【GoogLeNet】Going deeper with convolutions
参考链接
参考翻译
参考视频
Abstract
作者在ILSVRC14(the ImageNet Large-Scale Visual Recognition Challenge 2014,包括分类和检测任务)上提交的GoogLeNet为Inception架构,这个架构是基于赫布定理和多尺度处理直觉知识来设计的。Inception的主要特点是提高网络中计算资源的利用率,即在保持计算量不变的前提下来提高网络的深度和广度
1 Introduction
随着更多具体的网络被提出,图像识别和物体检测任务发展有着较大进展,但是我们不能只是一味地依赖硬件性能提升、扩充数据集和叠网络,而是要在提出新模型思路和改进模型结构上下功夫。
本文的GoogLeNet比AlexNet少12倍的参数量却在性能上得到得到较大提升。当时分类性能优秀的RCNN先使用深度学习方法生成候选框,在使用传统计算机视觉对候选框进行甄别,通过深度学习和传统计算机视觉的协同作用进行分类识别(现在大部分模型都是直接使用深度学习方法端到端地完成任务)。
此外不能一味追求精度提升而忽略了模型的现实运用可行性(如能耗和内存占用),因为模型需要部署在移动设备和嵌入式设备中
Inception的重要启发论文:
- Network in Network:使用1x1进行降维升维,用GAP(全局平均池化)层取代全连接层
- Arora[2]的理论研究《Provable Bounds for learning some deep representations》:用稀疏、分散的网络取代以前庞大密集臃肿的网络
2 Related Work
LeNet-5
LeNet-5 定义了卷积神经网络的标准结构范式:(卷积+normalization+最大池化)xN+全连接层xM
之后的变种如AlexNet、ZFNet在MNIST和CIFAR上也取得了不错的性能。当时的趋势就是增加模型深度和每层尺度,并使用dropout来减少过拟合
虽然最大池化层会丢失空间像素的精确特征,但是CNN依然能够用于定位和目标检测。受神经科学研究成果启发,不同的神经元学习到的特征不同,将它们连接融合可以解决多尺度问题。
Network in Network
Network in Network提出可以用1x1卷积后跟ReLu激活函数来降维,而且这种结构能够很容易地就接入到主干网络中。本文模型频繁用到1x1卷积,它的作用主要包括:1. 降维以减少参数量和运算量并且还可以限制网络规模 2.增加模型深度提高非线性表达能力
R-CNN
当时最先进的网络就是R-CNN,它包括两个步骤:
-
先找出候选框(selective search):使用低层信息如颜色、像素一致性以category-agnostic地方式(未知类)来定位可能的物体,即找出的候选框没有类别信息
-
然后对每个候选框运用CNN分类器来识别这些位置上的物体类别
本文模型也使用了类似的方法,但是提升了各阶段的性能。如提升了候选框的recall,即候选框中真目标的比例提高
3 Motivation and High Level Considerations(模型设计启发)
如果有大量的标注训练集,我们可以单纯地增加网络宽度(卷积核个数)和深度(层数)来提升网络性能,但是这个安全而简单的做法有两个缺点:
- 大规模网络有着较大参数,参数越多越容易过拟合,特别是训练集中的标记实例数量有限的情况下。这可能会成为一个主要的瓶颈,因为创建高质量的训练集可能很棘手,也很昂贵,特别是需要人类专家来区分细粒度的视觉类别,如ImageNet中的类别(甚至在1000类的ILSVRC子集中)。如图1所示,左边是哈士奇,右边是爱斯基摩犬。区分一个类目下的不同种类往往需要专家知识来进行细粒度的判别

- 参数越多需要的计算资源越多
计算效率问题:两个卷积层相连的情况下,任何卷积核个数的增加会导致计算量平方增加。而且如果很多权重训练后接近0,那么这部分计算就会被浪费了
解决这两个问题的根本途径为用稀疏连接取代密集连接,在卷积层内部也要用稀疏结构
其实卷积就是一种在空间上利用稀疏性的操作,但是卷积又是与前一层中图像块的密集连接的集合,自LeNet-5以来,ConvNets传统上在特征维度上使用随机和稀疏的连接表,以打破对称性并提高学习效果,为了更好地优化并行计算,趋势从AlexNet开始变回了全连接。结构的统一性和大量过滤器以及更大的批处理尺寸使得利用高效的密集计算成为可能。
如LeNet-5中只使用上一层部分通道组合进行下一层输入,而AlexNet中将上一层所有通道一起参与卷积实现更好的并行运算加速。这是因为CPU和GPU更擅长密集运算而非稀疏运算。大量研究稀疏矩阵运算的文献也建议将稀疏矩阵聚集为相对密集的子矩阵来获得稀疏矩阵乘法的最优实施效果。作者希望不远的未来人们能发明这种可以自动构建non-uniform deep-learning architectures非统一深度学习结构(即利用模型的稀疏性来改进网络,但是又可以进行密集运算的网络结构)。
赫布学习法则中的neurons that fire together, wire together:一个类别的所有特征是被同时激活的,如识别一只猫时,猫眼睛、猫耳朵,猫腿等等是同时被识别到的。
4 Architectural Details
Inception主要思想就是用密集模块来近似局部最优稀疏结构

本文含有图注的图片均来自b站同济子豪兄
4.1 Inception模块构思理论
由于Inception模块是相互堆叠的,这些模块输出的相关数据必然会有所不同:随着更高的抽象特征被更高的层所捕获,它们的空间集中度会降低,这意味着随着层数越深,3x3和5x5卷积比例应该越高。但是也要合理控制其比例,因为即使是数量不多的5×5卷积,在具有大量的滤波器的卷积层上也会使计算量变得过于昂贵。一旦池化单元被添加到组合上,这个问题就变得更加明显:它们的输出滤波器的数量等于前一阶段的滤波器的数量。将池化层的输出与卷积层的输出合并,将导致各阶段的输出数量不可避免地增加。即使这种结构可能涵盖了最佳的系数结构,但它的效率非常低,在几个阶段内就会导致计算量的爆炸
以上想法的一个解决方案就是:在计算需求增多的情况下,巧妙地使用降维和投影。嵌入思想认为即使是低维的嵌入也可能包含关于一个相对较大的图像块中的大量信息。然而,嵌入以密集的、压缩的形式表示信息,而压缩的信息更难建模。我们希望在大多数地方保持我们的表征是稀疏的(按照 [2] 的条件要求),并且只在信号必须被大量聚集的时候才压缩它们。也就是说,在3×3和5×5卷积之前,使用1×1卷积来计算减法,除了用于计算减法外,1x1卷积还应包括使用ReLu,来使得它们具有(降维减少参数量、增加非线性和模型深度)双重用途
4.2 如何使用Inception模块
故一般来说,Inception网络是由上述模型的模块(Fig2.b)相互堆叠而成的网络,偶尔会有步长为2的最大值池化层,将网络的分辨率减半。
此外,不能一开始就用Inception模块,而是应该在传统卷积网络之上,即较高层处,使用Inception模块。这种结构的主要好处之一是,它允许在每个阶段大大增加了单元的数量,而不会在计算复杂性方面出现不可控的爆炸。降维的普遍使用允许将最后一个阶段的大量输入滤波器屏蔽到下一层,首先降低它们的维度,然后用一个大的图像块尺寸对它们进行卷积。这种设计的另一个实际有用的方面是,它符合视觉信息应该在不同尺度上进行处理,然后进行聚合的直觉,以便下一阶段可以同时从不同尺度上抽象出特征。
(通过精细的调试,含Inception的网络结构比no-Inception的网络结构快2-3倍)
5 GoogLeNet
GoogLeNet的取名含义:对LeNet的致敬,并表示该网络为Inception模块的一个化身
5.1 GoogLeNet的详细结构参数
Table 1为GoogLeNet的详细结构参数

在本文的网络中,感受野的大小是224×224,采用RGB颜色通道,并进行平均减法。“#3×3 reduce”和“5×5 reduce”代表了在3×3和5×5卷积之前使用的还原层中1×1过滤器的数量。
所有的卷积,包括Inception模块内的卷积,都是用了线性整流函数(ReLU)作为激活函数。在pool proj一栏中看到内置最大池化后投影层中的1×1滤波器的数量,所有这些还原/投影层(reduction/projection layers)都用了线性整流函数(ReLU)作为激活函数。
5.2 GoogLeNet上的fine-tuning
该网络可以在计算和内存资源受限的设备上部署,有权重的总共有22层(算上池化层有27层),算上Inception内部有100层。在分类器之前的平均池化层基于 [12],但本文使用了一个额外的线性层来方便网络适应和微调其他标签集,并没有太大性能影响(可以让用户把该分类层换为自己的分类层)。
作者发现,用GAP代替全连接层能将top-1的准确性提高了大约0.6%(且GAP可以防止过拟合、便于fine-tuning迁移学习),然而在去除全连接层后,dropout的使用仍然是至关重要的。
5.3 GoogLeNet的辅助分类器
像GoogLeNet这样的大网络,很容易出现梯度消失。通过在4a和4b(这里图注应该是在4e??)后面添加小型卷积网络(达到辅助分类器的效果,后面被证实浅层的辅助分类器没太大用处,后面新出的几个版本都去掉了辅助分类器)来增加网络早期特征的区分性,达到正则化的效果。
而在测试阶段,模型去掉辅助分类器,只保留主体结构的分类器。
主干网络(传统神经网络):
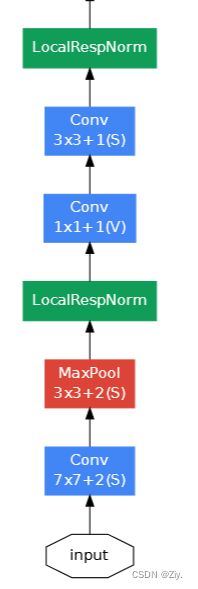
这里后证实LocalRespNorm(AlexNet中的局部响应归一化层)没什么用,已经过时
两个辅助分类器

此处softmax Activation 用于归一化
Inception模块之后:

最后一层得到各类概率和输出
整个结构:

6 Training Methodology
使用的是DisBelief的分布式机器学习系统进行训练,并进行模型和数据的并行。使用0.9动量的异步随机梯度下降,学习率每8轮下降4%。
此外,作者还研究了裁剪比例为8%-100%之间、宽高比为3:4 和4:3之间的训练效果,和等概率使用不同插值方法的潜在作用(最后其实也没有说清楚这些图像增强技巧对最终结果有没有用)
7 ILSVRC 2014 Classification Challenge Setup and Results(分类竞赛)
7.1介绍了 ILSVRC 2014 的一些数据:
- 训练集、测试集和验证集大小
- top1-error、top5-error(最后排名按照top5-error来排)
7.2 除了上文技巧之外的其他技巧
- 使用了7个模型集成,每个模型使用相同初始化方法甚至相同初始值和学习策略,仅在图像采样和输入顺序有区别
- 将原图缩放为短边长度为256、288、320、352四个大小的图,每个大小的图片裁出(横图的)左中右或(纵图的)上中下三张小图,每张小图取四个角和中央的一共五张224x224的patch,并将每张小图缩放至224x224。故总共就是6个patch(五张224x224的patch和缩放至224x224的小图),再取这6个patch的镜像,总共4x3x6x2=144个patch,即一张图可以得到144个patch。
- 用7个模型对这144个patch进行预测,再将预测值进行融合(7个模型结果预测莫一类别的结果最多则为最终结果)得到一张图片的最终分类结果
(可以说是为了提升结果费劲心力了……)

上表 ILSVRC 2014的比赛结果,GoogLeNet冠军,错误率最低

从Table3 可以看到模型集成地越多,图像裁剪地越多,计算量也就越多,但是模型性能也越好
但是作者自己也说在现实中不用1张图片裁剪出144个patch那么激进,这只是作者用来竞赛提升性能拿冠军的技巧。并且裁剪数量到一定值的时候错误率不会再降了,并且超过该值会有负面影响,得不偿失。
8 ILSVRC 2014 Detection Challenge Setup and Results(物体检测竞赛)
在200个类别的图像数据集中画出定位框并标注类别,框出的物体要是groundtruth的并且框和物体要最少重叠50%的区域(即交并比IoU>0.5)就认为该定位框检测正确,而其他多余的检测框为false positive 并会被惩罚。与图像识别任务不同,图像检测中可能有多类物体,物体的大小不定,最终结果用mAP判定(即mean average precision)。
与R-CNN比较:
- 结合Selective search 和 multi-box prediction减少无用的候选框
- 没用使用框回归直接对候选框分类
- 使用Inception模型作为分类器
9 Conclusions
利用现有的密集计算资源来实现了模型的优化稀疏结构,模型还有后续改进版本。