自然语言处理之RNN
自然语言处理之RNN
- 一、循环神经网络( Recurrent Neural Network, RNN)
-
- 1.1 全连接神经网络弊端,引出RNN
- 1.2 循环神经网络RNN
- 1.2 循环神经网络RNN训练方法
- 1.3 循环神经网络RNN的多种类型任务
-
- 1.3.1 one-to-one
- 1.3.2 one-to-n
- 1.3.3 n-to-n
- 1.3.4 n-to-one
- 1.3. 5 n-to-m
- 1.4 BiRNN:双向RNN
- 1.5 DRNN:深层RNN
一、循环神经网络( Recurrent Neural Network, RNN)
1.1 全连接神经网络弊端,引出RNN
对于下图所示的全连接神经网络来说,输入层每一个节点接收一个特征输入,输入的节点与隐藏层的各个节点相连,隐藏层节点与输出层节点相连,但存在的问题是各层内部的节点之间相互独立,即每一次的输入与上一时刻的输入没有关联,这样不能很好的处理序列信息,如一 段连续的信息,前后信息之间是有关系地,必须将不同时刻的信息放在一起理解。比如一句话,虽然可以拆分成多个词语,但是需要将这些词语连起来理解才能得到一句话的意思。
为解决这一问题,循环神经网络应运而生了。
1.2 循环神经网络RNN

- 对于上图中的右图,参数解释:
1) X t X_t Xt是 t t t时刻的输入,是一个 [ x 1 , x 2 , . . . , x n ] [x_1, x_2,...,x_n] [x1,x2,...,xn]的向量;
2) U U U是输入层到隐藏层的权重矩阵;
3) S t S_t St是 t t t时刻隐藏层的值;
4) W W W是上一时刻的隐藏层的值传入到下一时刻的隐藏层时的权重矩阵;
5) V V V是隐藏层到输出层的权重矩阵;
6) O t O_t Ot是 t t t时刻RNN网络的输出值。
上图中可以看出, S t S_t St不仅与 X t X_t Xt有关,还与 t − 1 t-1 t−1时刻的隐藏层的值 S t − 1 S_{t-1} St−1有关。隐藏层的循环操作就是每一时刻计算一个隐藏层地值,然后再把该隐藏层的值传入到下一时刻,达到信息传递的目的。 - 隐藏层值 S t S_t St的计算公式如下:
S t = f ( U ∗ X t + W ∗ S t − 1 + b ) (1) S_t=f(U*X_t+W*S_{t-1}+b)\tag{1} St=f(U∗Xt+W∗St−1+b)(1)
上式中 f ( ) f() f()是激活函数,一般选用 t a n h tanh tanh。 - 输出层的值为:
O t = g ( V ∗ S t ) (2) O_t=g(V*S_t)\tag{2} Ot=g(V∗St)(2)
上式中 g ( ) g() g()是激活函数,RNN网络的输出值,如果是二分类采用 s i g m o i d sigmoid sigmoid,多分类则采用 s o f t m a x softmax softmax。 - RNN的参数共享:在同一层隐藏层中,不同时刻的W,V,U均是相等地。
- 对于 X t − 1 X_{t-1} Xt−1、 X t X_t Xt和 X t + 1 X_{t+1} Xt+1是表示不同时刻的输入,他们在输入时不是单个向量一个一个的输入,而是组合形成一个矩阵输入,然后通过权值 U U U变化。
1.2 循环神经网络RNN训练方法
- 训练RNN常用的一种方法是 BPTT算法(back-propagation through time),其本质也是BP算法(Backpropagation Algorithm),BP算法的本质其实又是梯度下降法。
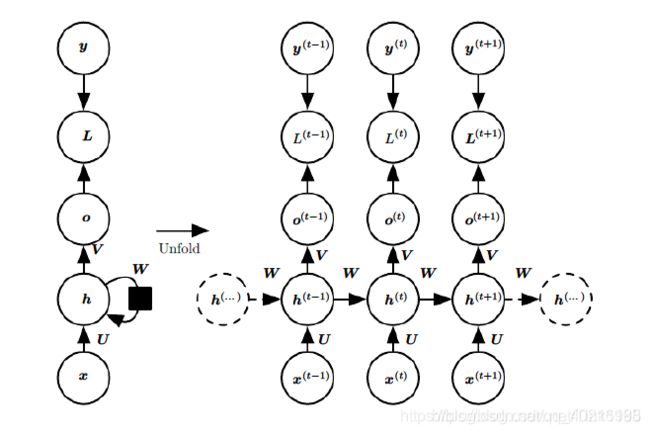
- 上图是带入了RNN 损失函数Loss的按时间线结构展开图。ht相当于是之前介绍过的隐藏层的值St。在RNN的训练调参过程中,需要调优的参数只有W,U,V三个。
O t = g ( V ∗ h t ) (3) O_t=g(V*h_t)\tag{3} Ot=g(V∗ht)(3)
对 V V V的偏导为:
∂ L ( t ) ∂ V = ∂ L ( t ) ∂ o ( t ) ⋅ ∂ o ( t ) ∂ V (4) \frac{\partial L^{(t)}}{\partial V}=\frac{\partial L^{(t)}}{\partial o^{(t)}}·\frac{\partial o^{(t)}}{\partial V}\tag{4} ∂V∂L(t)=∂o(t)∂L(t)⋅∂V∂o(t)(4)
RNN的损失函数随时间累加的,所以需要求 L L L对 V V V的偏导数:
L = ∑ t = 1 n L ( t ) (5) L=\sum_{t=1}^nL^{(t)}\tag{5} L=t=1∑nL(t)(5)
∂ L ∂ V = ∑ t = 1 n ∂ L ( t ) ∂ o ( t ) ⋅ ∂ o ( t ) ∂ V (6) \frac{\partial L}{\partial V}=\sum_{t=1}^n\frac{\partial L^{(t)}}{\partial o^{(t)}}·\frac{\partial o^{(t)}}{\partial V}\tag{6} ∂V∂L=t=1∑n∂o(t)∂L(t)⋅∂V∂o(t)(6)
h t h_t ht的计算公式为:
h t = f ( U ⋅ X t + W ⋅ h t − 1 + b ) (7) h_t=f(U·X_t+W·h_{t-1}+b)\tag{7} ht=f(U⋅Xt+W⋅ht−1+b)(7)
由于 h t h_t ht与 h t − 1 h_{t-1} ht−1都与 W , U W, U W,U有关,所以对 W , U W, U W,U求偏导时需要涉及到所有历史时刻的数据,先假设目前只有3个时刻,那么在第三个时刻,即 t = 3 t=3 t=3时, L ( 3 ) L^{(3)} L(3)对 W , U W, U W,U的偏导数分别为:
∂ L ( 3 ) ∂ W = ∂ L ( 3 ) ∂ o ( 3 ) ⋅ ∂ o ( 3 ) ∂ h ( 3 ) ⋅ ∂ h ( 3 ) ∂ W + ∂ L ( 3 ) ∂ o ( 3 ) ⋅ ∂ o ( 3 ) ∂ h ( 3 ) ⋅ ∂ h ( 3 ) ∂ h ( 2 ) ⋅ ∂ h ( 2 ) ∂ W + ∂ L ( 3 ) ∂ o ( 3 ) ⋅ ∂ o ( 3 ) ∂ h ( 3 ) ⋅ ∂ h ( 3 ) ∂ h ( 2 ) ⋅ ∂ h ( 2 ) ∂ h ( 1 ) ⋅ ∂ h ( 1 ) ∂ W (8) \frac{\partial L^{(3)}}{\partial W}=\frac{\partial L^{(3)}}{\partial o^{(3)}}·\frac{\partial o^{(3)}}{\partial h^{(3)}}·\frac{\partial h^{(3)}}{\partial W}+\frac{\partial L^{(3)}}{\partial o^{(3)}}·\frac{\partial o^{(3)}}{\partial h^{(3)}}·\frac{\partial h^{(3)}}{\partial h^{(2)}}·\frac{\partial h^{(2)}}{\partial W}+\frac{\partial L^{(3)}}{\partial o^{(3)}}·\frac{\partial o^{(3)}}{\partial h^{(3)}}·\frac{\partial h^{(3)}}{\partial h^{(2)}}·\frac{\partial h^{(2)}}{\partial h^{(1)}}·\frac{\partial h^{(1)}}{\partial W}\tag{8} ∂W∂L(3)=∂o(3)∂L(3)⋅∂h(3)∂o(3)⋅∂W∂h(3)+∂o(3)∂L(3)⋅∂h(3)∂o(3)⋅∂h(2)∂h(3)⋅∂W∂h(2)+∂o(3)∂L(3)⋅∂h(3)∂o(3)⋅∂h(2)∂h(3)⋅∂h(1)∂h(2)⋅∂W∂h(1)(8)
∂ L ( 3 ) ∂ U = ∂ L ( 3 ) ∂ o ( 3 ) ⋅ ∂ o ( 3 ) ∂ h ( 3 ) ⋅ ∂ h ( 3 ) ∂ U + ∂ L ( 3 ) ∂ o ( 3 ) ⋅ ∂ o ( 3 ) ∂ h ( 3 ) ⋅ ∂ h ( 3 ) ∂ h ( 2 ) ⋅ ∂ h ( 2 ) ∂ U + ∂ L ( 3 ) ∂ o ( 3 ) ⋅ ∂ o ( 3 ) ∂ h ( 3 ) ⋅ ∂ h ( 3 ) ∂ h ( 2 ) ⋅ ∂ h ( 2 ) ∂ h ( 1 ) ⋅ ∂ h ( 1 ) ∂ U (9) \frac{\partial L^{(3)}}{\partial U}=\frac{\partial L^{(3)}}{\partial o^{(3)}}·\frac{\partial o^{(3)}}{\partial h^{(3)}}·\frac{\partial h^{(3)}}{\partial U}+\frac{\partial L^{(3)}}{\partial o^{(3)}}·\frac{\partial o^{(3)}}{\partial h^{(3)}}·\frac{\partial h^{(3)}}{\partial h^{(2)}}·\frac{\partial h^{(2)}}{\partial U}+\frac{\partial L^{(3)}}{\partial o^{(3)}}·\frac{\partial o^{(3)}}{\partial h^{(3)}}·\frac{\partial h^{(3)}}{\partial h^{(2)}}·\frac{\partial h^{(2)}}{\partial h^{(1)}}·\frac{\partial h^{(1)}}{\partial U}\tag{9} ∂U∂L(3)=∂o(3)∂L(3)⋅∂h(3)∂o(3)⋅∂U∂h(3)+∂o(3)∂L(3)⋅∂h(3)∂o(3)⋅∂h(2)∂h(3)⋅∂U∂h(2)+∂o(3)∂L(3)⋅∂h(3)∂o(3)⋅∂h(2)∂h(3)⋅∂h(1)∂h(2)⋅∂U∂h(1)(9)
所以对于 W , U W,U W,U的偏导数通式为:
∂ L ( t ) ∂ W = ∑ k = 0 n ∂ L ( t ) ∂ o ( t ) ∂ o ( t ) ∂ h ( t ) ( ∏ j = k + 1 n ∂ h ( j ) ∂ h ( j − 1 ) ) ∂ h ( k ) ∂ W (10) \frac{\partial L^{(t)}}{\partial W}=\sum_{k=0}^n\frac{\partial L^{(t)}}{\partial o^{(t)}}\frac{\partial o^{(t)}}{\partial h^{(t)}}(\prod_{j=k+1}^n\frac{\partial h^{(j)}}{\partial h^{(j-1)}})\frac{\partial h^{(k)}}{\partial W}\tag{10} ∂W∂L(t)=k=0∑n∂o(t)∂L(t)∂h(t)∂o(t)(j=k+1∏n∂h(j−1)∂h(j))∂W∂h(k)(10)
∂ L ( t ) ∂ U = ∑ k = 0 n ∂ L ( t ) ∂ o ( t ) ∂ o ( t ) ∂ h ( t ) ( ∏ j = k + 1 n ∂ h ( j ) ∂ h ( j − 1 ) ) ∂ h ( k ) ∂ U (11) \frac{\partial L^{(t)}}{\partial U}=\sum_{k=0}^n\frac{\partial L^{(t)}}{\partial o^{(t)}}\frac{\partial o^{(t)}}{\partial h^{(t)}}(\prod_{j=k+1}^n\frac{\partial h^{(j)}}{\partial h^{(j-1)}})\frac{\partial h^{(k)}}{\partial U}\tag{11} ∂U∂L(t)=k=0∑n∂o(t)∂L(t)∂h(t)∂o(t)(j=k+1∏n∂h(j−1)∂h(j))∂U∂h(k)(11) - 对于隐藏层的激活函数,为什么选择 t a n h tanh tanh?
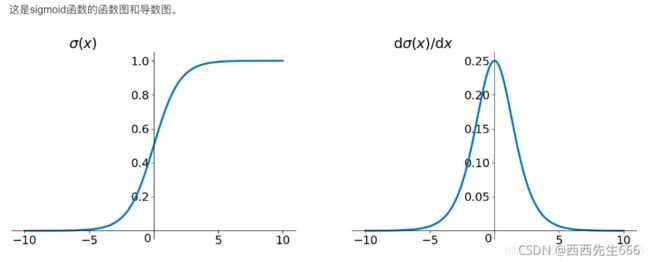
1)sigmoid函数:
f ( x ) = 1 1 + e − x (12) f(x)=\frac{1}{1+e^{-x}}\tag{12} f(x)=1+e−x1(12)
导数为:
f ′ ( x ) = f ( x ) ( 1 − f ( x ) ) (13) f'(x)=f(x)(1-f(x))\tag{13} f′(x)=f(x)(1−f(x))(13)
2)tanh函数:
t a n h ( x ) = e x p ( x ) − e x p ( − x ) e x p ( x ) + e x p ( − x ) (14) tanh(x)=\frac{exp(x)-exp(-x)}{exp(x)+exp(-x)}\tag{14} tanh(x)=exp(x)+exp(−x)exp(x)−exp(−x)(14)
导数为:
t a n h ′ ( x ) = 1 − t a n h 2 ( x ) (14) tanh'(x)=1-tanh^2(x)\tag{14} tanh′(x)=1−tanh2(x)(14)
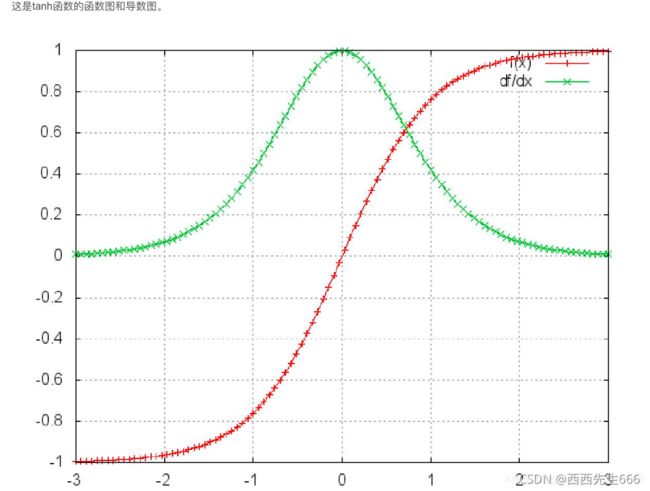
- sigmoid函数的导数介于 [ 0 , 0.25 ] [0,0.25] [0,0.25]之间,tanh函数的导数介于 [ 0 , 1 ] [0,1] [0,1]之间,导数都小于1,将众多小于1的数连乘时,虽然二者都会出现出现梯度消失,但tanh比sigmoid函数表现的要好,梯度消失的没那么快。
- 其实在RNN中使用ReLU函数确实也是能解决梯度消失的问题地,但是又会引入一个新问题梯度爆炸,先看看ReLU函数和其导数图:
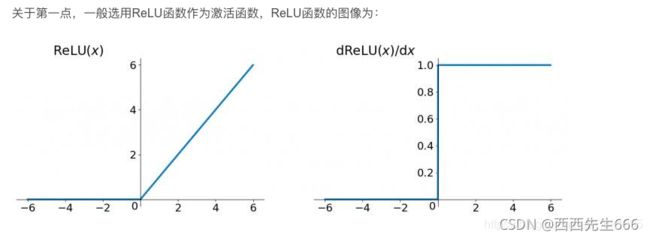
因为ReLu的导数恒为1,由上面的公式我们发现
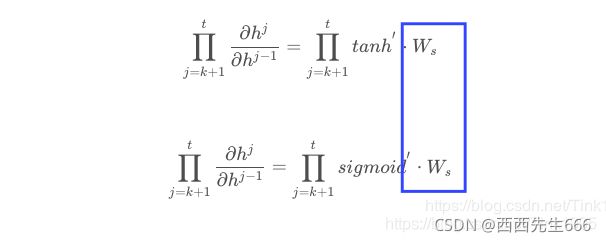
激活函数的导数每次需要乘上一个Ws,只要Ws的值大于1的话,经过多次连乘就会发生梯度爆炸的现象。但是这里的梯度爆炸问题也不是不能解决,可以通过设定合适的阈值解决梯度爆炸的问题。 - 目前大家在解决梯度消失问题地时候一般都会选择使用LSTM这一RNN的变种结构来解决梯度消失问题,而LSTM的激活函数又是选择的tanh,还不会引入梯度爆炸这种新问题。
1.3 循环神经网络RNN的多种类型任务
1.3.1 one-to-one

- 输入的是独立地数据,输出的也是独立地数据,基本上不能算作是RNN,跟全连接神经网络没有什么区别。
1.3.2 one-to-n
- 输入的是一个独立数据,需要输出一个序列数据,常见的任务类型有:
基于图像生成文字描述
基于类别生成一段语言,文字描述
1.3.3 n-to-n

- 最为经典地RNN任务,输入和输出都是等长地序列
- 常见的任务有:
计算视频中每一帧的分类标签
输入一句话,判断一句话中每个词的词性
1.3.4 n-to-one

- 输入一段序列,最后输出一个概率,通常用来处理序列分类问题。
- 常见任务:
文本情感分析
文本分类
1.3. 5 n-to-m

- 输入序列和输出序列不等长地任务,也就是Encoder-Decoder结构,这种结构有非常多的用法:
机器翻译:Encoder-Decoder的最经典应用,事实上这结构就是在机器翻译领域最先提出的
文本摘要:输入是一段文本序列,输出是这段文本序列的摘要序列
阅读理解:将输入的文章和问题分别编码,再对其进行解码得到问题的答案
语音识别:输入是语音信号序列,输出是文字序列
1.4 BiRNN:双向RNN
虽然RNN达到了传递信息的目的,但是只是将上一时刻的信息传递到了下一时刻,也就是只考虑到了当前节点前的信息,没有考虑到该节点后的信息。具体到NLP中,也就是一句话,不仅要考虑某个词上文的意思,也还要考虑下文的意思,这个时候普通的RNN就做不到了。于是就有了双向RNN(Bidirectional RNN)。
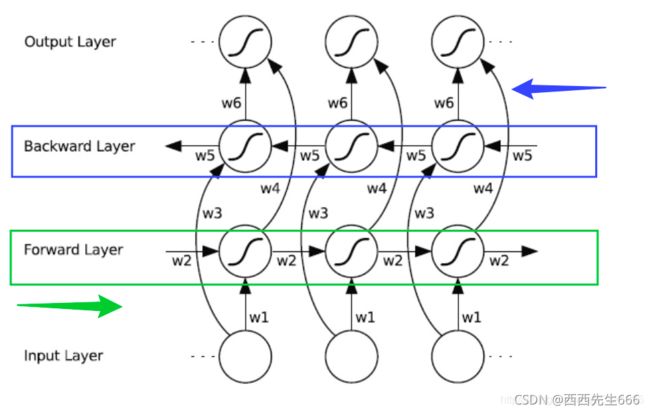
上面是BiRNN的结构图,蓝框和绿框分别代表一个隐藏层,BiRNN在RNN的基础上增加了一层隐藏层,这层隐藏层中同样会进行信息传递,两个隐藏层值地计算方式也完全相同,只不过这次信息不是从前往后传,而是从后往前传,这样不仅能考虑到前文的信息而且能考虑到后文的信息了。
实现起来也很简单,比如一句话,“我爱NLP”,进行分词后是[“我”,“爱”,“NLP”],输入[[“我”],[“爱”],[“NLP”]],计算forward layer隐藏层值,然后将输入数据翻转成[[“NLP”],[“爱”],[“我”]],计算backward layer 隐藏层值,然后将两个隐藏层的值进行拼接,再输出就行啦。
1.5 DRNN:深层RNN

上图是DRNN的结构图,很简单,每一个红框里面都是一个BiRNN,然后一层BiRNN的输出值再作为另一个BiRNN的输入。多个BiRNN堆叠起来就成了DRNN。