Uncertainty Modeling and Optimization-不确定性建模与优化-理论篇(高速更新中)
Uncertainty Modeling and Optimization-不确定性建模与优化
目录
- Uncertainty Modeling and Optimization-不确定性建模与优化
-
- 0. 前言
- 1. 随机规划和机会约束简介
-
- Chance-constraints programming
- Apriori paradigm
- Reoptimization
- 2. 经典鲁棒优化求解
-
- Robust Counterpart
- Reformulation
- Adversarial approach
- 3. 不确定集Uncertainty set
-
- 对偶定理
- 不确定集
-
- Polyhedral Uncertainty Set
- Budget Uncertainty Set
- Ellipsoidal Uncertainty Set
- CVaR Uncertainty Set
- 4. [选读] 不确定集参数的选择
-
- 不保守的不确定集
- 参数选择的例子
- 5. 适应性鲁棒优化建模与NP-hard介绍
- 6. 适应性鲁棒优化求解
-
- 情况一:等价于经典RO
- 情况二:可精确求解
- 情况三:可近似求解
-
- Affine decision rule
- Piecewise affine decision rule
- Dual decision rules
- 7. 分布式鲁棒优化和锥规划
-
- 分布式鲁棒优化概述
- VaR的DRO例子(上)
- 锥线性规划基础
- VaR的DRO例子(下)
- 8. 矩约束下的分布式鲁棒优化
-
- 矩不确定性
- 另一种方法
- 9. Wasserstein下的分布式鲁棒优化
-
- Wasserstein Distance
- Logistic Regression
- 10. 自适应分布式鲁棒优化
-
- 特殊情况下的精确求解
- Linear Decision Rule近似解
0. 前言
已经很久没有写过类似学科知识分享的内容了。之前提到过多次,最近一段时间在学习不确定性问题的处理。虽然学习很不连贯,导致效率一直不高,但也算读过/看过一些资料,对这方面有了大概的了解。感觉自己自主推倒/复习不够,根基很浅,为了巩固学过的一些知识,决定做一点小笔记,在做的过程中复习学过的内容,也顺带与大家分享。
“不确定性优化”这个词应该是没有的。我这样叫,是因为我打算介绍的内容基本上用于处理不确定性问题。这个范围是很广的,因为优化本身是很广的概念,我也不能够、不打算做/学/写这么多内容。所以我改成了“建模与优化”,旨在介绍以优化应用为目的的建模方法,以及一些基本的处理方法。
无需多说,在现实生活中,很多东西都是不确定的。客户的需求,行驶的时间,投资收益率。我们通常用参数的期望来估计其真实值,这在很多情况下会对结果造成巨大的影响。轻则使得目标函数变差,比如错误估计了开会迟到扣工资,重则使得解不可行,比如错过了整个会议,领导让你走人。因此,如何更精确地处理不确定性问题,是很重要的。
简单来说,不确定性的建模方法主要是随机规划(stochastic programming/optimization, 简称SO),鲁棒优化(robust optimization, 简称RO)和机会约束(chance-constraints programming, 简称CCP)。SO和CCP是传统的处理方法,已经有很多很多年的研究。他们主要基于已知分布的随机变量,这在现实中往往是很难得到的。此外,SO比较多的使用期望这一概念,因此结果往往是平均情况下的,不能反应极端情况的结果。RO主要是这个世纪发展的一门技术,无需多说,近几年在优化领域,无论是OR还是ML都产生了很大的影响。他的目的是为了放松“已知概率分布”的条件,并得到一个鲁棒性够强的解,而不是平均意义上的解。当然,对应的问题就是,由于解需要在任何情况下都可行,所以解的质量可能在大多数情况下不够好,也就是过于conservative(保守)。深究下去,SO也有Apriori paradigm和reoptimization,RO也有classical RO,Distributionally RO,Adaptive/Adjustable RO,ADRO等多种框架。不同的建模范式各有特点。
虽然叫不确定性,但我暂时比较想写/学的内容还是RO相关的,因为SO目前的知识已经够我用了,CCP则暂时不想研究。因此,我只会花一点内容简单介绍SO和CCP,留坑以后再填。因为未来不一定更新,所以暂时决定在近几天边学边写,多写一点内容。
回到作者本身,我是管理学出身,本科没有凸优化、随机过程等课程,只学过皮毛的线性规划,数学基础很差。但是,RO本身是一门很严谨的内容,因为他在一定程度上挑战了一般的线性规划框架,并且涉及概率论,推导的过程自然需要很严谨。学RO的目的如果真的想推导公式,那是比较难的。好在,作者是做algorithm的,我们的目的是应用。所以,我的内容也会很不严谨,以理解为目的,并添加一些应用的内容,比如RO在facility location,portfolio,vehicle-routing等方面的应用,作为学习的实例。不过对应的,作者基础差的好处就是,介绍到内容可能会详细一些。在文章中,对我自己也不确定的内容,我会尽量用<>标出,或者用文字说明。此外,我也会尽量详细地列出知识的来源,因为在我的学习过程中,很多文献/课程/资料都起到很大的作用。有什么问题也希望大家指出。
大家一起学习,一起进步!
1. 随机规划和机会约束简介
Chance-constraints programming
前文提到,不确定性的建模方法主要是SO,RO,CCP。这里我们先简单了解SO和CCP。对于一个简单的例子问题(1):

问题(1)是一个常规的线性规划(linear programming,简称LP)问题。在不确定性环境下,其中的参数A,b,c都可能是随机变量。问题就转化为了:

在问题(2)中,原问题的各个参数都由随机变量 ξ \xi ξ控制。这个问题就已经超出了LP的处理范围。在SO和CCP中,我们通常<假定所有随机变量的分布函数已知>(似乎不是所有随机变量都有给定的分布函数的,这种说法不一定正确)。所以我们可以尝试使用一些随机变量的数字特征描述问题,比如期望:

当然,问题(3)是一个确定性问题。这样估计显然有失偏颇,如前文所说,这种方式无法衡量风险的损失。因此,CCP用一个概率为风险兜底。这个概率也可以理解为概率论的参数估计中的置信度:

问题(4)是一个很典型的机会约束模型。简单来说,他确保了满足约束的概率大于某个给定的下界,这个下界也决定了问题的保守程度。虽然概率 P P P不一定能转化为LP的形式处理,但我们有时可以进行一些简单的处理,得到确定性约束。以下是[1]中关于旅行时间随机的车辆路径规划问题(SVRP)的一个例子:


直接看可能有些难懂,其实约束的 P P P中所有参数都是已知的。当我们知道随机变量 B B B的分布函数(这里满足正态分布)时,可以用分布函数的逆函数表示 P P P,从而得到一个非线性的确定性约束。目前这样仍然无法用LP处理,并且这个例子把决策变量去掉了。不过,这依旧给出了一个可行的操作方向,如果新公式是凸的,或许可以使用其他的工具解决。因为我对CCP的了解不多,这一方向暂时不继续拓展。
Apriori paradigm
[2]将SO在SVRP中的应用分为Apriori paradigm和reoptimization。前者也被称为stochastic programming with recourse。Apriori将问题改变成两阶段问题:

其中 Q ( x , ξ ) Q(x,\xi) Q(x,ξ)代表 x x x和 ξ \xi ξ实现之后recourse的期望成本。在第一阶段,我们首先根据参数的期望值构造一个解。在第二阶段,如果随机变量的实现值使得该解违背了某些约束,则通过一个给定的recourse修复解,recourse的成本记入总成本。所以,我们可以在求解第一阶段的时候将recourse的期望成本加入成本计算中。

以随机客户需求的VRP问题为例,假设原先路径为 { d e p o t , v i 2 , v i 3 , … , , v i t , d e p o t } \{depot,v_{i_2},v_{i_3},\dots,,v_{i_t},depot\} {depot,vi2,vi3,…,,vit,depot},这条路径上所有客户的需求的期望值之和必须小于车辆总容量。但是,如果车辆到达节点 v i j v_{i_j} vij后发现容量不足,那么车辆会返回depot,装/卸货后,再前往下一个节点。多出的路途 d v i j , 0 + d 0 , v i j + 1 − d v i j , v i j + 1 d_{v_{i_j},0}+d_{0,v_{i_{j+1}}}-d_{v_{i_j},v_{i_{j+1}}} dvij,0+d0,vij+1−dvij,vij+1则作为recourse cost,乘上这种情况发生的概率,记入总成本。这里的recourse可以简单定义为,如果在点 i i i发现剩余容量不够服务点 i + 1 i+1 i+1,则返回仓库补货。通过这种方式,Apriori paradigm考虑了失败的风险带来的成本。
Q一般不能直接用线性规划求解。但是,由于Apriori paradigm本身可以看作两阶段问题,因此可以使用处理两阶段问题的线性规划算法。常用的求解方式L-shaped algorithm就是基于branch-and-cut,或者说更类似于Benders decomposition,通过对第一阶段的最优解添加feasibility cut来保证解的可行性,添加optimality cut保证最优性。在这里暂时不做更多介绍。此外,由于第二阶段成本可以作为期望成本加入第一阶段,因此也可以使用常规非线性的解法,比如启发式算法、branch-and-price。
Reoptimization
另一种reoptimization的方式则利用了马尔科夫决策过程,动态调整解。在无后效性的马氏过程下,可以通过动态规划(DP)的方式构建模型,然后通过逆向求解的方式求解。计算成本的时候,我们依然使用期望值作为成本。

以上式子给了一个DP公式的例子。这里 p p p项为概率, J ~ \tilde{J} J~为DP的cost-to-go函数,代表每个状态下的最优解, g g g代表当前决策带来的成本, u u u代表决策, x x x代表状态。所以,问题的目标值等于,在每一种状态 x k x_k xk下,选择使得期望成本最小的决策 u k u_k uk时的期望成本。由于reoptimization完全建立在DP和马氏过程的基础上,因此相关求解算法也是离不开这两者。这方面我了解不多,因此暂时不做更多探讨。
以上介绍是我学习SVRP相关内容时的了解,SO在很多领域可能有别的建模范式,有待未来补充。一些没有详细介绍的内容,比如求解的技术,待以后再补充。下一章将正式进入RO的内容。
参考文献:
[1] Xiangyong Li, Peng Tian, Stephen C.H. Leung. Vehicle routing problems with time windows and stochastic travel and service times: Models and algorithm. Int. J. Production Economics
[2] Michel Gendreau, Ola Jabali, Walter Rei. 50th Anniversary Invited Article—Future Research Directions in Stochastic Vehicle Routing. Transportation Science.
2. 经典鲁棒优化求解
前面我们介绍,鲁棒优化有classical RO(这个好像是我自己叫的),Distributionally RO,Adaptive/Adjustable RO,ADRO等。DRO, ARO, ADRO都是对经典RO在某些方面的改进,他们的处理方法都以RO为基础。而RO的求解方法,归根到底,都是基于线性规划中的对偶理论。
Robust Counterpart
我们前面引入了这个问题:

注意这里的 A , b , c A,b,c A,b,c关于 ξ \xi ξ是一种线性关系,可以称为robust linear constrains。为了方便起见,这里的 b b b是一个标量而非向量。对于SO而言, ξ \xi ξ是一个已知分布的随机变量。如果有多个变量,一般还假设iid(独立同分布)。在RO中,我们不知道 ξ \xi ξ的分布。但我们假设知道 ξ \xi ξ的取值范围: ξ ∈ Z \xi \in Z ξ∈Z。这里的集合 Z Z Z被称为不确定集(uncertainty set)。这显然放松了对 ξ \xi ξ的要求。
如名字所说,RO需要解有足够的鲁棒性,也就是说解应该在任何情况下都可行、都由目标函数确保有准确的下界。在SO with recourse中,为了保证在某些情况下解的不可行带来的成本,我们在目标函数中添加了 Q Q Q项。在RO中,我们不添加这样的成本,而是选择让目标函数以下界的形式确保其鲁棒性。我们可以将问题(2)写成如下的鲁棒对应形式(Robust Counterpart, RC):

首先保证约束条件对所有情况可行,其次目标函数变成一个max-min形式。我们的优化对象变成了目标函数的下界。但是,max-min并不是线性算子。我们将问题转化为上境图(epigraph)形式:

这里的epigraph应该是凸优化中的一个概念。函数 f f f的上境图定义为:

其中dom f f f 表示 f f f 的定义域。
回到问题,注意,这种形式应该叫epigraph的RC。RO的epigraph应该是不写成不确定集的。
在epigraph形式下,RO已经转化为了一个线性形式。但是,很多情况下 Z Z Z是无限集合,比如连续型随机变量。一般的LP显然无法处理无限个约束的问题。因此,我们用一种称为reformulation的方法将原问题转化为可以求解的LP问题。
Reformulation
我们考虑一个简化的例子:

这里的不确定性只在约束的一次项系数中出现。当目标项有不确定性时,可以通过如上的epigraph转化到约束中;当常数项 b b b中存在不确定性时,可以写成 b ( ξ ) T x 0 b(\xi)^Tx_0 b(ξ)Tx0的形式,固定 x 0 = − 1 x_0=-1 x0=−1,将其转化到一次项中。此外,我们还用 a + P ξ a+P\xi a+Pξ表示了 A ( ξ ) A(\xi) A(ξ)。这里的 P P P是一个矩阵。这种模型被称为factor model。相比于 a + a ^ ξ a+\hat{a}\xi a+a^ξ的均值+离差形式,这种model能反映出更多的 ξ \xi ξ的组成。

如图所示,factor model可以表示Example 2的情况,而 a + a ^ ξ a+\hat{a}\xi a+a^ξ不可以。详细可以参考[2]的讲解。(也是原图出处)
第二个约束可以进一步转化为如下形式:

注意这里第二步加的转置,是为了后续子问题写成"参数的转置*变量"的形式,没有其他意义。由于是标量,所以可以直接加。
上一步实际上将约束转化为一个子问题。接下来,接下来我们从最简单的Box uncertainty set开始,展示如何通过对偶进行reformulation。首先介绍Box uncertainty set:

上图展示了Box不确定集的两种写法和一个例子。其中 U U U一般代表不确定项的取值。这一不确定集由范数描述,在这个不确定集下,对该问题取对偶,得:

最后将对偶问题带入原问题,得:

这样就转化为了一个可用LP直接求解的问题。
在上述步骤中,我们实际上将最初RC中无穷个约束的问题,转化为子问题中的变量。LP本身就可以解决无穷个变量的情况,也就可以解决原问题了。
事实上,上述过程中还有很多可探究的部分。例如,你真的了解怎么求对偶了吗?是仅仅从公式表格,“原问题变量和对偶问题约束符号一致,原问题约束和对偶问题变量符号相反”,还是通过其他思路?是否真的理解强弱对偶的关系、内容、条件?在更广的含义下,例如,非线性的不确定集中,简单的LP的对偶是否还成立?或者说,需要引入线性规划以外的,更广的范围下的规划方法?这些内容,我们暂且放到下一章介绍。
Adversarial approach
回到epigraph形式,LP其实也有办法解决无限个约束的情况。这种处理RO的方法被称为adversarial approach。他的核心思想是,从一个有限的不确定集的子集 Z ′ ∈ Z Z'\in Z Z′∈Z开始,接触最优解,再判断该解在整个集合 Z Z Z的环境下是否可行。如果不可行,再将导致不可行的scenario,或者叫 ξ \xi ξ的可能的取值,加入到 Z ′ Z' Z′中。详细介绍见[1]。这种方法其实类似于branch-and-cut的思想。但总体来说,reformulation依然是更常见的解法。
参考资料:
[1] Bram L. Gorissen, İhsan Yanıkoğlu, Dick den Hertog. A practical guide to robust optimization. Omega.
[2] 章宇。鲁棒优化及其在车辆路径问题中的应用简介。https://www.bilibili.com/video/BV1tK4y1e7fQ?spm_id_from=333.337.search-card.all.click
3. 不确定集Uncertainty set
前面我们介绍了box不确定集下RO的reformulation,主要利用了对偶定理。在这一章,我们先介绍对偶定理,再介绍更多的不确定集。
对偶定理
我本人上运筹学的时候,老师似乎没有深入解释过对偶问题的构造过程及对偶定理在其中的作用。我们以上次的盒子不确定集转化的过程作为例子。

对原问题做如下处理:

构造对偶问题的第一步是构造拉格朗日松弛的形式。在步骤(1)中,我们通过加入约束的惩罚项构造了一个两阶段的问题。在步骤(2)中,我们只关注内部的min问题。当约束被违背时, p p p可以取一个很大的值, q q q可以取很小的值,导致结果为负无穷,问题无解。因此该问题等价于原问题(P)。

我们考虑交换max和min之后得到的新问题。还是先考虑内部的max。提出和 ξ \xi ξ项,依然可以得到类似上文(2)的结论。我们发现,该问题等价于(D)。这样就构造了对偶问题。

注意,在这个过程中 x x x只是参数,不是决策变量。同时,(6)右侧与上图(D)的符号不一样,如果在(1)中改成减去惩罚项就变成一样的了。
现在的问题是,max-min和min-max是否完全等价。这就是对偶定理告诉我们的内容。


上文给出了弱对偶定理以及简单的证明。强对偶定理证明比较复杂,在这里暂不介绍(我也没看)。根据这两个定理,就能得出(P)与(D)等价,即max-min与min-max等价的结论。
个人认为,这部分理解是很重要的。因为在后续分布式鲁棒和一些非线性的不确定性集中,用到的对偶定理将不是简单的线性规划下的对偶定理。因此在这里特别介绍。关于这部分内容,可以参考资料[1]中苏文藻老师关于DRO的课程,也可以参考[2]中第二章的内容,里面有关于对偶理论的详细证明。
不确定集
构造不确定集要从可解释性和可解性两个方面度量,即,既要有概率层面的价值,又要可处理。这一章我们介绍其他经典的不确定集合。
Polyhedral Uncertainty Set
我们先介绍Box不确定集的拓展,Polyhedral Uncertainty set。在凸优化中,多面体Polyhedren可以理解为<一个线性规划问题的可行解区域,是一个由超平面围成的凸集>。超平面就是指取等号的线性约束。多面体不确定集可以写成如下形式:

可以看出,盒子不确定集其实是他的特例,将 v i v_i vi取±1, w i j w_ij wij取1。我们依然从上述步骤的约束子问题开始处理该不确定集:

只需要机械化地处理,就能得到结论了。当然,构造对偶的方法不一定要用拉格朗日,也可以直接套用公式。
包括盒子不确定集在内的很多经典不确定集都是用p范数定义的。p范数的简单概念如下:

盒子不确定集使用了无穷范数,我们自然想知道,由1范数和2范数确定的不确定集,是否存在比较好的性质?
Budget Uncertainty Set
Budget uncertainty set由1范数定义。具体如下:

图中展示了两种等价的表现形式。我们依然按套路解决:


提一嘴,提出这个不确定集的论文The price of robustness是很有影响力的文章。(但我还没仔细读过)
Ellipsoidal Uncertainty Set
椭圆不确定集由2范数定义:

这里列举了集中表示方法和一个例子。从例子中可以看出其二维图形是一个椭圆。由线性代数中二次型的知识可知,二次形式都可以表示为 x T Y x x^T Y x xTYx的形式。其中 Y Y Y为对称矩阵。如果 Y Y Y为正定矩阵,则这个值永远大于等于0。所以,这些椭圆都可以表示为3中的factor model。注意这里的求和符号代表一个矩阵。因为可以调整矩阵参数,所以 Z Z Z中的 Γ \Gamma Γ可以取1。
回到之前的问题,可以处理如下:

我们发现,约束对应的子问题变成了一个非线性规划,里面包含二次、根号。这个问题也可以用拉格朗日松弛之后求导解决,但在这里我们用另一个方法:

也就是我们高中常用的柯西不等式。(实际上盒子不确定集也可以很快得出结论)但是,即使如此,新的约束依然是非线性的情况。熟悉凸优化的同学可能知道,这其实是一个conic programming可解的问题,是一个二阶锥。在后续DRO的内容中,我们再详细介绍这个内容。
CVaR Uncertainty Set
最后介绍一个CVaR的不确定集,并详细介绍求解过程,作为总结。
VaR和CVaR是常用于资产组合的概念。前几章已经提到了一些不确定性问题处理范式的固有缺陷,比如,无法反应风险情况。这两个概念就是从目标函数的角度限制风险(相关处理方法还可以在许多论文中看到)。
VaR指的是在给定的置信区间下,最小化可能发生的最大的损失。例如95%的概率下,最大可能损失1k,剩下的5%则可能超出1k。
CVaR是指,当预期损失高于预期最差情况时的回报率。例如5%的VaR是-25%,指的是95%以外的(最差情况)5%的概率,回报率低于-25%。
简单来说,VaR衡量了95% 里的损失,而CVaR衡量了5%里面的损失,因此,CVaR的损失大于VaR。这部分背景可以自己查一查。
VaR会作为后续内容的例子出现。在经典RO中,CVaR的不确定集更常见。定义如下:

其中 z ~ \tilde{z} z~是一个给的的向量,可以理解为不同的scenario(场景), α \alpha α是给定的置信度。相当于对任何可能的场景分配概率,概率和不超过一个上界。
回顾最初的问题,RO可以写成如下的形式:

这个问题是一个资产组合选择的例子,其中 r r r为不确定的回报率, x x x为投资选择。将它写出robust counterpart形式(问题2),用factor model表示:

进一步写出epigraph的RC形式(问题3),并处理robust linear constraints:

写出对应子问题。这里可以直接替换 z z z,简化问题(问题4)。然后用得出对偶问题(问题5):

最后带入主问题(问题6):

就能成功解决了。这部分内容可以参考[3]。
这一章介绍了一些常用的不确定集,并引出了RO和椎规划的关系。下一章可能还会写一点不确定集的内容,然后就会进入分布式鲁棒优化(DRO)的内容。
参考资料:
[1] 苏文藻. 分布鲁棒优化简介. “数据驱动的优化理论、算法与应用”暑期学校. https://www.bilibili.com/video/BV1bM4y1L7R7?spm_id_from=333.337.search-card.all.click
[2] Erick Delage. Quantitative Risk Management Using Robust Optimization Lecture Note. https://tintin.hec.ca/pages/erick.delage/MATH80624_LectureNotes.pdf
[3] 运小筹. 鲁棒优化| 利用rome求解鲁棒优化简单案例:以CVaR不确定性集为例.
https://mp.weixin.qq.com/s?__biz=MzI3NTI2NzcxOA==&mid=2247486373&idx=1&sn=7beaed25d63d72555bd8ac9e4fb9dffb&chksm=eb06224cdc71ab5a5c83637b0393dbc34338bbff8bea5154834d44f6e5de025f29e386821567&scene=178&cur_album_id=2003418663093059585#rd
4. [选读] 不确定集参数的选择
其实在各个不确定集中,都有一些参数用于调整不确定集的保守性。可以说,box不确定集是最保守的,他的图形就是一个盒子;相比之下,budget、ellipsoidal不确定集就分别砍掉了长方体的某个部分、圆整了边界。选择这些不确定集就是为了在保守性上做一定取舍。
参数调整肯定是基于已有数据的。这部分内容在[1]中被称为Data-driven Uncertainty Set Design,就是从这个角度考虑。因为这部分内容比较多应用于portfolio,有些内容也比较深入,所以暂时只是简单带过,作为番外内容。
不保守的不确定集
上一章提到了,VaR指的是在给定的置信区间下,最小化可能发生的最大的损失。他的定义和之前第一章提到的CCP很类似。这里给一个VaR的数学定义:

<我猜测,这里用 − y -y −y是因为VaR的定义是损失,而这里的 y y y如果理解成收益,把下面问题的min − y -y −y 换成 max y y y 也是等价的>。可以看到,下面的问题形式就是CCP。如第一章所说,要将CCP转化为线性约束,就需要对已知的密度/累计函数做反函数处理,总体来说比较难算。因此,通过RO处理这个问题,会是一个有趣的方法。虽然,按我们之前的说法,所谓的“robust”应该让 ϵ \epsilon ϵ等于0。但在很多情况下,这确实过于保守。下面的定理给出一个将CCP转化为RO的方法:

这个定理将约束的概率转化为了不确定集的概率。证明也很简单,如果后面的情况下前面必定满足,所以前面的概率大于后面。
参数选择的例子
假设有一组2000-2009年10只股票的月度回报数据。我们希望解决以VaR为优化目标的CCP问题:

其中 ϵ = 5 % \epsilon=5\% ϵ=5%。
根据上面的定理,我们可以考虑去掉CCP约束,考虑这样的RO问题:

假设使用ellipsoidal不确定集:

接下来要做的,就是确定 U ( r 0 , γ ) U(r_0, \gamma) U(r0,γ),使 P ( Z ∈ Z ) ≥ 1 − ϵ \mathbb{P}(Z \in \mathcal{Z}) \geq 1-\epsilon P(Z∈Z)≥1−ϵ。
很明显, r 0 r_0 r0肯定要用期望 E [ r ] E[r] E[r]近似,这里肯定用样本期望近似真实期望;剩下的 γ \gamma γ,可以用一下步骤确定:
-
对所有历史数据 r k r_k rk,计算 γ k : = ∥ r k − r 0 ∥ 2 \gamma_{k}:=\left\|r_{k}-r_{0}\right\|_{2} γk:=∥rk−r0∥2。
-
对 { γ k } \{\gamma_k\} {γk}排序,取第 ( 1 − ϵ ) × K (1-\epsilon) \times K (1−ϵ)×K大的那个,作为估计值。
事实上,在一定情况下,可以选择很合适的参数使得RO和CCP等价。上述RO问题的reformulation形式为:

如果 γ \gamma γ满足正态分布,那么CCP约束 P ( Z ∈ Z ) ≥ 1 − ϵ \mathbb{P}(Z \in \mathcal{Z}) \geq 1-\epsilon P(Z∈Z)≥1−ϵ可以转化为:

ϕ − 1 ( x ) \phi^{-1}(x) ϕ−1(x)是累计概率函数的反函数, σ \sigma σ是标准差。只要令 γ = ϕ − 1 ( 1 − ϵ ) σ \gamma=\phi^{-1}(1-\epsilon)\sigma γ=ϕ−1(1−ϵ)σ,两个约束就完全等价了。
以上内容只是参数选择的一个例子,由于和RO具体理论关系小一些,需要用的同学还是更多参考文献或者详细阅读[1]的内容。
参考资料:
[1] Erick Delage. Quantitative Risk Management Using Robust Optimization Lecture Note. https://tintin.hec.ca/pages/erick.delage/MATH80624_LectureNotes.pdf
5. 适应性鲁棒优化建模与NP-hard介绍
从这一章开始,将进入适应性鲁棒优化(adaptive/adjust robust optimization, ARO)的学习。ARO实际上处理的是多阶段决策问题,这和我们第一章提到的stochastic programming with recourse有相似之处,因为他也是一个两阶段问题。因此,联系前后的内容理解,可能会更有帮助。本章内容基本参考自[1]。
本章将从一个类似multi-stage newsvendor的问题出发,展示使用鲁棒优化建模多阶段问题时遇到的困难,以此引出ARO。首先思考一个如下的多阶段问题:

这里每个值都是标量。其中 x t x_t xt是每个阶段的进货量, y t y_t yt为正数表示每个阶段库存量,为负数表示缺货量, d t d_t dt表示需求量, h t h_t ht表示库存成本, b t b_t bt表示缺货成本, c t c_t ct表示进货成本。很明显问题是一个multi-stage newsvendor,如果不太清楚背景可以看一看相关资料。其中 ( ) + ()^+ ()+表示max算子。
max算子显然不是线性的。可以线性化为如下问题2:

我们关注的是问题的鲁棒形式,也就是robust counterpart。一个很naive的方法是直接对每个参数加上随机项 z z z:

这里的sup是上确界,可以简单理解为max,不明白区别的同学可以自己查查。
这里出现一个问题。第一个约束中,除了 d t ( z ) d_t(z) dt(z)项都是确定值。也就是说,这一组约束对不同的 z z z都要满足,相当于一个确定值等于很多个不同的 z z z。这显然是错的,因此我们在写成RC之前去掉 y t y_t yt项,然后得到:

这样就初步得到了一个可能正确的RC形式。但是,这样处理有两大问题:
-
这里的 x t x_t xt是predefined的,是offline的。也就是说,我们在第一阶段开始之前就决定了每个阶段的订货量。实际上,在全局最优的角度看,每个订货量应该根据之前的实际销售情况决定,也就是说,需要实时地,online地调整。
-
s t + , s t − s_t^+, s_t^- st+,st−这样建模是错误的。正确的形式应该是:

这两个问题的区别在于,在问题4中,对每一个 z ∗ z* z∗求最优解时, s t + , s t − s_t^+, s_t^- st+,st−需要对每个 z z z都满足约束,而在问题5中,他们只需要对 z ∗ z* z∗满足就够了。因此,问题应该写成多阶段问题,这里令 T = 2 T=2 T=2,以两阶段为例:

这样我们大概就明白了建模的方法。回顾整个多阶段问题的处理过程,如图:

当我们做出 x 1 x_1 x1决策时,时间轴往后走,一个随机性事件 v 2 ( z ) v_2(z) v2(z)发生了,我们可以观察到他的实现值,然后做出下一个决策 x 2 x_2 x2的具体值,以此类推。在多阶段问题里,我们通常把第一阶段直接做出的决策变量成为here-and-now decision,而把后续做出的决策成为wait-and-see decision。这也和我们前面讲的一样,每个 x t , t ≥ 2 x_t, t\geq 2 xt,t≥2时online决策的,根据前面的 v 2 ( z ) v_2(z) v2(z)调整,所以需要wait and see。
总结对multi-stage问题的RC,下面问题成为Multi-Stage ARC (adaptive robust counterpart):

但是,这里又隐含了一个条件:时间的一致性。在这个问题中,不确定集 Z Z Z是没有更新的。但在某些时候,这是需要更新的。我们举一个小例子。
-
假设你经营一家咖啡馆,从早上7点经营到11点,需要预估咖啡的进货量。你有理由依据经验假设7-9点有100人来,9-11点有100人来,7-11点最多300人来,或许因为咖啡馆的坐位不超过300个(这就类似budget uncertainty set)。那么,如果7-9点真的有200人来了,依据假设9-11点不超过100人,7-11点一共不超过300人,你依然不需要更改自己的期望。
-
但如果你打算在9点把咖啡铺子搬到另一个地方(假设是移动摊位)。你依然可以假设一共不超过200杯,因为两个地方是独立的,100+100=200。但是,如果你发现7-9点出售了150杯咖啡,按总共200的思路,9-11点应该预估50;但是,你有理由调整预期到100,因为两地是独立的。那么,原先的预期就需要调整。
对于上面的例子来说,第一个例子中不确定集(也就是预期销量)是前后一致的,不随时间而改变。但第二个例子中,不确定集是会改变的。这时我们就需要调整问题。这里依然用一个两阶段问题为例:

在这里, x 1 x_1 x1是第一阶段, x 2 x_2 x2是第二阶段,随机因素是 d = [ d 1 , d 2 ] T d=[d_1, d_2]^T d=[d1,d2]T。这与问题7最大的区别就是最后一个约束,不确定集 U ~ 2 ( d 1 ) \tilde{U}_2(d_1) U~2(d1)是随 d 1 d_1 d1改变的集合,在第二阶段决策中, d 2 ′ d_2' d2′需要属于这个不确定集,但是从总体角度, d d d依然要属于 U U U。
上述问题很难解决。目前我们不考虑这类问题。事实上,问题7已经很难解决了,我们用一个定理结束这一章:

这就足以说明问题求解的困难了。关于NP-hard,放一点很久之前的笔记:



其实,ARO并没有非常通用的解法。下一章中,我们介绍目前ARO在一些特殊情况下的解法。
参考资料:
[1] Erick Delage. Quantitative Risk Management Using Robust Optimization Lecture Note. https://tintin.hec.ca/pages/erick.delage/MATH80624_LectureNotes.pdf
[2] Ihsan Yanıko ˘glu, Bram L. Gorissen, Dick den Hertog. A survey of adjustable robust optimization. European Journal of Operational Research.
6. 适应性鲁棒优化求解
上一章我们通过从多阶段问题中引出了ARO的概念:

并说明了他的求解难度。在这一章里我们介绍一些可以求解的情况。
情况一:等价于经典RO
在一定条件下,多阶段问题与单阶段问题等价,这时就不需要求解ARO问题。当最优解 x t ( v t ( z ) ) = x t ( v t ( z ′ ) ) , ∀ z , z ′ ∈ Z x_t(v_t(z))=x_t(v_t(z')), \forall z, z'\in Z xt(vt(z))=xt(vt(z′)),∀z,z′∈Z时, x t x_t xt就与 v t v_t vt无关了,只需要求解如下的RO问题:

有如下定理:

条件1,3,4将每个约束与随机项 z z z的对应情况分开了,条件2表示每个 x t x_t xt都有一个上界。这个定理并不是最完整的定理,与之相关的论文似乎还有更新。定理的证明暂时挖坑。
情况二:可精确求解
[3]提出了一种行列生成的方法,并在文章里介绍了之前多用的benders分解算法。这一节里,我们结合[1]和[3]的内容介绍这两种方法。
[3]解决的其实是一个非常简单的问题:

这里的符号和前面略有区别。在这里 y y y是第一阶段决策变量, x x x是第二阶段决策变量, u u u是随机变量, F ( y , u ) F(y,u) F(y,u)是第二阶段问题。可以看到,第二阶段问你题和第一阶段决策相关的项 G x Gx Gx是一个线性函数,和不确定因素 u u u相关的项也只是线性项 M u Mu Mu,所以非常非常special。此外,还要求不确定集 U U U为polyhedron或discrete。在后面我们会拓展这些限制。
使用benders分解的方法很粗暴。首先需要满足一个relative complete recourse。在后面我们再解释这个内容,大概可以理解为,针对属于该集合的第一阶段的 x x x,第二阶段 y y y永远有可行解。因此在benders中不需要加入feasibility cut,只需要加optimality cut。看到第二阶段子问题是min,但不确定项是max,所以对min问题取对偶,合并两个max,得到子问题:

虽然SP1不是一个线性规划问题(注意目标函数的 u T π u^T\pi uTπ),但还是有很多办法求解,这里不展开解释。因此,对于一个主问题的最优解 y k ∗ y^*_k yk∗,可以解上述子问题SP1得到最优子问题解 ( u k ∗ , π k ∗ ) (u^*_k,\pi^*_k) (uk∗,πk∗)。构造optimality cut: η ≥ ( h − E y − M u k ∗ ) T π k ∗ \eta \geq\left(\mathbf{h}-\mathbf{E y}-\mathbf{M} u_{k}^{*}\right)^{T} \pi_{k}^{*} η≥(h−Ey−Muk∗)Tπk∗ 加入主问题:

加入后重新解主问题MP1,得到最优解 ( y k + 1 ∗ , η k + 1 ∗ ) (y^*_{k+1},\eta^*_{k+1}) (yk+1∗,ηk+1∗)。很明显 c T y k ∗ + Q ( y k ∗ ) \mathbf{c}^{T} \mathbf{y}_{k}^{*}+Q\left(\mathbf{y}_{k}^{*}\right) cTyk∗+Q(yk∗)会是一个upper bound,因为第一阶段和第二阶段是分开优化的,局部最优之和肯定不如全局最优;而 c T y k + 1 ∗ + η k + 1 ∗ \mathbf{c}^{T} \mathbf{y}_{k+1}^{*}+\eta_{k+1}^{*} cTyk+1∗+ηk+1∗则是一个lower bound,因为没有考虑第二阶段完整的极点,或者说,没有考虑所有的约束。因此,如果两个解相等,则得到最优解,算法终止。这一段也算是对benders的复习了。
容易理解,迭代求解子问题的次数和第二阶段的极点数量有关。记 p , q p, q p,q分别为不确定集 U U U和 x x x的定义域的极点数(若 u u u离散,则为离散节点数),算法的迭代次数的复杂度应该是 O ( p q ) O(pq) O(pq)。
第二种方法是行列生成。我们通过[1]中更general的描述来介绍。
针对以下的两阶段鲁棒优化形式,可以用上述方法和以下方法求解:

可以看到,我们去掉了第二阶段决策变量 y y y的系数的不确定扰动 z z z。这种情况被称为fixed recourse。注意recourse这个词,虽然中文没有很好的翻译,但是我们在第一章介绍SP的时候遇到过。当初我们用VRP做了一个例子,recourse代表的是一种在第一阶段决策给定后的,针对第二阶段的补救措施。在SP中,我们将recourse导致的期望成本(expected cost of recourse)加入目标函数。在这里, a j 2 T , c 2 T a_{j2}^T, c_2^T aj2T,c2T实际上也可以理解为recourse,是用于描述第二阶段的参数,只不过描述成了线性规划形式。在RO中,我们不考虑期望,而是考虑worst case。这个例子很好的展现了SO和RO的不同。
回到问题3,问题3的fixed recourse简化了第二阶段的不确定因素。此外,我们还规定 x ∈ X x\in \mathcal{X} x∈X。这个集合的意思是,针对属于该集合的第一阶段的 x x x,第二阶段 y y y永远有可行解。所以集合可以表示为如下形式:
![]()
这被称为relatively complete recourse。与之相对的还有一个complete recourse,<意思似乎是,在约束中, y y y之外的参数取任何值,都存在可行的 y y y。>所以complete recourse是强于relatively complete recourse的。
问题可以写作如下的两阶段形式:

注意,第一阶段没有目标函数和约束(其实加入模型后也很容易求解,我不知道为什么不加)。
在上述情况下,当 Z Z Z为由有限个节点构成的凸包(注意,这拓展了[3]的范围)时,可以有可行的解法。有如下定理:

熟悉单纯形法的同学可能已经明白了,如果不确定集 Z Z Z有凸包的性质,那就可以利用类似单纯形法枚举vertex(凸包的定点,忘了中文怎么叫)来得到最优解。定理的证明很简单,首先有引理:凸函数的最优值必定在凸包的定点上。然后利用对偶定理,将问题3关于第二阶段的子问题求对偶。由于relatively complete recourse可知,强对偶成立。再根据引理,就能得到问题4等价于问题3。具体证明参考[1]。
但是,凸包的节点数是关于维数的级数,枚举所有节点是非常困难的。单纯形法通过一个特殊的规则枚举,从而缩短计算时间。针对这个问题,可以使用一种行列生成的算法求解。下面介绍该方法的思路。
考虑枚举 Z Z Z的子集 Z ′ Z' Z′中的 K ′ K' K′个定点,称其为问题5。记这个解为 s ^ \hat{s} s^。很明显这个解会是最优解 s ∗ s^* s∗的上界,因为min的定义域范围更小。那我们就可以利用行列生成的方式,不断地检验 s ^ \hat{s} s^是否为最优解,然后拓展 Z ′ Z' Z′的集合。记 h ( x , z ) h(x,z) h(x,z)为给定 x x x和 z z z下以 y y y为目标函数的子问题。算法步骤如下:
-
从任意 x ^ ∈ X \hat{x}\in \mathcal{X} x^∈X开始;
-
得到 z ^ : = argmin z ∈ Z h ( x ^ , z ) \hat{z}:=\operatorname{argmin}_{z \in Z} h(\hat{x}, z) z^:=argminz∈Zh(x^,z),并构建 Z ′ : = { z ^ } \mathcal{Z}^{\prime}:=\{\hat{z}\} Z′:={z^}。
-
求解针对不确定集 Z ′ \mathcal{Z}^{\prime} Z′的问题5,得到最优的 x ^ \hat{x} x^和 s ^ \hat{s} s^。
-
得到 z ^ : = argmin z ∈ Z h ( x ^ , z ) \hat{z}:=\operatorname{argmin}_{z \in Z} h(\hat{x}, z) z^:=argminz∈Zh(x^,z),如果 h ( x ^ , z ^ ) = s ^ h(\hat{x}, \hat{z})=\hat{s} h(x^,z^)=s^,则算法终止,否则将 z ^ \hat{z} z^加入集合 Z ′ \mathcal{Z}^{\prime} Z′,返回3。注意,这里加入 Z ′ \mathcal{Z}^{\prime} Z′在模型中的体现是分别在目标函数和约束中加入一项。
第4步的内在逻辑是: s ∗ = max x ∈ X min z ∈ Z h ( x , z ) ≥ min z ∈ Z h ( x ^ , z ) = s ^ ≥ s ∗ s^{*}=\max _{x \in \mathcal{X}} \min _{z \in \mathcal{Z}} h(x, z) \geq \min _{z \in Z} h(\hat{x}, z)=\hat{s} \geq s^{*} s∗=maxx∈Xminz∈Zh(x,z)≥minz∈Zh(x^,z)=s^≥s∗。所以如果 h ( x ^ , z ^ ) = s ^ h(\hat{x}, \hat{z})=\hat{s} h(x^,z^)=s^, s ^ \hat{s} s^必定等于 s ∗ s^* s∗。相反,如果 h ( x ^ , z ^ ) < s ^ h(\hat{x}, \hat{z}) < \hat{s} h(x^,z^)<s^,说明这个 z ^ \hat{z} z^是会导致约束被违背的,需要加入集合中。这一段和前面benders那一段分析类似。
行列生成的方法迭代次数最多是不确定集 U U U的极点数量,也就是 O ( p ) O(p) O(p),要小于benders。
我们已经知道问题5是相对好解的,那么影响算法效率的核心部分就是第4步中求解 z ^ \hat{z} z^的过程。这个问题可以写成问题6:

这个问题里有两个变量, z , y z,y z,y。要注意这个问题和RO的区别。在RO中, z z z不是决策变量,而是要对所有 z z z满足条件。这里的问题只是一个双决策变量的问题。我们用KKT定理处理内层的max问题。KKT定理也是OR,OM的同学应该很熟悉的了(虽然我也忘了),推广了拉格朗日乘数法到不等式形式,可以处理凸函数的约束。简单回顾一下:

其中 ∇ \nabla ∇是梯度符号。
所以,问题6就可以reformulation成如下问题7,进而求解:

这就是一个容易求解的问题了。
其实我有一点不太明白,为什么这里要用KKT呢?为什么不考虑对内层做对偶?在线性约束下,KKT应该是比较慢的方法。
情况三:可近似求解
ARO最经典的做法应该是第三种。前文的两种解法各有其局限性,第一种适用范围不广,第二种求解速度不快。因此有了第三种方法,采用一些近似手段。这种近似主要基于affine decision rule。下面我们具体介绍这一内容。
Affine decision rule
所谓的affine decision rule (简称ADR),就是在问题1中,将 x t ( v t ( z ) ) x_t(v_t(z)) xt(vt(z))关于 z z z的形式固定为仿射函数的形式。实际上这个函数形式应该是不固定的,这也是处理的难点。在第2种情况中,我们用枚举节点的形式对 z z z赋值,避免了不同复杂函数形式带来的问题。在ADR中,通过处理成仿射函数形式,将其转化为线性约束。但是,转化为线性约束的过程本身就缩小了搜索范围,因此这个解是原先最优解的下界。其实,我们只需要转化为凸函数形式,但可以证明,凸函数形式只能写成仿射函数形式。问题1变成解决以下Affinely Adjustable Robust Counterpart (AARC) 问题:

此外,为了得到robust linear constraints,我们还需要使用fixed recourse,不然 x x x的参数上还会有 z z z项,导致二次项出现;并令 v t ( z ) v_t(z) vt(z)本身为线性形式。有如下定理:

感觉挺明显的,就不需要证明了吧。
Piecewise affine decision rule
尽量考虑更多可处理的 x t ( v t ( z ) ) x_t(v_t(z)) xt(vt(z))的形式总是好事,因为这样能拓展我们的可解范围。分段放射函数是有必要考虑的。可以考虑以下例子。
在库存管理inventory中(管科出身同学唯一懂的东西),一种常用的库存管理策略是make to stock(另一种是make to order)。意思是,给出一个best的库存下界,每次检查库存量时,若低于下界,则补货,否则不补货。那么补货量 x t x_t xt就会被描述为如下形式:

其中 θ t \theta_t θt为 t t t时期的最佳库存量, d t d_t dt为需求, y t y_t yt为实际库存量。很明显这是一个分段函数。尤其是当 t t t变大时,将较小的 t t t带入后续函数,会分成更多个分段。因此, x t x_t xt可以描述为以下形式,并进一步简化为后续形式:

这时AARC中的 Z ′ Z' Z′就拓展为三部分了。这个不确定集被称为lifted uncertainty set,对应的AARC也被称为Lifted AARC (LAARC):

但是这个不确定集 Z ′ Z' Z′并不是凸的。为了解决这个问题,我们考虑fixed recourse下的情况,记为问题11;并令 Z ′ ′ : = C o n v e x H u l l ( Z ′ ) Z^{\prime \prime}:= ConvexHull (Z^{\prime}) Z′′:=ConvexHull(Z′),记为问题12。有如下定理:

<其实我也不是特别懂第二步>。详细请看[1]。总而言之,求解目标变为问题12。 Z ′ Z' Z′可以表述为如下形式:
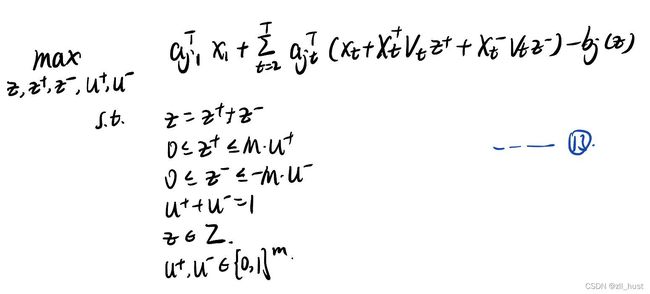
这个表示的好处在于,我们可以进一步将验证问题12中的约束转化为如下MILP问题:

最后,我们可以给出在 Z Z Z为budgeted不确定集下一个很好处理的性质:




证明不算复杂,但非常有趣。
Dual decision rules
以上内容出自[1]。在[2]中,还记录了一些近似求下界的方法。其中,对情况二的精确解算法中,如果对 Z Z Z非凸包的情况,如果依旧节选一些点进行操作,也能得到近似下界。当然,可以选择更有效的选择有限子集的替代方法。此外,[2]还提到了一种Dual decision rules。不过还没看,暂且留个坑。
TODO
下一章将进入分布式鲁棒优化DRO的学习,这是最有趣的一部分。在此之中还会穿插conic programming的知识。可惜的是,博主下周三要期中考试,得先停更复习。呜呼,万恶的考试!
参考资料:
[1] Erick Delage. Quantitative Risk Management Using Robust Optimization Lecture Note. https://tintin.hec.ca/pages/erick.delage/MATH80624_LectureNotes.pdf
[2] Ihsan Yanıko ˘glu, Bram L. Gorissen, Dick den Hertog. A survey of adjustable robust optimization. European Journal of Operational Research.
[3] Bo Zeng, Long Zhao. Solving two-stage robust optimization problems using a column-and-constraint generation method. Operations Research Letters.
7. 分布式鲁棒优化和锥规划
虽然还没开始考试,但我懒得复习了。
从这章开始,将进入RO里面比较难的一块内容,分布式鲁棒优化(DRO)。
分布式鲁棒优化概述
我们在前面已经了解过基础的RO了。他解决的是一个这样的约束:

问题1是一个RO的RC形式。当我们不知道随机变量 ξ \xi ξ属于什么分布的时候,给定一个 ξ \xi ξ可能出现的不确定集 Z Z Z,保证最优解对其中任意的 ξ \xi ξ鲁棒。
DRO尝试解决类似如下的问题:

问题2是一个DRO问题的例子(不是普遍形式)。有很多内容值得说明。首先,目标函数变成了期望值,这与我们第一章将的SP类似。其次,约束中出现了概率的形式,这与CCP类似。此外,概率 ξ \xi ξ不再属于某个不确定集 Z Z Z,而是服从针对某个分布 P \mathbb{P} P,这个分布 P \mathbb{P} P又属于一个分布的集合 P \mathcal{P} P。注意,这里的sup是下确界,对于max,不了解的同学可以自行百度。至于这里为什么要用sup而不是max,说实话我也不是很清楚,包括后续的测度、Borel σ − \sigma- σ−代数等实变函数概念我也没学过,只能暂时忽略这些细节内容。
这样看DRO的特点就很明显了。RO中的随机变量是完全未知分布的,SP中随机变量是完全已知分布的,DRO则介于两者之间,给定一个被称为模糊集(ambiguity set)的随机分布集合 P \mathcal{P} P,使得问题的解对其中所有分布都保持鲁棒。针对每个特定的分布,处理方式与传统的SP或者CCP大致类似。我们之前提到过,RO的缺点是过于保守,SP则过于不保守;DRO则处于二者之间。
依照我们第二到四章关于RO的内容,针对这种范式,需要解决的问题很明显是以下两个:1. 如何解决这类问题?2. 如何构造模糊集 P \mathcal{P} P?接下来,我们从一个熟悉的问题引入。
VaR的DRO例子(上)
在第四章中我们已经提到过VaR的概念了。大概意思是在一个给定的置信度下,最大的可能损失值。以此为目标的问题可以写出如下形式:

这里 γ \gamma γ是VaR值, w w w可以理解为一组股票的投资组合也是决策变量, x x x为损失值。与之前的讨论相同, x x x一般为随机值。在RO中,我们构建以下RC:

得到问题4的RC后,我们一般通过股票的历史数据,进一步确定不确定集 U U U的形式(见第三、四章)。这个问题通过DRO建模,则为以下形式:

很明显,构建模糊集 P \mathcal{P} P也需要通过历史数据,或者说,data-driven。假设我们计算得到样本的均值 x ˉ \bar{x} xˉ和协方差矩阵 Γ \Gamma Γ,以此来估计真实值的均值和方差,我们可以通过这两个最经典的数字特征来描述模糊集 P \mathcal{P} P中的随机变量,规定他们的均值和方差等于已知值。注意 Γ \Gamma Γ应该是一个半正定矩阵。
在RO中,我们接下来会对问题4中的约束1构造子问题,再通过reformulation得到可解的形式。对问题5,我们依然对约束1构造子问题。约束1的左侧等价于如下子问题:

DRO和RO的一个区别就在于,因为要描述随机变量的数字特征,所以需要使用积分形式。应该很好理解几个约束对应的内容。在这个问题中,决策变量不再是某个参数,而是 P \mathbb{P} P的分布函数。<这里最好不要写成密度函数,似乎不是所有概率测度都有密度函数。>为了方便理解,可以写出 P \mathbb{P} P为离散分布时的情况:

其中 x ^ \hat{x} x^为不同情况下的 x x x的实现值。这样就很好理解了。而且,这个问题其实已经是一个有限维度、有限约束的LP问题,可以直接求解。这种模型实际上可以称为一种Scenario-based model。scenario这个词经常出现在不确定性问题的文献中,基本上用来表示不同的可能情景。
当然,问题7不是我们的重点。在RO中,求解的难点是不确定集为无限集的情况,也就是问题6。此时决策变量是无限维的。在处理这个问题前,可以先对问题6做一点简化:

应该容易看懂这个变换,并不影响求解,只是为了简化问题。注意这里的 ∑ \sum ∑是一个 n + 1 n+1 n+1维的正定矩阵, S + + n + 1 S_{++}^{n+1} S++n+1为 n + 1 n+1 n+1维正定矩阵的集合。所以,问题变为如下形式:

如何对问题8进行reformulation呢?答案依旧是对偶定理。但是,这里需要用到的不再是简单的LP的对偶,而是锥规划的对偶。我们暂时把问题8搁置,简单介绍一下锥规划。
锥线性规划基础
我第一次了解锥(cone)的概念是在在benders分解里。简单来说,锥是一个满足一个条件的集合:

上图右边是一个二维平面内的例子。这个定义和例子能直观地说明锥的定义,但是我们接触锥的最终目的是为了求解对偶,而不是单纯了解一个概念。因此我们重新从LP的视角认识锥。
实际上,对偶理论以及线性规划的整个框架都基于不等式符号 ≤ \leq ≤,基于这个符号可以证明Farkas定理和强对偶理论,进而得到我们已知的体系。我们认识中的 ≤ \leq ≤是定义在实数集上、从纯代数的角度理解的。 x ≥ y x\geq y x≥y 可以进一步写成 x − y ≥ 0 x-y \geq 0 x−y≥0。这又可以理解为, x − y ∈ R x-y \in \mathbb{R} x−y∈R。换句话说,这个定义的本质是实数集 R \mathbb{R} R。而我们的理论体系,Farkas定理和强对偶理论等定理的证明,则是依据下图左边所示的五个性质:

仔细想想,确实是这五个简单的性质构建了整个基于实数的LP的运算体系。可以进一步思考,是否可以赋予 ≤ \leq ≤其他含义,在保持这些性质的基础上,进一步拓展LP的范围?这就是右边的内容,从几何意义上理解。
在右图中,我们将集合 K K K定义为了 n n n维非负实数集 R + n \mathbb{R}^n_+ R+n。将所有 ≥ 0 \geq 0 ≥0改为了 ∈ K \in K ∈K,所有元素改为向量。如果一个 K K K有a, b, c三个性质,称其为pointed cone。这三个性质分别被称为closed under addition, conic, pointedness。性质如同字面意思一样很好理解。<[1]中只说明了 R + n \mathbb{R}^n_+ R+n在几何意义下满足这三个性质,而没有说明左边5个都满足,我不太清楚为什么。也非常容易证明这些都是能满足的。>
根据上面的分析,我们就有机会对 R + n \mathbb{R}^n_+ R+n进一步推导得到类似LP的结论。那么,除了 R + n \mathbb{R}^n_+ R+n和实数集外,还有其他类似性质的集合吗?
答案是肯定的,不然也不会介绍这些。下图是两种符合该条件的锥

这两个锥都是由很熟悉的两个概念引申出的,分别由2范数和半正定矩阵定义。三个性质的证明也非常简单:

这两个锥分别对应了两种不同的 ≤ \leq ≤的体系,可以理解为,定义了两种有一定优良性质的集合( Q ( n + 1 ) Q^{(n+1)} Q(n+1)和 S + n S^n_+ S+n)和排序(两个集合对应的 ≤ \leq ≤),满足pointed cone的三条性质。下面我们进一步说明满足这三条性质的集合存在类似对偶理论的结论。

上面的结论拓展了LP的对偶到pointed cone的对偶。其中<>是内积符号,定义如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IAsxHQOR-1649906681795)(C:\Users\zll\Desktop\assets\7\7-28.png)]](http://img.e-com-net.com/image/info8/cef7748799c04192aff984bc16772e06.jpg)
对于向量而言,内积和平时是一样的,但这里的内积是针对 E E E的,而不是针对 R m \mathbb{R}^m Rm,因此在对偶问题中没有写成内积的形式。
问题D引入了一个新符号 K ∗ K^* K∗,称为 K K K的对偶锥。其定义如下:

这里我们给出了3个例子。第一个例子是二维平面中的一个夹角在90度内的锥。向量 y y y与其中某个向量 x x x内积非负,就意味着 x x x与 y y y的夹角小于90度。于是我们找这个锥的边界形成直角的边,在右边用蓝色虚线表示,这之间的区域就是 K K K的对偶锥。对于二维非负区域而言,两条边正好构成直角,因此其对偶锥就是自己,成为self-dual。还能进一步证明,前面提到的二阶锥、半正定锥也都是自对偶的。(这个证明不算复杂,但我没怎么看懂,想了解的可以自行搜索)可以进一步拓展结论如下:

到这里我们就基本建立了基于pointed cone的线性规划框架。问题D约束1其实只是说明 y y y的仿射函数属于一种类型的锥。如果这种类型的锥是二阶锥,问题就是二阶锥规划,SOCP;如果锥是半正定锥,问题就是半正定锥规划,SDP。回到第三章关于椭圆不确定集最后的子问题:

其实约束本身也可以写成SCOP的形式。而这些问题,都是锥规划领域研究已久的问题,有现成的求解器和求解手段处理。
但我们的目的还是求对偶,即从问题P到问题D。回顾第三章,求对偶就需要构造拉格朗日松弛。拉格朗日松弛的目的是为了将约束加入目标函数,对违背约束的情况给予惩罚。问题P中约束1的惩罚容易构造,但约束2的 x ∈ K x\in K x∈K又该如何惩罚呢?

看到括号中LP的情形,大家肯定有所猜测了。迄今为止我们的一起操作都是基于LP的情况,做某种映射,这里也不例外。结论如下:


构造出拉格朗日对偶之后,就可以按类似第三章的操作构造对偶问题:

在第三章中为了证明min-max=max-min,我们使用了强对偶定理,但没有证明;这里也可以证明锥线性规划下的强对偶:

但也暂时挖一个坑,日后再写。
本节所有证明均来自[1],说明可能都不够严谨,有不清楚的可以参考[1]。
VaR的DRO例子(下)
有了处理锥线性规划的工具,就可以继续处理之前的DRO了。回顾一下之前的问题,我们需要对问题8进行reformulation处理:

其中 ∑ \sum ∑是一个半正定矩阵。很明显,接下来需要将其转化为SDP求解。构造对偶问题:


这里利用了我们前一小节证明的内容。注意我们这里把 P ≥ 0 \mathbb{P}\geq 0 P≥0拿到外面了,因为放到里面还需要再定义一个内积。

回忆构造对偶,就是把sup和inf换个位置,再提取出决策变量相关的约束。需要注意的是,在这里的子问题中, P \mathbb{P} P是没有求和等于1的约束的,这条约束隐含在里面,所以只需要示性函数那条约束大于0出现, P \mathbb{P} P就可以把那个点的密度调到无穷大,甚至大于1,使得解趋向正无穷。因此能得到大括号中的结论。
但是,这里又有个新的问题:新得到的约束依然是无限的(示性函数那条中的 ∀ x \forall x ∀x)。因此我们还需要进一步处理示性函数的约束:

约束可以写出A, B两个约束,并分别按1. 和2. 处理。2中又用到了一次强对偶,但这次的对偶只是LP的对偶。最后构造 q ( x ) q(x) q(x)的正定矩阵的时候可以写出 [ x , 1 ] [x, 1] [x,1]的二次型来构造。最终问题就能转化成如下的SDP形式:

最后的最后,还要证明sup-inf=inf-sup。这似乎与前面锥规划的强对偶又不完全一样,因为合适针对概率测度 P \mathbb{P} P的。[3]中的Proposition 3.4告诉我们一个证明方法。我们只需要说明如下内容:

定理证明的关键在于:1. 将约束写出第一个红字的线性形式;2. 证明结果有第二个红字的形式,类似于说明这个解为上一部分中锥线性规划对偶里的严格可行解。由于定理的具体证明还需要很多篇幅(主要是我也没看…)所以暂时不继续深入。到这里,我们终于将问题5转化成了可以用SDP求解的形式。属实麻烦了。
以上例子来自OR的一篇文章[2]。也算是DRO的一个application了。日后做实践篇的时候,有时间再翻原文出来详细看看。
本章类似于第二章RO中的求解方法概述。与RO中的不确定集相同,DRO中最重要的还是模糊集。下一章我们将考虑其他模糊集。
参考资料:
[1] 苏文藻. 分布鲁棒优化简介. “数据驱动的优化理论、算法与应用”暑期学校. https://www.bilibili.com/video/BV1bM4y1L7R7?spm_id_from=333.337.search-card.all.click
[2] Laurent El Ghaoui, Maksim Oks, Francois Oustry. Worst-Case Value-At-Risk and Robust Portfolio Optimization: A Conic Programming Approach. Operations Research.
[3] Alexander Shapiro. On duality theory of conic linear problems.
8. 矩约束下的分布式鲁棒优化
上一章从一个例子引入了DRO,并介绍了一个给定均值和方差的模糊集DRO问题例子。对于这类模糊集,我们统称为矩(moment)约束,均值和方差分别对于一、二阶矩,这也是一般文献中会考虑的。
上一章中的矩的特点是已知,但实际上,现实生活中一般只能得到样本的均值和方差,用来近似替代实际值。这也会带来很大的不确定性。因此,有必要考虑矩不确定性。这章的第一部分主要参考[1][3]介绍这部分内容。
此外,这章的第二部分还会介绍另一种解决矩模糊集下的方法,主要参考[2]。
矩不确定性
回顾上次的内容,我们实际上解决了一个如下模糊集:

其中均值和方差都是样本中估计的。因此我们希望处理不确定均值和方差的情况。[3]提出了一个模糊集:

其中 C C C是随机变量的支撑集(表示该随机变量可以取到的所有值的集合)。第一个约束表示 P \mathbb{P} P是一个概率测度,支撑集为 C C C;第二个约束表示真实均值与样本均值的差在一个椭圆内,这个椭圆的大小由参数 γ 1 \gamma_1 γ1决定;第三个约束近似表示真实方差的范围在 γ 2 \gamma_2 γ2内,注意 γ 2 \gamma_2 γ2是一个半正定矩阵,LHS(left hand side)也是一个矩阵,符号 ⪯ \preceq ⪯是定义在半正定锥上的符号,表示RHS-LHS为一个半正定矩阵。
有两点需要注意:1. 第二个约束并没有左侧的lower bound。这是因为加入之后不容易处理。2. 第三个约束并不是真实方差。真实方差应该使用真实均值 μ \mu μ而非样本均值 μ 0 \mu_0 μ0。因此是一个近似约束。这点会在后续讨论。
因此,我们得到基于该moment uncertainty的DRO问题1。解决问题的操作与上一章求解VaR例子的方法基本相同。首先我们得到子问题:

上一章中我们忽略了左侧的简单转换。这是在经典RO中的基础操作,转化为epigraph的形式。对于右侧的子问题,需要注意的是约束(1)从关于均值的标量不等式转化为了SDP的不等式。这是为了简化后续操作。这样转化是基于如下的舒尔补:

接下来基于问题2构造拉格朗日对偶,注意对矩阵写成内积形式,对最后一个约束不加入对偶:

接下来交换sup和inf:

最后得到对偶问题:

这些应该是驾轻就熟的。对于该问题,可以看到变量 s s s和 P P P没有出现在第一个约束中,只在定义域上有约束;而定义域的规定半正定性的约束可以使用前面提到的舒尔补化简。因此对偶问题还可以进一步简化:

这里面运用了一些半正定矩阵的性质,看来线性代数还是要加强。
将最优值带入问题3最终得到对偶问题如下:

约束1其实是一个二阶锥约束。
记得在上一章中,为了证明强对偶成立,我们使用了[5]中的proposition 3.4。在这里我们也需要做同样的证明:

证明的核心是两个:一个是写作 A A A的线性形式,另一个是证明 b b b在 A ( C ) − K A(\mathcal{C})-K A(C)−K内部。证明完成后就可以将reformulation的结果带入问题1:

之前我们提到第二个约束是一个二阶锥约束。但其实,真正影响求解的还是第一个约束,因为 ξ ∈ C \xi \in C ξ∈C是一个无限集。在[3]中使用了椭球算法证明可以在多项式时间内求解该问题,在这里我们就不进一步说明了。余下的一个问题是,如何确定模糊集的参数 γ 1 , γ 2 \gamma_1, \gamma_2 γ1,γ2。
对于模糊集来说,很明显两个参数越大,模糊集的范围就越大,里面包含真实分布的概率就越大。但是,由于求解的是鲁棒优化,最终解要符合集合中所有分布,因此太大的模糊集又会造成反效果。如何balance这两项内容是一个挑战。
实际上确定参数的大小相当于确定真实的均值和方差离样本均值和方差的距离。可以猜测,由大数定理,样本容量很大的时候距离应该很近。进一步bound这之间的距离需要使用概率论中的集中不等式(concetration inequalities)。
在处理模糊集中的约束2之前,我们先处理约束2中方差为真实方差的情况。并给出一个上界的假设,对约束进行处理:

这里我们要求该分布有上界。在后面我们会看到这样操作的目的。经过如上图的处理后,式子从由 ξ \xi ξ表示的约束变成了由 ζ \zeta ζ表示。 ζ \zeta ζ有一些良好的性质:

在此之上,我们对 t t t赋值,就能得到想要的bound:

可以观察到 t t t的取值中有 R R R。这里用到的集中不等式如下:

这个不等式告诉我们,如果只改变函数 g g g某一项之后,与原函数的差距可控,则对 g − E [ g ] g-E[g] g−E[g]会有一个bound的界。为了应用到我们的问题上,需要进行如下操作:

这里还没有操作完。挖个坑先。总之,通过之前对 P \mathbb{P} P的上界假定,我们可以进一步算出 E [ g ] E[g] E[g]的bound,从而带入到不等式中,得到关于 g g g的bound。这样我们就证明了,在模糊集的约束2中,如果方差是真实方差,就可以得到一个有保障的 γ 1 \gamma_1 γ1。当然,这里要求 P \mathbb{P} P是有界的,这显然不太好,因为包括正态在内的很多分布是无界的。因此苏老师在一篇MP上拓展了这个定理到一些清尾的分布上,指的是和正态类似, x x x趋向无穷时概率趋向无穷的分布。
为了处理约束2为样本方差的情况,有以下基于集中不等式推导得出的定理:

(偷懒了懒得写了)结合上述定理,就可以说明模糊集的约束2是有bound的。同样, γ 2 \gamma_2 γ2也可以用类似集中不等式得出。可见,DRO的公式推导型文章真的很麻烦。详细请原文[3]。
矩不确定性应该还有别的表述方式。[6]中就提到一个模糊集:

这里不再使用方差,而是离差。据说这种模糊集可以使用lifted uncertainty set很简单地转化为RO。个人认为,因为模糊集包括RO中的不确定集确实很多,没必要在初学时全部掌握,见招拆招、要用时再看即可。
下一部分内容来自[2],是[3]的作者数年之后写的,似乎和[3]不完全一样。我认为有必要了解。
另一种方法
在第二种方法中,我们首先从以下一阶矩约束开始:

这里有些符号和之前不同,但应该很好认出。 Z Z Z是支撑集, μ \mu μ是已知的均值(可以理解为之前说的样本均值), M M M是测度空间, D \mathcal{D} D为模糊集。注意,为了得到更general的结论,在这里我们不要求 h ( x , ξ ) h(x, \xi) h(x,ξ)是线性函数。
写成epigraph后写出子问题:

求拉格朗日对偶:

由于之类没有矩阵的约束,因此不需要内积形式的惩罚项。对偶问题如下:

强对偶定理的证明依旧需要用到[5]中的proposition 3.4。因此我们可以得到问题7的等价问题:

问题9将问题8中的决策变量 r r r简化了。在进一步处理问题9之前,我们讨论一下问题8的性质。
<对于任何凸集中最优解对应的点,也就是多面体的顶点,只需要 m + 1 m+1 m+1条约束就可以确定这样的点(其中 m m m是 z z z的维度)。或者说,对于任何一个点,都可以通过 m + 1 m+1 m+1条约束构造出一个多面体,让这个点变成它的定点。由于问题8有无数条约束,最优解应该可以用 m + 1 m+1 m+1个 z z z刻画出>(其实这里我没怎么看懂)。因此,问题8可以转化为:

同样的,可以得到对应的原问题。但是我们依然不知道 z i ∗ z_i^* zi∗的取值。但是,[5]给出了如下定理:

虽然在这里约束2是非线性的,但问题已经变成一个有限维的问题。进一步的,考虑到 h ( x , z i ) h(x, z_i) h(x,zi)并不一定线性,我们进一步考虑特殊的 h h h下的结果。有如下定理:

定理的证明只需要分别证明问题7和问题12的解能相互转换即可。
下面的推论非常有效:

这个推论其实已经很普遍了,可以解决大多数问题。当然,对前面提到的分段凹的情况,还可以有如下定理:

在证明之前需要用到:

这个我们暂不详细说明。利用8.6,可以证明8.7:

到这里我们初步结束对问题6的模糊集的处理。接下来考虑上一章中考虑的二阶矩约束下的模糊集:

注意,为了简化问题,这里的参数都是标量而不是向量。随机变量 ξ \xi ξ不是向量,而是一维变量。
处理这个模糊集,可以构造一个lifted space和对应的随机变量:

构造这个的目的是为了带入之前的模糊集中:

神奇的事情发生了:问题14和问题15应该是等价的。注意问题14和15的模糊集中对应参数的含义不一样,要弄清楚。这样做的原因在于,方差的矩约束其实可以转化为均值的约束,都有期望=某个数的形式。接下来就可以用之前分析的方法处理问题15,得到问题14的解:

由于问题15中考虑了两个随机变量对应的约束,所以reformulation后对偶问题的向量 q q q有两个标量 q 1 , q 2 q_1, q_2 q1,q2。
因为平板不再身边,后续暂时用截图。
再考虑一个如下例子:

这里对方差的约束变成了 ⪯ \preceq ⪯。依然构造lifted space:

进行reformulation:

这里最后一项为内积。reformulation的方式与前一节类似。最后转化为epigraph的形式:

这个例子的内容就大致结束了。[2]中还有针对本章第一节的内容,可以用相同方式处理,但是因为要用到一些非线性鲁棒的知识,所以暂时不写。可以看出的是,这一种方式与上一节的方法差距还是很大的,即使[2][3]的作者相同。
对此,我也咨询了老师,老师的解释是目前后一种lifted的方法使用的更广泛。看来还需要进一步理解lifted。
在下一章中,我们将讨论另一种模糊集建模下的DRO。
[1] 苏文藻. 分布鲁棒优化简介. “数据驱动的优化理论、算法与应用”暑期学校. https://www.bilibili.com/video/BV1bM4y1L7R7?spm_id_from=333.337.search-card.all.click
[2] Erick Delage. Quantitative Risk Management Using Robust Optimization Lecture Note. https://tintin.hec.ca/pages/erick.delage/MATH80624_LectureNotes.pdf
[3] Erick Delage, Yinyu Ye. Distributionally Robust Optimization Under Moment Uncertainty with Application to Data-Driven Problems. Operations Research.
[4] Wolfram Wiesemann, Daniel Kuhn, Melvyn Sim. Distributionally Robust Convex Optimization. Operations Research.
[5] Alexander Shapiro. On duality theory of conic linear problems.
[6] 章宇。鲁棒优化及其在车辆路径问题中的应用简介。https://www.bilibili.com/video/BV1tK4y1e7fQ?spm_id_from=333.337.search-card.all.click
9. Wasserstein下的分布式鲁棒优化
看到一篇知乎文章“Distributionally Robust Optimization 高引论文”,挺有意思的,里面说“DRO推公式是个大坑,慎入。难度略大,对分析学的要求会高一点”,确实如此,所以我一个管理学学生没学过实分析凸分析泛函分析随机过程,拿什么学数学… 流下了没有数学的眼泪。所以今年水完之后,明年不要急着写文章了,先打好数学基础…
基本上到理论部分最后两章了,打算这一章介绍一个Wasserstein的例子,不深入分析[2]。然后再学一学ADRO,简单写一章介绍。还有很多模糊不清楚的地方,后续再看两篇应用的paper,根据算法设计、应用的需要来决定后续学习。应用篇应该会再开一个系列。
Wasserstein Distance
上两章我们构建了基于矩约束的模糊集,称为moment-based model。这当然是有局限性的,因为矩不能完美地刻画一个分布。最近几年非常火的一种模糊集是针对概率分布之间的距离的,被称为metric-based。也就是说,需要找一种衡量两种概率分布之间距离的手段,距离越近显然越好,用于对比的初始分布可以通过历史数据得到。记如下分布为经验分布(empirical dirtribution):

不难猜测,标题的Wasserstein distance就是测度分布的一种方式。它的定义如下:

解释一下这个距离,这个定义做的事情其实就是找到一个近似的联合分布 Π \Pi Π,满足其边缘分布分别为两个分布 Q \mathbb{Q} Q和 P \mathbb{P} P。然后,在计算距离时,对所有点积分,每个点从 Q \mathbb{Q} Q到 P \mathbb{P} P的距离通过一个transport cost表示。这个函数 d d d也就控制了计算距离的方式。DRO的模糊集就可以通过这个距离定义的邻域得到。
Logistic Regression
Wasserstein distance-based的DRO模型有许多应用,本章介绍一个logistic regression中的应用例子。

这个回归问题的输入是一个 n n n维特征向量 x x x,输出一个二元标签 y y y。他们之间满足一个条件概率的关系。需要估计这个关系中的参数 β \beta β。按照传统极大似然估计下得到的 β ^ M L E \hat{\beta}_{MLE} β^MLE并不是真实分布的期望,而是经验分布的期望。虽然在样本容量很大的情况下两者近似相同,但在样本小的情况下不完全一致。因此我们构建如下的DRO问题:

当模糊集合适时,真实分布就会包含在模糊集中。模糊集由Wasserstein distance定义。其中transport cost函数如图所示。参数 κ \kappa κ权衡了 x x x和 y y y对距离的影响。其中对 x x x可以用任何范数来表示, y y y是二元变量,因此用绝对值表示,若 y ≠ y ′ y\neq y' y=y′,绝对值的值等于2,正好消掉 κ / 2 \kappa/2 κ/2的分母。
下面我们专心处理问题1。首先是写成epigraph形式,根据模糊集重新书写子问题:

这里的子问题书写可能比以前麻烦一些。注意目标函数中是对真实分布进行积分。问题2可以做一些简化。注意到经验分布其实是一个离散分布,因此可以写成条件分布的形式:

红色波浪线部分是 Q i \mathbb{Q}^i Qi的定义。为了后续处理方便,将 Q i \mathbb{Q}^i Qi继续分解:

最后将 d d d带入约束2:

注意这里 y y y的绝对值被消除了,因为 Q + − 1 i \mathbb{Q}^i_{+-1} Q+−1i已经确定了 y y y的取值,然后又将 y ^ \hat{y} y^分成两组。
到这里我们的简化就告一段落了。这个形式已经和我们之前见过的差距不大。只不过,之前的问题只需要对一个分布(向量)积分,而现在的问题需要对多个积分并求和(目标函数中)。
接下来又是熟悉的取对偶环节:

为了方便后续化简,这里加入了红色部分的 1 / N 1/N 1/N。

交换inf和sup得到对偶问题。由于红色波浪线部分可以提出求和符号,因此在问题6中约束可以分开写(相对于 i i i)。
在进入下一步处理之前,还需要使用之前的定理验证强对偶定理成立。这里暂时不写。
对偶问题6还可以通过一个共轭函数的性质做简化:

其中 ∣ ∣ ∣ ∣ ∗ || ||* ∣∣∣∣∗表示对偶范数。这里面的内容又很多,我也不熟悉,所以暂时不证明。
最后再做一点简化:

在inf里加上 β \beta β的决策变量,问题就变成了一个有限维的凸优化问题。全部工作就暂时结束了。
据苏老师所说,一般建模型文章都结束在这一步。之前的章节我们也大致是在这里停止的。不过我个人还是偏向应用、算法类文章,后续应用篇的时候再看看他们的做法吧。
下一章可能会写ADRO,也可能先看两篇应用。
[1] 苏文藻. 分布鲁棒优化简介. “数据驱动的优化理论、算法与应用”暑期学校. https://www.bilibili.com/video/BV1bM4y1L7R7?spm_id_from=333.337.search-card.all.click
[2] Peyman Mohajerin Esfahani, Daniel Kuhn. Data-driven distributionally robust optimization using the Wasserstein metric: performance guarantees and tractable reformulations. Mathematical Programming.
10. 自适应分布式鲁棒优化
时间过的很快,已经来到第十章了。不出意外的话,近期内这章会是理论部分的最后一章。在这章之后我打算新开一帖,读一些应用类论文。
ADRO结合了前面两大块内容,ARO和DRO的知识。今天的内容主要根据[1]介绍。[1]主要基于第八章和第九章前半部分提到的基于一、二矩的模糊集。让我们来看看MS偏数学的文章是什么水平。
特殊情况下的精确求解
在第七章ARO的解时我们提到,ARO没有很general的求解框架,只能针对一些特殊情况求精确解,例如fixed recourse, affine decision rule。ADRO也是一样。[1]的第一部分介绍了一种可精确求解的类型。首先给出二阶段ADRO的一个表示:

这里直接将问题分开写成多阶段的形式。第一阶段here-and-now决策变量为 x x x,第二阶段wait-and-see决策变量为 y y y。需要注意的是,这里和我们第五章中提到的最广义的ARO问题不一致的地方是, y y y和系数 d , B d, B d,B不受随机变量 z z z的影响。此外,还需要引入一些假设:

以及,问题要满足relative complete recourse。回忆第五章,我们提到了三个概念:fixed recourse,relative complete recourse,affine decision rule。这里的假设和当初不完全一样。fixed是指 y y y的系数不受 z z z影响,affine是指 y y y本身与 z z z的关系为仿射函数。relative是指,对任何第一阶段的解 x x x,第二阶段都可解。所以要注意一下我们目前讨论的问题的特殊性。
我们再考虑如下的二阶锥模糊集:

模糊集的第二个约束和第三个约束是主要内容,第二个约束是一个一阶矩的约束,第三个约束的函数 g g g不一定要取线性函数,因此可以表示方差、离差的上界等约束。
这里提到一个概念:SOC representable set。我也不是很清楚这个概念,找了一些相关资料:


我个人认为对后续影响不大,可以先放一放。
可以写出这个模糊集的lifted模糊集,以及对应的lifted支撑集:

lifted的方法我们在上一章DRO的第二部分用过,但当初没有正面与原先的集合之间的关系,[1]针对这个lifted给了一个性质:

我也不是非常理解(-_-||),关键是注意红星的部分。
在正式处理前,还需要对支撑集 W ˉ \bar{W} Wˉ给一个假设:

现在我们就可以正式开始对问题2进行reformulation了。

问题的不确定性集中在第二阶段,因此将第二阶段的模糊集写成子问题得到问题3:

问题3写成拉格朗日对偶形式,因为约束都是线性的,所以对偶不需要内积:

其对偶形式记作问题4, β 1 \beta_1 β1。注意这里我们没证明强对偶。
接下来对约束中的 Q Q Q取对偶:

这里用到的只是LP的强对偶,可以直接套公式得出。然后对对偶问题的多面体的极点进行枚举,因此问题5是 max { } \max\{ \} max{}的形式,而非LP问题的形式。
将上述处理后的 Q Q Q带入原问题,有:

这里的约束有无限个,相当于一个经典RO问题。对约束取子问题处理:


注意,这里的不确定集范围是支撑集 W ˉ \bar{W} Wˉ,而不是 G \mathcal{G} G。此处的对偶是之前提到的对二阶锥规划的对偶,因此要取内积,这里的 ⪯ \preceq ⪯也是定义在二阶锥上的。注意二阶锥的对偶锥依然是二阶锥。此外,我们依然没证明强对偶。将对偶结果带回问题6,得到:

此时问题就是一个有限约束的线性问题了。但是,由于中间两次对偶的强对偶没有证明,每个问题的解之间只有黑字的弱对偶关系。要证明强对偶成立,可以构造红字的关系,证明问题等价。这里构造的 β 3 ( x ) \beta_3(x) β3(x)其实是问题9的对偶问题,由前面的Assumption可以证明存在可行解,并进一步由不等式关系得到 β ( x ) \beta(x) β(x)。因为有一些地方没太看懂,所以暂时不往后写了。
Linear Decision Rule近似解
[1]还包含了一种使用linear decision rule的近似解。LDR其实affine decision rule。考虑如下问题:

[1]认为这和问题1中的 β \beta β一致,但我觉得不太一样。我们在第五章也提到类似情况。在问题11中,约束要求对所有 z z z都满足,但在问题1中,只需要对计算期望值的 z z z满足即可。问题11与问题1的另一个差别在于 y y y不再是与 z z z无关的。考虑如下LDR:

但是LDR存在一些问题。例如,一些函数形式,例如 ∣ z ∣ |z| ∣z∣,无法用仿射函数表示。因此[1]考虑添加辅助变量:

这里的支撑集与前文的 W ˉ \bar{W} Wˉ一致。在这个辅助变量下,可表示的 y ( z ) y(z) y(z)关系就更多了。因此,问题13有性质: β ( x ) ≤ β E ( x ) ≤ β L ( x ) \beta(x) \leq \beta_E(x) \leq \beta_L(x) β(x)≤βE(x)≤βL(x)。
用前文的reformulation方法,可以得到问题13的如下形式:

这个问题是一个AARO问题,去除了分布式的成分,就可以用已知的ARO方法求解了。
上面描述的两种方法可以简单地拓展到multi-stage的形式,只需要将决策变量 y y y变成 y i y_i yi即可。[1]中还有对LDR其他性质的描述,这里就不多介绍了。
本来想在这章结束理论篇内容,但在咨询了老师后新增了一些读物,可能在未来几天对过去的内容(包括本章)缝缝补补。敬请期待。
[1] Dimitris Bertsimas, Melvyn Sim, Meilin Zhang. Adaptive Distributionally Robust Optimization. Management Science.
[2] Zhi Chen, Melvyn Sim, Peng Xiong. Robust Stochastic Optimization Made Easy with RSOME. Management Science.