一些论文阅读的日常记录
一、
基于非局部相似模型的压缩感知图像恢复算法
沈燕飞 李锦涛 朱珍民 张勇东 代锋
【摘要】:针对压缩感知(Compressed sensing,CS)图像恢复问题,提出了一种基于非局部相似模型的压缩感知恢复算法,该算法将传统意义上二维图像块的稀疏性扩展到相似图像块组在三维空间上的稀疏性,在提高图像表示稀疏度的同时进一步提高了压缩感知图像恢复效率,恢复图像在纹理和结构保持方面都得到了很大的提升.在该算法模型求解过程中,使用增广拉格朗日方法将受限优化问题转换为非受限优化问题,为减少计算复杂度,还使用了基于泰勒展开的线性化技术来加速算法求解.实验结果表明,该算法的图像恢复性能优于目前主流的压缩感知图像恢复算法.【作者单位】: 中国科学院计算技术研究所;北京市移动计算与新型终端重点实验室;
【关键词】: 压缩感知 图像恢复 非局部相似 稀疏表示
【基金】:国家自然科学基金(61327013,61471343) 中国科学院科研装备研制项目(YZ201321)资助~~
非局部相似模型早在近十年前就已经出现的算法,竟说是创新,把我这个压缩感知方面的小白骗得好苦,and,也说不清非局部相似是如何融合在稀疏编码的字典中的,说不明白,这个怨自己没读明白文章。
二、
Deep learning for class-generic object detection
Brody Huval, Adam Coates, Andrew Ng (三个大牛好崇拜)
(Submitted on 24 Dec 2013)
We investigate the use of deep neural networks for the novel task of class generic object detection. We show that neural networks originally designed for image recognition can be trained to detect objects within images, regardless of their class, including objects for which no bounding box labels have been provided. In addition, we show that bounding box labels yield a 1% performance increase on the ImageNet recognition challenge.
Subjects: Computer Vision and Pattern Recognition (cs.CV); Learning (cs.LG); Neural and Evolutionary Computing (cs.NE)
Cite as: arXiv:1312.6885 [cs.CV]
(or arXiv:1312.6885v1 [cs.CV] for this version)
冲着吴恩达三个字下载的,很简短,论文中几乎没有实验过程,对基于深度学习的目标检测算法进行了简单的的的概述,尤其是一种弱标记的训练,尤其是没有bound rect的样本进行训练,很是好奇。
13年的一篇短论文,实验介绍并不详细,结论中有这么几个创新的地方:
1:同时利用了类和标记框(bounding box)的信息
2:能推广到发现新类,即训练中没有用bounding box标注的新物体类(这个很神奇有木有)
3:在recognition方面(而不是detection方面)的ImageNet挑战上发挥出色,实验是硬道理!
三、
Microsoft COCO: Common Objects in ContextTsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir
Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva Ramanan, C. Lawrence Zitnick, Piotr Dollár
(Submitted on 1 May 2014 (v1), last revised 21 Feb 2015 (this version, v3))
We present a new dataset with the goal of advancing the state-of-the-art in object recognition by placing the question of object recognition in the context of the broader question of scene understanding. This is achieved by gathering images of complex everyday scenes containing common objects in their natural context. Objects are labeled using per-instance segmentations to aid in precise object localization. Our dataset contains photos of 91 objects types that would be easily recognizable by a 4 year old. With a total of 2.5 million labeled instances in 328k images, the creation of our dataset drew upon extensive crowd worker involvement via novel user interfaces for category detection, instance spotting and instance segmentation. We present a detailed statistical analysis of the dataset in comparison to PASCAL, ImageNet, and SUN. Finally, we provide baseline performance analysis for bounding box and segmentation detection results using a Deformable Parts Model.
Comments: 1) updated annotation pipeline description and figures; 2) added new section describing datasets splits; 3) updated author list
Subjects: Computer Vision and Pattern Recognition (cs.CV)
Cite as: arXiv:1405.0312 [cs.CV]
(or arXiv:1405.0312v3 [cs.CV] for this version)
Submission historyFrom: Piotr Dollár [view email]
[v1] Thu, 1 May 2014 21:43:32 GMT (6986kb,D)
[v2] Sat, 5 Jul 2014 18:39:56 GMT (7484kb,D)
[v3] Sat, 21 Feb 2015 01:48:49 GMT (7891kb,D)
在环境中的普通目标识别,2014的文,15年刊登,实验相近,最终不光用bounding box标记物体,还能识别物体曲折的边界,融合了物体分割的相关方法,6
无人机侦察效能研究
王庆江,彭军等,2015,火力与指挥控制,海军航空工程学院
摘要:
给出无人机及侦察设备模型的基础上,从无人机侦察能力,侦察代价建立效能评估模型。解决了侦察方案优劣评价问题。
无人机:六自由度的空间点。传感器:CCD 摄像机。
1,无人机侦察能力W1:
W = f(f发现目标概率、m对目标的漏扫率、d系统性能概率)
d与系统发现目标概率、地形地貌导致目标是否在可发现区域(有无被障碍物遮挡)有关
m指无人机飞行、转弯等过程漏扫的区域
d指由于系统、环境的风雨雾原因,本该被扫描到但是却没有
2无人机侦察代价W2:
总飞行长度代价、油料代价、时间代价、禁飞区、防空武器等威胁代价
平直区域油料、时间是长度的函数,防空区要做规避动作,则该函数会变化
3、侦察效能的评估
在多种方案中找出最优。F = K1 * W1 -K2 *W2 (无力吐嘈作者,如此简单的建模)
要将规定区域扫面完毕,可用螺旋型、扫描线型多种航线完成、每种的漏扫区域不一样。考虑误差,手工设定以上参数,进行仿真运算。
个人评价:
垃圾论文,浪费我时间来写论文笔记。
基于LMBP神经网络的声诱饵对抗鱼雷效能评估
陈军,王汝,2008,鱼雷技术,西北工业大学
摘要:
建立声诱饵对抗雷达效能评估指标体系。结合专家调查法、仿真实验;采用基于LM快速算法的BP神经网络来综合评估。
误差小、训练速度快,应用于水声对抗效能评估。优点:综合考虑专家经验、实验数据。
论文:
声诱饵公认是对抗鱼雷的装备。仅仅通过鱼雷命中率来评判声诱饵的作战效能不够完善。
1,作战效果评价指标的选择
声诱饵可由噪声、模拟回波的最大谱源级、频率范围、工作方式、声学方向性、持续工作时间等方面来评价。
但是作战效果的评价要考虑 只有声诱饵被鱼雷发现并被跟踪才行。因而,从一下六点评价:
(1)鱼雷对对抗装备平均观测时间率
就是声诱饵暴露在雷达的观测范围内,包括雷达检测识别的时间,时间越长越好,设为阿尔法。
(2)鱼雷与对抗装备平均最小距离
鱼雷与对抗装备(声诱饵)的最小距离,反映了声诱饵的诱骗能力
(3)平均有效对抗开角
声诱饵声学方向性,越大越好。
(4)有效引导鱼雷攻击率
有效的概率
(5)鱼雷i航程平均增加率
平均浪费了鱼雷多少距离,越大越好
(6)鱼雷命中概率下降率
有无声诱饵时命中率变化
【为什么4和6是两个指标呢。不理解啊不理解】
综合评价由BP 训练得出,声诱饵对抗能力C = f(1,2,3,4,5,6)
LM 本质是牛顿法的变种,具有牛顿法的二次终止特性,用于极小化非线性函数的平方和。
利用LM 来对BP 网络进行加速收敛的优化
【深度学习的老论文少看为妙,优化算法肯定是近两年的效果最好,现在的反向传播优化应该比LM 算法好】
2.4评价指标的标准化转换
参数归一化,用的最大值归一化方法,很常规的方法
3 .1训练样本
由专家的经验评分和典型对抗态势下的仿真数据构成
【训练样本就十一个你敢信???】
样本包含了各个参数的最大值最小值,并包括了中间值
就三层的网络
个人评价
【模型得到就用,没有模型准确率的一个评估,默认得到模型就是准则,是文章最大的软肋。文章有点在于量化提取六个评价因素】
基于神经网络的分布式雷达抗干扰效能评估方法
徐斐 , 谢洲烨 , 沈伟 , 代培龙;南京电子技术研究所;现代雷达;2015
摘要:
利用实验数据的专家评估结论作为样本训练网络。并与传统加权评估方法、模糊综合评估方法相对比。
对于分布式雷达的评估,1,无法描述分布式雷达的所有参数,2,这些参数对雷达抗干扰能力影响程度无法准确量化,3,对系统内各单雷达的抗干扰效能没有同意评估标准。
分布式评估指标
1单机指标:单机指标进行加权平均
2总体指标:系统中心站进行数据融合之后的结果
3固有指标:分布雷达确定之后的指标和措施。
1.1雷达有效发射功率
1.2雷达信号时宽带宽积
脉冲调制信号
1.3雷达空间体积
雷达分辨率,最小分辨体积
2.1雷达探测威力变化率
采取抗干扰时的探测距离变化
2.2雷达探测精度变化率
2.3目标航迹质量变化率
2.4假目标识别率
2.5真目标检测率
3.1布站方式
比如直线形,三角形,梯形等
3.2技术措施抗干扰银子
包括单雷达的技术措施和分布式雷达的技术措施
分布雷达可以收发分置、多节点频率捷变等,可用12种抗干扰措施来阐述
后向传播BP 神经网络评估模型
三层网络(10,8,1)
训练样本获取
采用专家评估法获得。多为专家评估均值作为雷达系统抗干扰的效能值
原始数据处理
输入在0-1,归一化,最大值归一化。布站方式采用自定义法,手动对不同形状打分【这尼玛也行】
一共就十组数据
个人评价
跟上一篇零几年的论文一个套路。
都存在数据少,没有对模型准确率进行评估。
q- 高斯的 SOM 神经网络在雷达抗干扰效能评估中的应用
赵伟 , 伞冶;哈 尔 滨 工 程 大 学 学 报;哈尔滨工业大学 控制与仿真中心;2011年
摘要:
为了扩大邻域函数的输出空间和增强神经元的邻域合作, 提出基于 q- 高斯的 SOM的神经网络评估雷达抗干扰效能。
非广延熵指数 q 从大到小自适应地调整平衡了神经元的远邻域合作和近邻域合作。仿真表明准确率100%
前言:
目前 , 雷达抗干扰效能评估的方法主要有线性加权法 、 层次分析法 、 模糊评判法和概率综合法。人为因素影响大。SOM 神经网络是一种无监督学习的竞争型神经网络。
雷达抗干扰措施包括:1抗干扰改善因子 、 2雷达抗欺骗式干扰有效概率改善因子 、3 雷达自卫距离改善因子 、 4测量精度改善因子 、 5目标起始航迹平均时间改善因子 、6 雷达观察扇区损失度改善因子 、 7系统平均错误航迹数改善因子和8系统平均虚假航迹数改善因子 .
雷达固有特性:1平均发射功率 、 2天线增益 、 3发射信号带宽和发射、4信号时宽带宽积
SOM 神经网络对于解决类别特征不明显和特征参数相互交错混杂的雷达抗干扰效能评估问题是非常有效的
SOM 神经网络是由输入层和竞争层构成的两层神经网络。
一共十二组数据,来自7种雷达。最大值归一化。进行测试。
仿真:
选取UCI机器学习数据库[15]中5个实例进行测试。样本数分别150-846个,10重交叉验证,7个数据库综合为一个大库。做聚类和分类的实验。
[15]ASUNCION A, NEWMAN D J. UCI machine learning repository[ M] . Irvine: University of California, 2007: 56-63.
个人评价:
终于是一个完整的论文了,数学推理部分功力不够看不太懂,模型构建后的数据量大,因而后续工作有说服了。
应更关注提到的UCI 数据库。
.。。看了下数据库,是一个什么类别都有的深度学习数据库,比如很火的Iris花分类,Wine等,难道雷达评估模型是用非相关的数据库训练的???文章中没提到用的哪7种实例来进行训练的啊。看来作者有点心虚啊这是。
A Deep Learning Method to Estimate Independent Source Number
ICSAI2017 Wenmei Hu
信号盲源分离,以往都是已知信号源数量,因而得到信号源数量非常重要。与各种无监督算法对比,本文提出独立的源数量的估计。基于CNN。然后盲源分离迎刃而解。本文使用基本信号的混合+带噪声的不同信号+传统无监督方法进行对比实验。
一、介绍:
战场电子通讯领域,如何快速分析通讯、雷达中的信号是最困难的问题。有限信号叠加+噪声。盲源分离常使用ICA独立成分分析。源的数量必须被正确的估计出来。本文主要就是估计独立源数量。传统方法是AIC MDL最小描述长度 等方法。可以用许多独立信号叠加得到训练数据,通过模型估计出源的数量进而盲源分离。
二、相关工作
最广泛是ICA盲源分离,后来升级为FastICA,都依赖matrix analysis
前人工作都需要先验的确定源数量
源估计有两类经典的分类:1,AIC 2,MDL
MDL中的作者可以得到准确的源数量和 低信噪比下少量的重复(iterations)
进来,混合信号分离新进展,新的粗粒度窗口算法提出,更高精度,更强鲁棒性
当今,深度学习应用于自动建模分类AMC 。有人用两层网络实现AMC,比BER的系统好了很多
三、盲源分离系统
A 线性混合模型
忽略噪声
【各类传感器X】 = 【未知矩阵A】 * 【N个未知源S】
y=Wx y是分离的信号源,W 未知分离矩阵 y=Wx=WAs=Cs
C=WA,C就是混合、分离矩阵。所以要找到C
B系统结构
两部分: 1. 两层CNN估计源的数量, 2 FastICA分离
CNN:输入层:混合信号序列,输入为1*200
卷积层:1*10 ,20个滤波器
池化层:size=10,step=1,max pooling
全连接层:。。。
个人评价:
(2018-6-10)文章心意不大,深度学习部分只是一个两层的浅层网络,蹭了深度学习的热度。不过比较快速的使用CNN进行源数量的估计,是创新的工作。后一步也许能进一步将信号分类部分也统一在一个深度学习框架就厉害了。
YOLOv3:An Incremental Improvement
Joseph Redmon, Ali Farhadi 2018 华盛顿大学
全文翻译:https://zhuanlan.zhihu.com/p/34945787
摘要:
做了些改进,比V2更快,更准确。和SSD一样准,但是快三倍。在0.5的IOU情况下,可以和two-stage的RetinaNet相比。在TitanX上可以51ms。
1、介绍。。。2、Deal。。。2.1、包围框预测
使用逻辑回归来预测每个包围框的对象分数。如果先前的边界框比之前任何边界框与ground truth重叠的都好,就赋值为1,如果重叠超过阈值,但不是最好,就忽略(文中使用0.5);为每个ground truth对象分配一个边界框。
2.2分类预测
不适用softmax,使用多标签分类,使用福利的逻辑分类器。训练过程中,使用二元交叉熵损失 来进行类别预测。
2.3多尺度
3种尺度的框。形成金字塔网络。在基本的特征提取器中加入几层卷积层,最后一个预测了3-d张量编码的边界框,对象和类别预测。COCO实验中80个类别,每个尺度三个框,4个框偏移量,张量为N x N x (3*(4+1+80))
从之前的两层中取得特征图,上采样两倍,与‘旧版本中的特征图’融合,可以从早期映射中的上采样特征和更细粒度的信息中获取有意义的语义信息。
使用k-means聚类确定边界框的先验。选用9个聚类,3个尺度,在整个尺度上均匀分割聚类。
2.4特征提取
使用连续的3X3,1X1卷积层,有一些shoycut连接,网络更大,53个卷积层,叫Darknet-53
比V2中Darknet-19更强,比ResNet-101(快1:5倍)、ResNet0152(快2倍)更有效
2.5训练
没有难、负样本最小化等行为
3如何构建的
4无用工作:
这里使用anchor没啥用,降低精度
逻辑激活会降低精度,所以文中使用线性激活函数直接预测x,y
使用Focal loss,有单独的对象预测和条件类别预测。
个人评价:
(2018-6-10)应该先看YoloV1,因为这篇文章很多V1的细节就没说,重点说的改进部分
在IOU0.5时效果很好。V1、2对小物体检测不太好,V3正好相反。
随着新的多尺度预测,V3有较高的APS性能。
You Only Look Once: Unified, Real-Time Object Detection
Joseph Redmon;, Santosh Divvala;Ross Girshick;Ali Farhadi 2016 华盛顿大学、FaceBook
一、摘要
以回归问题解决目标检测,从空间上分割边界框和相关的类别概率,二者一次获得。可以对性能进行端到端的优化。
45帧每秒,小版本可以155帧,从自然图像到其他领域的泛化优于DPM、R-CNN。虚警低。
1、引言
很多检测系统使用分类器来执行检测,在不同位置来分类、评估,如DPM 的滑窗方法。
首先,流程快
其次,YOLO与区域推荐方法不同,我们训练时会使用整张图片,隐式的编码了类的傻姑娘下文信息和外观,而区域推荐只是局部,因而本方法很少把背景当成目标,虚警小了一半。
第三,泛化能力强
2统一检测
使用整个图片的特征来预测每个边界框,还可以同时预测图中所有类别的边界框。
将输入图像分成S x S的网格,如果一个目标的中心落入一个网格单元中,该网格单元负责检测该目标。
每个网格预测B个边界框和置信度,置信度定义为Pr(Class)*IOU,我们希望置信度分数 = IOU即预测框与真实框交集;每个边界框x,y,w,h,置信度5个参数
每个网格预测C个条件类别概率Pr(Class|Object),以包含目标的网格单元为条件,每个单元只预测一组类别概率Pr(class)
可以得到每个框特定类别的置信度分数。表明了该类在框中出现的概率以及预测框拟合目标的程度
在PASCAL上使用S=7即7 x 7,B=2,由于20类因而C=20。最终的一侧是7 x 7 x 30的张量 SxSx B*5 + C)
2.1网络设计
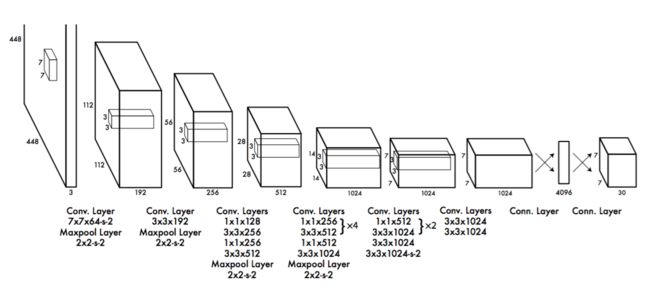
受GoogleNet分类模型启发,24个卷积层,1x1降维层,没使用GoogleNet中的Inception模块,在Imagenet上以224分辨率训练,检测时再将分辨率加倍
输出7x7x30
2.2训练
Imagenet1000类上训练卷积层,预训练前20个卷积层用了一周,使用Darknet框架
转换模型执行检测,加了4个卷积层,随机初始化,由于检测需要细粒度的视觉信息,网络输入224提升为448。
通过图像宽度和高度来规范边界框的宽度和高度,使之落在0-1之间,使用leaky RELU,最后一层使用RELU。
优化了模型输出中的平方和误差。但是,分类误差与定位误差权重一样是有风险的,一张图大多单元无目标,置信度为0,可能压倒有目标的单元格的梯度,导致训练早期发散。因而增加边界框坐标预测损失。减少了不包含目标边界框的置信度预测损失。λ=5或者0.5来完成这个设置
平方和误差一可以在大盒子、小盒子中同样加权误差。大盒子小偏差的重要性远不如小盒子小偏差重要,因而我们直接预测边界框高度、宽度的平方根,而不是宽度和高度。
训练时,每个目标只用一个边界框预测器,指定一个预测器负责选取最高IOU的预测。导致边界框预测器专业化,因而可以更好的预测特定大小、方向角、或目标类别。
学习率先10的-3,再-2,防止开始时发散,再-3,-4。
防止过拟合,使用了大量的数据增强。在第一个连阶层之后丢弃层使用0.5,防止层之间相互适应。20%的随即缩放、转换,HSV色彩空间中使用1.5的高因子随机调整
2.3推断
PASCAL中每张图预测98个边界框和对应类别概率。大目标或跨网格的目标可以被多个网格单元很好的定位。非极大抑制可以修正这些多重检测,提高精度。
2.4 Yolo的限制
对边界框预测强加了空间约束,因为每个网格单元只预测两个盒子。这个空间约束限制了我们的模型可以预测的临近目标数量。对小物体检测不太好
因为从数据中预测边界框,很难泛化到新的、不常见的方向比。因为架构具有来自输入图像的多个下采样层
对小边界框和大边界框的检测性能的损失函数同样对待,小目标IOU 敏感,因而对小目标不好
3与其他检测系统比较
与two-stage比,突出了关键的相似性和差异性
DPM:滑窗、提取特征、分类,预测高分区域的边框。我们的系统用单个卷积网络替换这些部分。
R-CNN:区域推荐、选择性搜索、卷积+SVM +线性模型调整边框、非极大抑制。我们的相似之处在于每个网格单元提出的潜在的边界框使用卷积特征评分,但是我们有空间限制,环节对同一目标多次检测。更少的边界框98个而不是2000个,one-stage端到端
Faster R-CNN:慢
YOLO 不是试图优化大型检测流程的单个组建,而是完全抛弃流程。通用检测器可以学习同时检测多个目标。
Deep MultiBox: 使用单类预测题啊婚置信度预测来执行单目标检测,但是只是整个流程的一部分,且需要图像分块
OverFeat:高效滑窗、优化了定位,而不是检测性能,局部信息需要大量后处理
4实验
4.1与实时系统比
DPM 的GPU 版本即30Hz或100Hz版本
快度YOLO52.6%mAP;YOLO的mAP是63.4%
用VGG 训练YOLO,慢而准。DPM加速时,检测精度受限
Faster中,7帧,小的Faster18帧,VGG版本高10mAP慢6倍
4.2VOC错误分析
使用{19}中的方法,对测试时每个类别前N个预测看
正确类别且IOU》0.5
.。。
YOLO 定位错误占大多数,比其他错误多
Fast定位错误少,但背景错误多。高出3倍
4.3结合Fast的YOLO
Fast71.8% 用YOLO减少虚警,达到75%,不同版本的Fast结合可以提高0.3%
4.4VOC2012
YOLO为57.8%mAP。
4.5泛化能力,艺术品中行人检测
泛化能力上YOLO>DPM>RCNN,因为RCNN 分类器只能看到小区域。DPM 有形状和布局的强大空间模型。
艺术品中像素不一样,但是大小、形状相似,因而YOLO 给予大小、形状、目标之间位置关系,就可以很好预测
5现实环境下
网络摄像头
6结论
构造简单,在整张图上训练,整个模型联合训练
泛化快
个人评价:
(2018-6-12)男神RGB的大作呢,我怎么敢评价
基于深度学习的雷达辐射源识别技术研究
西安电子科技大学 井博军 硕士论文2017
摘要
1,雷达波形越加复杂,必须研究脉内特征,时频分析将一维的时域信号映射为时间、频率的联合分布,二维图像。以图像处理来解决。-10Db时,不同的调制方式的平均识别率97.78%
2,提出一维卷积神经网络的辐射源信号识别方法。99%识别率。
前言
1,雷达信号调制参数多种多样,新型雷达采用特制样式2,信号环境更加复杂,接近全频,识别难度大。3,夹杂噪声,信噪比大。
传统识别辐射源方法有信号载频CF、脉冲宽度PW、脉冲幅度PW、到达时间TOA、到达角DOA五个参数的脉冲描述字,模板匹配。传统5个参数越来越难以匹配新信号。因而转向脉内分析。
1.2国内外现状
辐射源信号->(信号预处理)信号->(特征提取)特征->(分类识别)结果->
早期,模板匹配,对数据的容量、质量要求高;数据库需要覆盖足够多的雷达信号;缺乏灵活性对新体制雷达和低信噪比下辐射源信号识别不好
识别速度快,实现简单。
后来用脉内特征,使用:时域分析法、频域分析法、瞬时自相关法、谱相关法、时频域分析法。
将采样信号进行变换和特征提取,通过可分离度较高的特征向量来实现信号识别。分类器有:机器学习法的KNN;SVM、决策书DT、神经网络等。还有很多人对脉内其他特性进行分析
仍存在的问题,没训练的雷达信号特征有效性没法验证;这些特征对低信噪比下雷达辐射源的有效性不好;雷达辐射源特征需要专业人士很大成本获得。
第二章雷达信号建模与仿真
2.1雷达辐射源信号模型仿真
雷达信号x=理想信号s+噪声n
2.1.1常规脉冲信号
2.1.2线性调频信号
2.1.3非线性调频信号
2.1.4相位编码信号
2.1.5频率编码信号
2.2雷达信号无意调制建模与仿真
脉内调制分有意调制、无意调制。
2.2.1脉内有意调制
幅度调制AM(受噪声影响大)、相位调制PM、频率调制FM、混合调制
2.2.2脉内无意调制
伴随系统、指纹特征:附加调幅、附加调相
2.2.3无意调制仿真
第三章 卷积神经网络
第四章 基于时频分析和卷积神经网络的信号识别
雷达是非平稳信号,傅里叶变换难以刻画局部特征;时频分析将一维信号转换为二维的时频面上,反应信号频谱和能量密度之间的关系
信号->时频分析->视频图像预处理->训练->识别
傅里叶不具有时间局域化的能力,能量谱无法给出频率出现的准确时间。[47]将信号表示为视频联合函数来描述信号频谱在时间上的变化。
一类方法:“核函数分解”短傅里叶、Gabor变换、小波变换(都满足线性叠加原理)
另一类方法:时频能量密度,Wigner-Ville分步以及Cohen类时频分布(满足二次叠加原理)
4.2视频图像预处理
输入图像->灰度变换->图像平滑->图像归一化
4.3仿真
输入图片64x64
C1卷积层 5x5卷积核 N=6
S2池化层 2x2 均值采样
C2卷积层 5x5 N=12
S4池化层 2x2
全连接层 输出层 Relu
4.3.1不同调制方式的雷达辐射源信号识别
7类:常规脉冲、LFM、NLFM、二相编码、二频编码、四频编码、四相编码
采样点数512,信噪比-10dB-6dB,9个信噪比点,每个信噪比点产生1200个信号并做SPWVD
每种信号相同信噪比取1000张,共7000张为训练集,剩下200张共1400为测试集
对各层网络进行可视化输出;使用两种网络结构进行对比;7类单独的识别率;训练时准确度随迭代次数增长图
第五章 一维卷积的神经网络信号识别
生成训练数据慢,图像训练需要更多的数据,训练时间长
信号->FFT->序列预处理->网络训练->识别
OpenPose:
Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields
Top-Down方法 ,先检测人,再关键点检测,人数增加时,时间复杂度也会增加。多人距离近时检测为一个人,则会误差很大。
Bottom-Up方法,
本文达到了mutiple public benchmarks 的领先水平,提出association scores相关分数,在图像域讲四肢位置和方向的二维向量进行编码,
关键点检测 CMP(confidence maps for part)
关键点连接 PAF:part affiity fields
评估两个关键点之间的相关性:
计算位姿骨架,二分图匹配(求解最大匹配方法:匈牙利算法)
实验结果
MPII 数据集,基于 PCKh 阈值,测量身体所有部分的mAP