DIFFACE: BLIND FACE RESTORATION WITH DIFFUSED ERROR CONTRACTION 扩散误差收缩的盲人脸恢复(From:ICLR2023)
- 研究动机
现有的基于深度学习的盲人脸修复方法存在两个局限性:
- 常规方法是从大量预先收集的图像对中学习一个LQ到HQ的映射,在大多数情况下,这些图像对是通过假设一个经常偏离真实模型的退化模型来合成的。当面对训练数据中没有的复杂退化时,性能急剧下降。
- 设计了各种约束来提高恢复质量,如此多的约束使得训练变得不必要的复杂,往往需要大量的超参数调优来在这些约束之间进行权衡。生成对抗模型的不稳定性使得训练更具挑战性。
- 本文贡献
- 设计了一种新的基于扩散模型的BFR方法来应对严重和未知的退化。将后验分布建模为从LQ图像开始,并以期望的HQ图像结束的马尔科夫链。马尔科夫链可将预测误差压缩。
- 我们证明,在预训练的扩散模型中捕获的图像先验可以通过部分建立在反向扩散过程上的马尔科夫链来利用。这样一个独特的设计也允许我们通过改变马尔可夫链的长度来明确控制恢复的保真度和真实感。
- 与现有方法一样,BFR可以在没有复杂损失的情况下实现。我们的方法只需要用基本的L2损失训练一个神经网络,简化了训练过程。
- 方法
我们利用了预训练扩散模型丰富的图像先验和强大的生成能力,而无需在任何人工假设的退化上重新训练它。该方法的关键是建立从观测到的低质量( LQ )图像到其高质量( HQ )图像的后验分布。
建立一个后验分布p ( x0 | y0 ),清晰图像x0,退化图像对应y0。由于退化的复杂性,在盲复原中求解这个后验很困难。解决方案:用一个转移分布p ( xN | y0 )来近似这个后验分布,其中xN是期望的清晰图像x0的扩散版本,接下来是一个从xN估计x0的反向马尔可夫链,为了构造这个转移分布p ( xN | y0 ),作者引入了一个深度神经网络,它可以简单地使用L2损失进行训练。

我们的框架通过从LQ图像y0中推断中间扩散变量xN (式中: N < T),减少了HQ图像x0的残差,从而独特地利用了这一性质,然后从这个中间状态我们推断出想要的x0。
扩散模型:

1、前向过程(X0到Xt,从右到左)通过重复应用如下马尔科夫扩散核,对图片加噪,逐渐破坏其数据结构。且每一步扩散的步长受变量β影响。
![]()
任意时间步t处的边际分布具有以下分析形式:
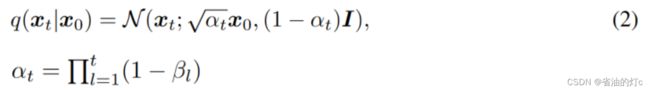
2、逆向过程,它旨在学习一个从xt到xt - 1的转换核,它被定义为如下的高斯分布:
![]()
其中θ是可学习的参数。有了这样一个学习的转换核,我们可以通过下面的边缘分布来近似数据分布q ( x0 ):
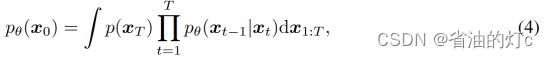
为了从退化的图像中恢复理想的HQ图像,我们需要设计一个p ( x0 | y0 )的合理后验分布:
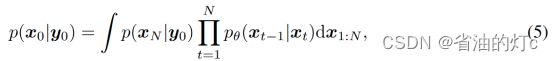
从y0还原x0:
![]()
由于转移核p θ ( xt-1 | xt )可以很容易地从预训练的扩散模型中借用,因此我们的目标转向设计p ( xN | y0 )的转移分布。
如果将p ( xN | y0 )替换为定义在方程中的边缘分布q ( xN | x0 )
![]()
我们的目标是设计一个转移分布p ( xN | y0 )来近似q ( xN | x0 ),幸运的是,目标分布q ( xN | x0 )具有解析形式,如公式所示。( 2 )
![]()
其中f ( · ; w )是一个带有参数w的神经网络,旨在为x0提供初始预测。值得注意的是,我们的方法的最终恢复结果是通过从方程的整个马尔科夫链中采样得到的。f ( · ; w )在本文中,只用于构造xN的边缘分布,x0的一个扩散版本,因此命名为"扩散估计量"。
接下来我们考虑设计的p ( xN | y0 )与其目标q ( xN | x0 )之间的库尔贝克-莱布勒( KL )散度。
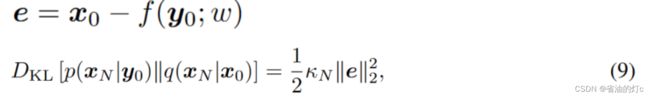
并是像当前基于深度学习的方法那样在多重约束下直接学习从y0到理想x0的映射,所提出的方法转向从y0预测x0的扩散版本xN。与当前的方法相比,这种新的学习范式带来了几个显著的优点:
1、根据公式 ( 8 )所设计的方程p ( xN | y0 ) ,我们可以得到扩散后的xN,如下所示:
![]()
f ( y0 ; w )=x0-e
可以看出,预测误差e被一个小于1的√α N的因子收缩,如图4所示。

由于这样的误差压缩,我们的方法对扩散估计量f ( · ; w )的误差容忍度更大。因此,在这项工作中,f ( · ; w )可以简单地在一些合成数据上进行L2损失训练。
2、通过式( 1 )得到扩散后的xN。( 10 )中,我们的方法从t = N开始到t = 1结束,通过递归地从p θ ( xt-1 | xt )中采样来逐步产生期望的HQ结果。通过这种采样过程,我们有效地利用了预训练扩散模型丰富的图像先验和强大的生成能力来帮助恢复任务。由于扩散模型完全以无监督的方式在HQ图像上训练,因此降低了我们的方法对人工合成的训练数据的依赖
- 模型分析
如果我们设置一个更大的N,恢复的结果看起来更逼真,但与真实的总部图像相比保真度较低。所提出的DifFace在[ 400、450]的范围内表现非常好,因此在本工作的整个实验中,我们将N设置为400。

使用更精细的架构,如SwinIR,会产生更明显的细节(例如,毛发)。结果表明DifFace在选择扩散估计量方面的通用性。在接下来的实验中,我们使用SwinIR作为f ( · ; w )的扩散估计量。
即使是最简单的只包含几个普通卷积层的SRCNN,DifFace也能够恢复一个较好的严重退化下恢复的清晰HQ图像。
- 实验
1、合成数据

LPIPS是基于VGG的深度特征计算的学习感知相似性度量
IDS是在两幅图像之间的嵌入角度,主要反映身份保持
FID是复原图像的特征分布与真值图像之间的KL散度
2、真实数据:我们主要采用FID作为定量的衡量标准,因为无法获得基本的ground truths

3、局限性

尽管DifFace具有良好的性能,但我们方法的推理效率受到扩散模型中迭代采样过程的限制。可以观察到,DifFace比大多数方法更慢,而且它的模型大。
- 结论
DifFace是一个只依赖于一个经过L2损失训练的恢复骨干,这极大地简化了目前大多数方法中复杂的培训目标。重要的是,我们提出了一个非常适合BFR的后验分布,它由一个转移核和一个部分借用自预训练扩散模型的马尔可夫链组成。前者起到了误差压缩器的作用,从而使我们的方法对严重退化更加鲁棒。后者有效地利用了强大的扩散模型来促进BFR。大量的实验证明了我们的方法在合成数据集和真实数据集上的有效性和鲁棒性。