机器学习实验四:朴素贝叶斯分类
文章目录
-
- 一、算法介绍
- 二、朴素贝叶斯分类的优缺点
- 三、代码简单实现
一、算法介绍
贝叶斯分类算法是一大类分类算法的总称,贝叶斯分类算法以样本可能属于某类的概率来作为分类依据。朴素贝叶斯分类算法是贝叶斯分类算法中最简单的一种。
首先我先给出一个贝叶斯公式:
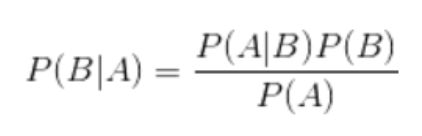
代入实际的意义: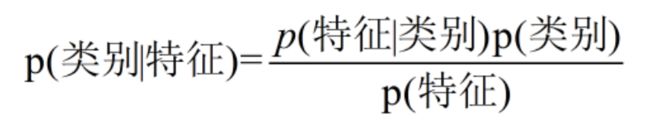
我们要求的是p(类别|特征)。而对于朴素贝叶斯算法,朴素贝叶斯算法是假设各个特征之间相互独立的**这样以来,我们可以将朴素贝叶斯公式写为:

而对于朴素贝叶斯分类的训练,就是基于训练集 D D D估计 类先验概率 P ( c ) P(c) P(c),并为每个属性估计条件概率 P ( 特 征 i ∣ 类 别 ) P(特征i|类别) P(特征i∣类别),令Dc表示训练集D中第c类样本组合的集合,则类先验概率:(c为类别)
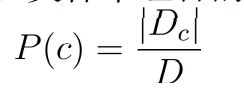


二、朴素贝叶斯分类的优缺点
优点:
(1) 算法逻辑简单,易于实现
(2)分类过程中时空开销小
缺点:
理论上,朴素贝叶斯模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为朴素贝叶斯模型假设属性之间相互独立,这个假设在实际应用中往往是不成立的,在属性个数比较多或者属性之间相关性较大时,分类效果不好。
而在属性相关性较小时,朴素贝叶斯性能最为良好。对于这一点,有半朴素贝叶斯之类的算法通过考虑部分关联性适度改进。
三、代码简单实现
使用了西瓜书上的数据集:
色泽 根蒂 敲声 纹理 脐部 触感 好瓜
青绿 蜷缩 浊响 清晰 凹陷 硬滑 是
乌黑 蜷缩 沉闷 清晰 凹陷 硬滑 是
乌黑 蜷缩 浊响 清晰 凹陷 硬滑 是
青绿 蜷缩 沉闷 清晰 凹陷 硬滑 是
浅白 蜷缩 浊响 清晰 凹陷 硬滑 是
青绿 稍蜷 浊响 清晰 稍凹 软粘 是
乌黑 稍蜷 浊响 稍糊 稍凹 软粘 是
乌黑 稍蜷 浊响 清晰 稍凹 硬滑 是
乌黑 稍蜷 沉闷 稍糊 稍凹 硬滑 否
青绿 硬挺 清脆 清晰 平坦 软粘 否
浅白 硬挺 清脆 模糊 平坦 硬滑 否
浅白 蜷缩 浊响 模糊 平坦 软粘 否
青绿 稍蜷 浊响 稍糊 凹陷 硬滑 否
浅白 稍蜷 沉闷 稍糊 凹陷 硬滑 否
乌黑 稍蜷 浊响 清晰 稍凹 软粘 否
浅白 蜷缩 浊响 模糊 平坦 硬滑 否
青绿 蜷缩 沉闷 稍糊 稍凹 硬滑 否
#encoding:utf-8
import pandas as pd
import numpy as np
class NaiveBayes:
def __init__(self):
self.model = {}#key 为类别名 val 为字典PClass表示该类的该类,PFeature:{}对应对于各个特征的概率
def calEntropy(self, y): # 计算熵
valRate = y.value_counts().apply(lambda x : x / y.size) # 频次汇总 得到各个特征对应的概率
valEntropy = np.inner(valRate, np.log2(valRate)) * -1
return valEntropy
def fit(self, xTrain, yTrain = pd.Series()):
if not yTrain.empty:#如果不传,自动选择最后一列作为分类标签
xTrain = pd.concat([xTrain, yTrain], axis=1)
self.model = self.buildNaiveBayes(xTrain)
return self.model
def buildNaiveBayes(self, xTrain):
yTrain = xTrain.iloc[:,-1]
yTrainCounts = yTrain.value_counts()# 频次汇总 得到各个特征对应的概率
yTrainCounts = yTrainCounts.apply(lambda x : (x + 1) / (yTrain.size + yTrainCounts.size)) #使用了拉普拉斯平滑
retModel = {}
for nameClass, val in yTrainCounts.items():
retModel[nameClass] = {'PClass': val, 'PFeature':{}}
propNamesAll = xTrain.columns[:-1]
allPropByFeature = {}
for nameFeature in propNamesAll:
allPropByFeature[nameFeature] = list(xTrain[nameFeature].value_counts().index)
#print(allPropByFeature)
for nameClass, group in xTrain.groupby(xTrain.columns[-1]):
for nameFeature in propNamesAll:
eachClassPFeature = {}
propDatas = group[nameFeature]
propClassSummary = propDatas.value_counts()# 频次汇总 得到各个特征对应的概率
for propName in allPropByFeature[nameFeature]:
if not propClassSummary.get(propName):
propClassSummary[propName] = 0#如果有属性灭有,那么自动补0
Ni = len(allPropByFeature[nameFeature])
propClassSummary = propClassSummary.apply(lambda x : (x + 1) / (propDatas.size + Ni))#使用了拉普拉斯平滑
for nameFeatureProp, valP in propClassSummary.items():
eachClassPFeature[nameFeatureProp] = valP
retModel[nameClass]['PFeature'][nameFeature] = eachClassPFeature
return retModel
def predictBySeries(self, data):
curMaxRate = None
curClassSelect = None
for nameClass, infoModel in self.model.items():
rate = 0
rate += np.log(infoModel['PClass'])
PFeature = infoModel['PFeature']
for nameFeature, val in data.items():
propsRate = PFeature.get(nameFeature)
if not propsRate:
continue
rate += np.log(propsRate.get(val, 0))#使用log加法避免很小的小数连续乘,接近零
#print(nameFeature, val, propsRate.get(val, 0))
#print(nameClass, rate)
if curMaxRate == None or rate > curMaxRate:
curMaxRate = rate
curClassSelect = nameClass
return curClassSelect
def predict(self, data):
if isinstance(data, pd.Series):
return self.predictBySeries(data)
return data.apply(lambda d: self.predictBySeries(d), axis=1)
dataTrain = pd.read_csv("xiguadata.csv", encoding = "gbk")
naiveBayes = NaiveBayes()
treeData = naiveBayes.fit(dataTrain)
import json
print(json.dumps(treeData, ensure_ascii=False))
pd = pd.DataFrame({'预测值':naiveBayes.predict(dataTrain), '正取值':dataTrain.iloc[:,-1]})
print(pd)
print('正确率:%f%%'%(pd[pd['预测值'] == pd['正取值']].shape[0] * 100.0 / pd.shape[0]))
实验结果:
{"否": {"PClass": 0.5263157894736842, "PFeature": {"色泽": {"浅白": 0.4166666666666667, "青绿": 0.3333333333333333, "乌 黑": 0.25}, "根蒂": {"稍蜷": 0.4166666666666667, "蜷缩": 0.3333333333333333, "硬挺": 0.25}, "敲声": {"浊响": 0.4166666666666667, "沉闷": 0.3333333333333333, "清脆": 0.25}, "纹理": {"稍糊": 0.4166666666666667, "模糊": 0.3333333333333333, "清晰": 0.25}, "脐部": {"平坦": 0.4166666666666667, "稍凹": 0.3333333333333333, "凹陷": 0.25}, "触感": {"硬滑": 0.6363636363636364, "软粘": 0.36363636363636365}}}, "是": {"PClass": 0.47368421052631576, "PFeature": {"色泽": {"乌黑": 0.45454545454545453, "青绿": 0.36363636363636365, "浅白": 0.18181818181818182}, "根蒂": {"蜷缩": 0.5454545454545454, "稍蜷": 0.36363636363636365, "硬挺": 0.09090909090909091}, "敲声": {"浊响": 0.6363636363636364, "沉闷": 0.2727272727272727, "清脆": 0.09090909090909091}, "纹理": {"清晰": 0.7272727272727273, "稍糊": 0.18181818181818182, "模糊": 0.09090909090909091}, "脐 部": {"凹陷": 0.5454545454545454, "稍凹": 0.36363636363636365, "平坦": 0.09090909090909091}, "触感": {"硬滑": 0.7, "软粘": 0.3}}}}
预测值 正取值
0 是 是
1 是 是
2 是 是
3 是 是
4 是 是
5 是 是
6 否 是
7 是 是
8 否 否
9 否 否
10 否 否
11 否 否
12 是 否
13 否 否
14 是 否
15 否 否
16 否 否
正确率:82.352941%
https://zhuanlan.zhihu.com/p/26262151