Modality-Adaptive Mixup and Invariant Decomposition for RGB-Infrared Person Re-Identification(逐句分析)
Modality-Adaptive Mixup and Invariant Decomposition for RGB-Infrared Person Re-Identification(可见光—红外行人重识别的模态自适应混合和不变分解)
期刊:AAAI 2022
文章来源:https://ojs.aaai.org/index.php/AAAI/article/view/19987
研究动机
可见光—红外行人重识别是一项新兴的跨模态重识别任务,由于RGB和红外图像之间存在显著的模态差异,具有极大挑战性。文章提出了一种新的模态自适应混合和不变分解(MID),以学习模态不变和鉴别特征。首先,MID设计了一种模态自适应混合方案(MAM),以根据不同RGB和IR图像之间的动态外观和模态差异,生成适当的混合模态图像,并在像素级协调模态间隙。还采用了模态自适应卷积分解(MACD)来同时对抗模态差异,并在特征级别强制跨模态共享语义,以促进跨模态特征学习。
ps:与传统的单模态人员Re-ID相比,除了外观差异外,跨模态遇到了由不同光谱相机之间的不同成像过程(RGB和红外图像本质上是异质的,具有不同的波长范围)引起的显著模态差异。RGB红外人员Re-ID的关键解决方案是弥合大的模态差距,并从RGB和IR图像中学习模态不变和鉴别特征。
实现

混合(Mixup)是一种新兴的数据增强方案,通过样本对及其标签之间的全局和随机线性插值来正则化深度学习模型,在域自适应中起着重要的作用。
文章在利用混合技术的基础上提出了一种新的用于RGB—红外行人Re-ID的模态自适应混合和不变分解(MID)方法。
具体流程
第一部分(图上半部分)
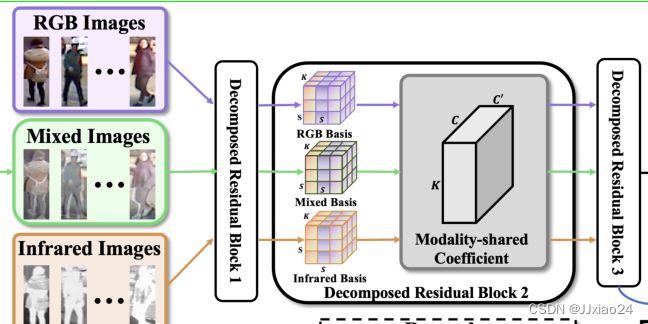
MID首先采用模态自适应混合方案来合成RGB和IR图像之间的增强混合模态图像(Mixed Images)。然后将三个模态图像馈送到分解的卷积网络中,以学习模态不变和判别特征,这被称为F。F中的前三个残差块(Decomposed Residual Block 1-3)被表示为F1,其配备有设计的模态自适应卷积分解(MACD),用于吸收模态变化并在模态之间对齐不变语义信息。
模态自适应混合方案
Mixup是一种可行的数据增强算法,它通过样本对及其标签之间的线性插值来正则化深度学习模型。但不能直接应用在跨模态任务,以在像素级有效协调RGB和IR模态。混合方案通过简单的全局和随机线性插值策略生成虚拟的样本,内插两个样本的混合比是一个标量,并从具有超参数α的Beta(α,α)分布中随机采样。由于不同RGB和IR图像之间的模态间差异显著,随机混合比可能产生低质量的混合模态图像,该图像与相同身份的真实RGB和红外图像不相邻,从而导致多种入侵问题。此外,由于数据集中缺少同一个人的成对RGB和IR图像,加上具有较大的模态内变化,用全局插值RGB和红外图像的标量混合比的方法可能会破坏混合模态图像的视觉语义和身份信息,从而导致识别性能下降。
为了解决上述问题,使用模态自适应混合方案,以在像素级弥合模态差异。它以数据相关的方式学习跨模态图像的不同区域之间的动态和局部线性插值,该插值被表述为马尔可夫决策过程,并由演员-批评家在深度强化学习(RL)框架下实施。
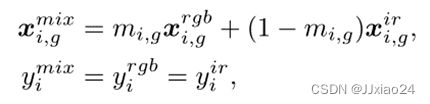
其中mi,g∈ [0,1]是从网络中学习的混合比率,沿着水平轴分别被划分为G局部区域,如下所示。 代表的是共享相同的身份信息。

混合比率基于RGB和IR图像的相应局部区域之间的模态和外观差异动态调整,这由演员-评论家代理执行。使用代理中的演员网络A来估计混合比mi,而代理中的评论家网络Q预测状态动作值(Qvalue)。A的公式如下:
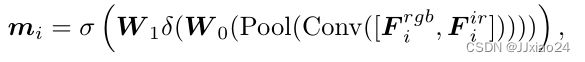
σ和δ分别表示S形函数和校正线性单元(ReLU)激活函数。W0和W1表示两个完全连接(FC)层。Conv表示3×3卷积层,随后是批处理归一化层和ReLU层。池表示全局平均池层。
模态自适应卷积分解
为了克服基于流网络在提取模态特定特征时削弱了重要的跨模态共享语义的问题,提出了模态自适应卷积分解的方法。

W表示卷积层的卷积滤波器S×S×Cin×Cout,其中S是滤波器的空间大小,Cin和Cout表示输入信道和输出信道的数量。文章将W分解为模态特定的字典基α∈ RS×S×K和模态公共系数Ψ∈ RK×Cin×Cout,就是每个分解卷积层具有三个独立的模态特定字典基αrgb、αir、αmix和模态间的公共系数Ψ。
第二部分(图下半部分)
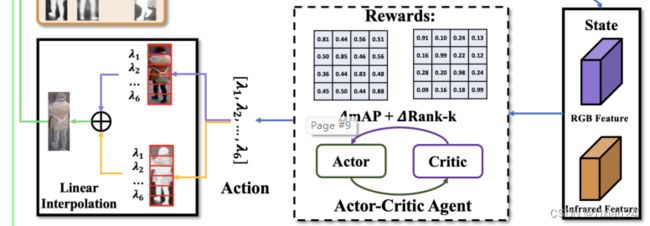
与标准的增强学习算法不同,演员-评论家代理在不同的训练步骤中没有明确的顺序关系。RGB和IR图像之间的插值策略的动作以一次拍摄的方式取决于其中间特征的状态,这本质上是一个Markov(马尔可夫)决策的过程。因为动作空间是连续的,因此可以通过梯度上升法,在连续Q值预测的结果之后找到最佳动作。演员—评论家网络的损失定义如下:

优化Q值越高,意味着Rank-1精度和mAP也会上升,网络被优化以预测准确的Q值估计,因此MSE Loss被采用如下:

结合了监督学习和强化学习的优点,交替优化分解卷积网络和演员-评论家代理。
为了指导评论家网络预测混合比的可靠性,设计了奖励作为优化的监督信号。代理人的行为、状态和报酬定义如下
状态:从F1提取的rgb和IR图像的中间特征图 ![]() 的拼接被视为代理的状态。
的拼接被视为代理的状态。
行为:混合比 ![]() 用于RGB和IR图像之间的线性插值,它是一个连续向量。
用于RGB和IR图像之间的线性插值,它是一个连续向量。
奖赏:RGB和IR图像之间的相似度矩阵 ,以及所有混合模态和IR图像间的
,以及所有混合模态和IR图像间的 ![]() ,其中fi表示从分解卷积网络f学习的行人表示。
,其中fi表示从分解卷积网络f学习的行人表示。 ![]() 表示余弦距离,奖励被定义为通过使用混合模态图像来增强相似度矩阵来重新识别的相对性能改进,其公式如下:
表示余弦距离,奖励被定义为通过使用混合模态图像来增强相似度矩阵来重新识别的相对性能改进,其公式如下:
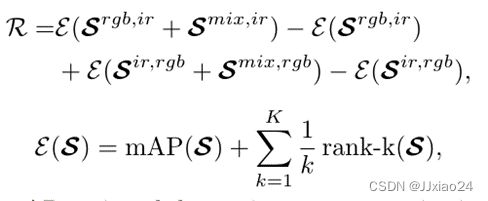
第三部分(图右端)

利用识别损失和中心三元组损失对分解的卷积网络进行优化,以便重新识别。
识别损失:
其中P是训练集中的身份数,y是真实ID,pi表示第i类的身份预测逻辑。ξ是平滑参数,有利于防止网络过度拟合训练ID。三种模态损失监督各自的特征。
中心三元组损失: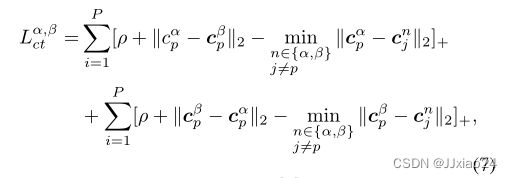
ρ为间隔参数,α, β ∈ {rgb,ir,mix},用于表示两种不同的模态。
文章提出随机采样RGB和IR模态的P个身份和每个身份的K个图像,以形成一个小批量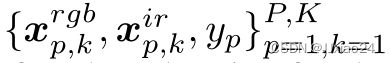
并在小批量中为三个模态图像计算每个行人的特征中心,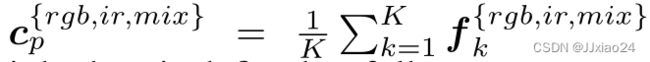
那么,就可以得到分解卷积网络的总损失Ldcn为:
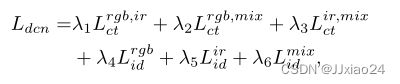
其中λ1−6是权衡参数。后文会给出各个数值(间隔参数ρ设置为0.3,参数µ和ξ分别设置为1和0.1,权衡参数λ1,4,5设置为1,λ2,3设置为0.5,λ6设置为0。)
创新点
-
提出了一种新的模态自适应混合和不变性分解(MID),以学习模态不变性和鉴别表示。
-
提出了一种模态自适应混合方案(MAM),以生成合适的混合模态样本,用于在像素级协调RGB和IR模态。
-
设计了一种模态自适应卷积分解(MACD),以捕获不变的视觉语义,并在特征级别缩小模态差异。
结果
在SYSU_MM01跟RegDB数据集评估指标。
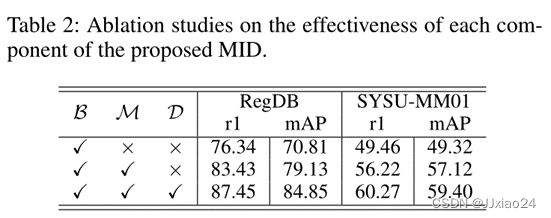
 MID在不同的测试模式下实现了最佳的性能,对于“对热可见”模式,MID达到87.45%的Rank-1准确度和84.85%的mAP。MID在所有搜索和室内设置下都获得了最佳性能,对于所有搜索模式,MID达到了60.27%。
MID在不同的测试模式下实现了最佳的性能,对于“对热可见”模式,MID达到87.45%的Rank-1准确度和84.85%的mAP。MID在所有搜索和室内设置下都获得了最佳性能,对于所有搜索模式,MID达到了60.27%。
交融实验
结论
在这项工作中,文章提出了一种用于RGB—红外行人重识别的一种新的模态自适应混合和不变分解(MID)方法,以减轻RGB和IR图像在像素级和特征级的固有模态差异。MID首先引入了模态自适应混合方案(MAM),以由演员-评论家代理生成适当的混合模态图像,以减少像素级的模态间隙,并促进更连续的模态不变潜在空间。然后,MID设计了模态自适应卷积分解,以同时对抗模态差异,并在特征级别强制跨域共享语义,以学习有效的模态共享表示。在两个跨模态人物再识别数据集上的实验结果证明了该方法的优越性。