基于注意力机制的双向长短期记忆网络的关系分类
Attention-Based Bidirectional Long Short-Term Memory Networks forRelation Classification
论文来源:https://www.aclweb.org/anthology/P16-2034
关系分类是自然语言处理(NLP)领域中重要的语义处理任务。最先进的系统仍然依赖于词汇资源,如WordNet或NLP系统 像依赖解析器和命名实体识别器(NER)获得高级功能。另一个挑战是重要的 信息可以出现在任何位置 这句话。要解决这些问题, 我们提出基于注意力的双向 长短期记忆网络(AttBLSTM)用于捕获句子中最重要的语义信息。 SemEval-2010的实验结果关系分类任务表明我们的方法优于大多数现有方法,只有word vectors.
关系分类是寻找名词对之间的语义关系的任务,对于许多NLP应用程序很有用,例如信息提取,问答系统,传统的关系分类方法使用来自词汇资源的手工提取特征,通常基于模式匹配,并取得了很高的成绩, 这些方法的一个缺点是许多传统的NLP系统被用于提取高级特征。
论文提出了一种新的神经网络Att-BLSTM用于关系分类。模型利用双向长短期记忆网络(BLSTM)的神经注意机制捕获句子中最重要的语义信息。这个模型没有使用任何从词汇资源或NLP派生的特征。论文的特点是使用具有注意机制的BLSTM,它可以自动关注具有决定性作用的词语在分类上,捕获句子中最重要的语义信息,而不使用额外的知识和NLP系统。
相关工作
多年来,已经提出了用于关系分类的各种方法。他们中的大多数是基于模式匹配并应用额外的NLP系统来推导词汇特征。利用从外部语料库派生的许多特征用于支持向量机(SVM)分类。最近,深度神经网络可以自动学习基础特征并已被使用在文献中。最具代表性的进展利用卷积神经网络(CNN)的关系分类。虽然CNN不适合学习远程语义信息,等等我们的方法建立在递归神经网络(RNN)上。使用双向RNN来学习原始文本数据的关系模式。虽然双向RNN可以访问过去和未来的背景信息,范围由于消失的梯度问题,上下文受到限制。要克服这个问题,龙引入了短期记忆(LSTM)单元。
模型
论文中提出了Att-BLSTM模型详情。如图所示:
图一:
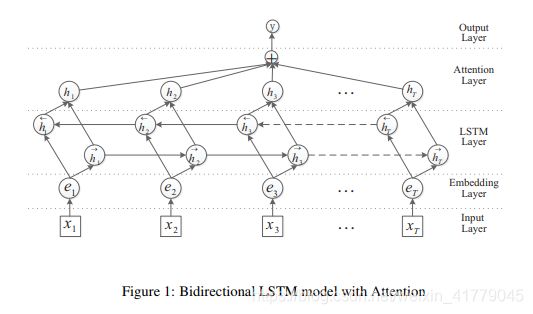
该模型包含五个组成部分:
(1)输入层:输入该模型的句子;
(2)嵌入层:将每个单词映射为低维尺寸矢量;
(3)LSTM层:利用BLSTM从步骤(2)获得高级特征;
(4)注意力层:产生一个权重向量,并合并每个时间步的单词级功能
通过乘法进入句子级特征向量权重向量;
(5)输出层:句子级特征向量最终用于关系分类。
Word嵌入层
给定由T字组成的句子S = {x1,x2,… 。 。 ,xT},每个单词xi
被转换为实值向量ei。对于S中的每个单词,我们首先查找嵌入矩阵Wwrd∈Rdw| V |,其中V是固定大小的词汇表,dw是单词嵌入的大小。 matrix Wwrd是要学习的参数,dw是a超级参数由用户选择。我们通过使用矩阵向量乘积将单词xi变换为其嵌入ei的单词:![]()
其中v i是大小为| V |的向量索引ei的值为1,所有其他位置的值为0。那么句子作为实值被输入下一层向量embs = {e1,e2 ,. 。 。 ,eT}。
双向网络LSTM层
LSTM装置首先克服了梯度消失问题。主要的想法是增加一个自适应机制,它决定LSTM单位保持先前状态的程度并记住提取的特征,当前数据输入。然后是很多LSTM变种已被提出。它增加了恒定误差的加权窥视孔连接(CEC)到相同记忆的门块。通过直接采用当前的单元状态为了产生门度,窥视孔连接允许所有门检查到单元(即当前的细胞状态)使输出门关闭。通常,四个组件合成基于LSTM的递归神经网络:一个输入门it,具有相应的权重矩阵Wxi,Whi,Wci,bi ; 一个忘记门ft与相应的权重矩Wxf,Whf,Wcf,bf ; 一输出门ot与相应的权重矩阵Wxo,Who,Wco,bo,所有这些大门都将被设置为使用当前输入xi生成一些度数,上一步生成的状态hi-1,以及该单元ci-1(窥视孔)的当前状态,用于决定是否接受输入,忘记之前存储的存储器,并输出稍后生成的状态。正如以下方程式所示:

因此,将生成当前单元状态ct使用前两个计算加权和由小区生成的小区状态和当前信息单元。对于许多序列建模任务,访问未来和过去的上下文是有益的。但是,标准LSTM网络按时间顺序处理序列,它们忽略了未来的上下文。双向LSTM网络通过引入第二层来扩展单向LSTM网络ond层,其中隐藏的隐藏连接以相反的时间顺序流动。模型能够利用来自信息的过去和未来。在论文中,我们使用BLSTM。如图所示图1中,网络包含两个子网对于左右序列上下文,它们是分别向前和向后传输。 ith的输出这个词显示在下面的等式中:
![]()
在这里,我们使用元素总和来组合前向和后向传递输出。
注意力机制
最近,Attentive神经网络在广泛的任务范围内取得了成功从问答系统,机器翻译,语音识别,图像字幕等。在这个部分,我们提出了关系的关注机制分类任务。设H是一个矩阵输出向量[h1,h2 ,. 。 。 ,hT]即LSTM生成的图层,其中T是句子长度。句子的表示r由。形成这些输出向量的加权和:
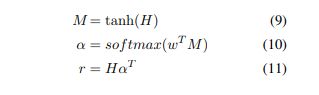
其中H∈Rdw×T,d w是的维数单词向量,w是训练的参数向量,wT是转置。 w,α,r的维数分别为dw,T,dw。我们获得最终的句子对表示用于分类来自:

分类
在此设置中,使用softmax分类器从一组离散的Y类中预测标签y 句子S.分类器采用隐藏状态 h*作为输入:
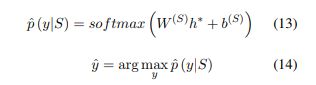
损失函数是负对数似然 真正的类标签y:

其中t∈Rm是一个热表示的地面 真实和y∈Rm是估计的概率 每个类由softmax(m是目标类的数量),并且λ是L2正则化超参数。在论文中,我们将我们将dropout与L2正则化结合起来以减小过度拟合。
正规化
2012提出的dropout,阻止了随机的隐藏单位的共同适应 在前向传播期间省略来自网络的特征检测器。我们引用了dropout嵌入层,LSTM层和倒数第二层。 我们还利用了L2正则化规范 权重向量通过重新调整w得到∥w∥= s, 每当∥w∥> s经过梯度下降步骤后, 如公式15所示。
数据集和实验设置
这个数据集包含9个关系(带有两个方向)和一个无向的其他类。10,717个带注释的示例,包括8,000个用于训练的句子和2,717个用于测试的句子。我们采用官方评估指标来评估我们的系统,基于宏观平均F1-得分为九个实际关系(不包括其他关系)并将方向性纳入其中考虑。使用相同的单词向量(50维)初始化嵌入层。还使用Pennington等人预训练的100维单词向量。由于没有正式的开发数据集,我们随机选择800个句子进行验证。调整了我们模型的超参数在每个任务的开发集上。我们的模特使用训练学习率为1.0,小批量为10将模型参数正式化,其中 L2正则化强度为10-5。我们评估dropout 嵌入层的效果,dropout LSTM 层和dropout 倒数第二层,模型有更好的性能,何时dropout 分别设定为0.3,0.3,0.5。我们模型中的其他参数已随机初始化。
实验结果

结论
在论文中,提出了一种新颖的神经网络模型Att-BLSTM,用于关系分类。此模型不依赖于NLP工具或要获得的词汇资源,它使用带位置指示符的原始文本作为输入。通过评估模型证明了Att-BLSTM的有效性关于关系分类任务。