 0]])
def get_subsequent_mask(seq):
''' For masking out the subsequent info. '''
sz_b, len_s, *_ = seq.size()
subsequent_mask = (1 - torch.triu(
torch.ones((1, len_s, len_s), device=seq.device), diagonal=1)).bool()
return subsequent_mask
U
V
view(-1, 1)
表示多少行不确定,但是有1列,对out进行reshape,reshape成1列,行数由列数决定(-1那里原本的数不变)
如果你不知道你想要多少行,但确定列数,那么你可以将行数设置为-1(你可以将它扩展到具有更多维度的张量。只有一个轴值可以是-1)。这是告诉系统Library:给我一个具有这么多列的张量,并计算实现这一点所需的适当行数
#view(-1, 1)表示多少行不确定,但是有1列
sigmoid_scores = torch.sigmoid(torch.mm(embedding,transformed_global.view(-1, 1)))
变成多阶见:pytorch:深入理解 reshape(), view(), transpose(), permute() 函数
x=x.view(-1,288)
#将x拉伸为长度为288的向量
val
训练过程中的train,val,test的区别
#训练过程中的测试集的数据加载器
val_loader = DataLoader(
dataset=val_dataset,
batch_size=opt.test_batch,
shuffle=False,
num_workers=opt.job,
pin_memory=True)
W
X
init.xavier_uniform()讲解
为了使得网络中信息更好的流动,每一层输出的方差应该尽量相等。
Xavier初始化的实现就是下面的均匀分 :原论文
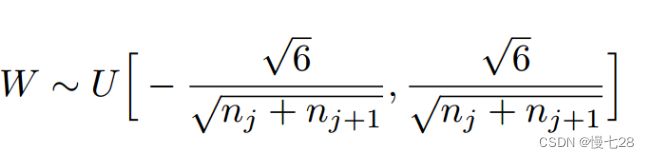
uniform_
以下划线结尾的是inplace方法 详情
A.uniform_(-10,20)
将会把A里面的每个值都从[-10, 20]里面重新随机取一次,即在[-10, 20]的随机均匀分布里面取值并重新赋值
def reset_parameters(self):
stdv = math.sqrt(6.0 / (self.weight.size(0) + self.weight.size(1)))
self.weight.data.uniform_(-stdv, stdv)
self.att.data.uniform_(-stdv, stdv)
if self.bias is not None:
self.bias.data.uniform_(-stdv, stdv)
Y
Z
zero_grad
梯度清零(通常让优化器)
from torch import optim
#构建优化器
optimizer=optim.SGD(lr_model.parameters(),lr=0.03)
#迭代对模型进行训练
batch_size=10
iters=10
for _ in range(iters):
for i in range(int(len(x)/batch_size)):
input=x[i*batch_size:(i+1)*batch_size]
target=y[i*batch_size:(i+1)*batch_size]
#调用优化器zero_grad()方法清空参数梯度
optimizer.zero_grad()
output=lr_model(input)
l=loss(output,target)
#计算模型的梯度
l.backward()
#更新模型参数
optimizer.step()