小土堆深度学习笔记
- 常见的引入库的总结。
(1)torch.utils:工具类; 效用; 实用工具; 实用菜单;
from torch.utils.data import DataLoader
from torch.utils.data import Dataset
from torch.utils.tensorboard import DataLoader(2)PIL (Python Image Library;Pillow)
导包
from PIL import Image具体使用方法见收藏,一般是:Image.open(),打开图片,然后用.show()展示图片。
(3)torchvision
torchvision是pytorch的一个图形库,它服务于PyTorch深度学习框架的,主要用来构建计算机视觉模型。以下是torchvision的构成:
torchvision.datasets: 一些加载数据的函数及常用的数据集接口;
torchvision.models: 包含常用的模型结构(含预训练模型),例如AlexNet、VGG、ResNet等;
torchvision.transforms: 常用的图片变换,例如裁剪、旋转等;
torchvision.utils: 其他的一些有用的方法。
(4)torch.nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential神经网络torch.nn里面有很多的层可以引入调用,具体实现有哪些模块可以查询pytorch里Docs左边的torch.nn。不同的层对应不同的各种方法。
2.不用Dataloader引入数据集
代码思路:分别定义数据的根目录,猫图片所在文件名,狗图片所在的文件名,猫图片名,狗图片名。使用os.path.join函数连接到一起。并使用open(“这里写路径”)函数打开。
这个listdir("文件夹路径")应该是把该路径下的图片文件生成一个列表。便于调用。
from torch.utils.data import Dataset
from PIL import Image
import os
root_dir = "C:\\Users\\Knife\\PycharmProjects\\pythonProject\\venv\\archive\\training_set\\training_set"
cats_label_dir = "cats" # 文件夹名字
dogs_label_dir = "dogs"
class MyData(Dataset):
def __init__(self, root_dir, label_dir):
self.root_dir = root_dir
self.label_dir = label_dir
self.path = os.path.join(self.root_dir, self.label_dir)
self.img_path = os.listdir(self.path)
def __getitem__(self, idx):
img_name = self.img_path[idx]
img_item_path = os.path.join(self.root_dir, self.label_dir, img_name)
img = Image.open(img_item_path)
label = self.label_dir
return img, label
def __len__(self):
return len(self.img_path)
cats_dataset = MyData(root_dir, cats_label_dir)
dogs_dataset = MyData(root_dir, dogs_label_dir)
train_dataset = cats_dataset + dogs_dataset
print(train_dataset)此时的目录如下:
3.transfrom的使用
from PIL import Image
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("logs")
img = Image.open("C:\\Users\\Knife\\PycharmProjects\\pythonProject\\venv\\archive\\training_set\\training_set\\dogs\\dog.2.jpg")
print(img)
#ToTensor
trans_totensor = transforms.ToTensor() #trans_totensor声明到 transforms.ToTensor类中
img_tensor = trans_totensor (img) #trans_totensor所属的 transforms.ToTensor中,仅有__call__中的输入参数要求为图片。故做内置函数省略__call__?totensor能把灰度范围从0-255变换到0-1
writer.add_image("Tensor",img_tensor)
#Normalize 归一化 不太明白色调变换遵循的数学过程
print(img_tensor[0][0][0])
trans_norm = transforms.Normalize([0.5,0.5,0.5],[0.5,0.5,0.5]) #一组三个0.5应该是指的三个通道,执行image=(image-mean)/std 操作过程,其中mean和std分别通过(0.5,0.5,0.5)和(0.5,0.5,0.5)进行指定。原来的0-1最小值0则变成(0-0.5)/0.5=-1,而最大值1则变成(1-0.5)/0.5=1.
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("Normailize1",img_norm) #在tensorboard中显示的小狗图片色调发生了明显的变化,为什么呢,不只是进行了一次归一化吗?
#Resize
print(img.size)
trans_resize = transforms.Resize((512,312))
img_resize = trans_resize(img)
img_resize_totensor = trans_totensor(img_resize)
print(img_resize.size)
writer.add_image("resize",img_resize_totensor,0)#那个0是第0步的用法
#Compose - resize - 2
trans_resize_2 = transforms.Resize(512) #仅输入一个值的含义是 较小边变成512,另一条边等比缩放或等比扩大。
print(trans_resize_2.size)
trans_compose = transforms.Compose([trans_resize_2,trans_totensor]) #compose变换需要输入一个转换的列表trans_resize_2.变换对象则是trans_totensor
img_resize_2 = trans_compose(img)
writer.add_image("resize1",img_resize_2) #在步长1处显示。
#RandomCrop 随机裁剪
trans_random = transforms.RandomCrop((100,50))
trans_compose_2 = transforms.Compose([trans_random,trans_totensor])
for i in range(10):
img_crop = trans_compose_2(img)
writer.add_image("RandomCrop",img_crop,i)
writer.close() #ASK
4.tensorboard 使用
(1)整理利用torchvision.datasets.CIFAR10() 数据集时,利用tensorboard的模板
#引库
from torch.utils.tensorboard import SummaryWriter
from torch.utils.data import DataLoader
import torchvision
#################################################################
# 这里可以构建你的神经网络,以便在下面的tensorboard循 #
# 环里可以直接调用。 #
# #
#################################################################
#声明数据集(tensorboard要求数据为tensor数据类型)
dataset = torchvision.datasets.CIFAR10("./dataset",train=False,download=True,transform=torchvision.transforms.ToTensor())
#数据集读取
dataloader = DataLoader(dataset,batch_size=64)
#声明一个文件夹存放tensorboard日志
writer = SummaryWriter("logs")
step = 0 #初始化步长
#一个循环模板,用于按步长展示数据集
for data in dataloader:
imgs,targets = data #targets指的是这个图片属于什么类
writer.add_images("input",imgs,step)
#################################################################
# 这一块区域可以加一些对imgs的处理(卷积,池化,非线性激活等) #
#################################################################
# 这里在加一个writer.add_images("output",imgs,step) #
#################################################################
step += 1 #更新步长
writer.close() #停止读取在终端需要进行的操作:
tensorboard --logdir=logs --port=6007
当然不写 --port=6007 系统会自己默认6006端口。
5.神经网络(nerual network) torch.nn
(1)对于整体的框架。主要讲了Module模块,一般作为父类被继承。其次是sequential函数。具体实现如下:
from torch.utils.data import DataLoader
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset,batch_size=1)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
# self.conv1 = Conv2d(in_channels=3,out_channels=32,kernel_size=5,padding=2,stride=1)#输入是32*32图像,输出也是32*32,故需要边缘补两圈零(padding)
# self.maxpool1 = MaxPool2d(2)
# self.conv2 = Conv2d(32,32,kernel_size=5,padding=2)
# self.maxpool2 = MaxPool2d(2)
# self.conv3 = Conv2d(in_channels=32,out_channels=64,kernel_size=5,padding=2)
# self.maxpool3 = MaxPool2d(2)
# self.flatten = Flatten() #就是数据展平的功能,64通道4*4的图像共1024个像素点,所以展成1024的长条。
# self.linear1 = Linear(1024,64) #1024的长条缩到64。
# self.linear2 = Linear(64,10) #64缩到10
#用Sequential体现DRY原则
self.model1 = Sequential(
Conv2d(3,32,5,padding=2),
MaxPool2d(2),
Conv2d(32,32,5,padding=2),
MaxPool2d(2),
Conv2d(32,64,5,padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024,64),
Linear(64,10)
)
def forward(self,x):
x = self.model1(x)
# x = self.conv1(x)
# x = self.maxpool1(x)
# x = self.conv2(x)
# x = self.maxpool2(x)
# x = self.conv3(x)
# x = self.maxpool3(x)
# x = self.flatten(x)
# x = self.linear1(x)
# x = self.linear2(x)
return x
loss = nn.CrossEntropyLoss()
tudui = Tudui()
for data in dataloader:
imgs,targets = data
outputs = tudui(imgs)
result_loss = loss(outputs,targets)
result_loss.backward()
print(result_loss)sequential函数体现DRY原则,否则__init__里写一遍声明,forward里又要写一边调用。
(2)神经网络里的各种层
卷积层:
基本上会用Conv2d这个函数
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None)
torch.nn.Conv2d(入通道数,出通道数,卷积核大小,步长,在外面补几圈,卷积核中的块要不要散开,分组卷积,偏置,补0还是补什么,不知道,数据类型?)
池化层,数据展平等就自己去查pytorch官网。多读读手册 没啥问题的。
6.现有网络模型的使用和修改
import torchvision
from torch import nn
vgg16 = torchvision.models.vgg16()
vgg16.add_module("add_linear",nn.Linear(1000,10)) # 就又在最后加了一层线性层。
vgg16.classifier.add_module("add_linear_in_classifier",nn.Linear(1000,10)) #在分类的这一个大块里加入一个新的层
# dataset = torchvision.datasets.CIFAR10("./CIFAR10",train=False,transform=torchvision.transforms.ToTensor(),download=True)
print(vgg16)运行的打印结果:
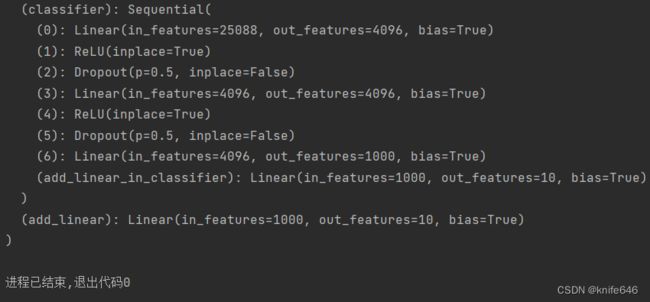
可见 在vgg16的分类这个模块里添加了两层网络。
7.网络模型的保存与修改
网络模型的保存与读取一共讲了三种
(1)普通保存
import torch
import torchvision
vgg16 = torchvision.models.vgg16()
# 保存方式1
torch.save(vgg16,"vgg16_method1.pth") #加.pth属于行业规范。运行后会在根目录下生成一个文件vgg16_method1.pth。普通读取
import torch
model = torch.load("vgg16_method1.pth")
print(model) #确实打印出了网络展示打印结果:就打印出了vgg16,没什么好看的。
(2)字典型保存
import torch
import torchvision
vgg16 = torchvision.models.vgg16()
# 保存方式2,模型参数(官方推荐)
torch.save(vgg16.state_dict(),"vgg16_method2.pth") #将网络模型的参数保存为一个字典字典型读取
import torchvison
import torch
# 方式2.加载模型
vgg16 = torchvision.models.vgg16() # 先声明一个初始化网络模型,然后再字典读取网络模型。
vgg16.load_state_dict(torch.load("vgg16_method2.pth"))
print(vgg16)就好像保存就保存了模型里的具体参数类型,读取也得先建立初始vgg16模型,再导入保存的具体网络参数。
(3)保存自己写的模型易出bug
# 陷阱.先保存一个自建模型
class Tudui (nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.con1 = nn.Conv2d(3,64,kernel_size=3)
def forward(self,x):
x = self.conv1(x)
return x
tudui = Tudui()
torch.save(tudui,"tudui_method_trap")这就保存了
读取自己写的模型要注意!
import torch
#要把定义模型的python文件引入一波,否则报错找不到Tudui这个类
from model_save import * #这里学到了一个贼强的引入,可以直接把model_python的文件都引入到这边来
model = torch.load('tudui_method_trap')
print(model)注意
from model_save import *
这句话必须要有,下面才能正常读取网络模型。
8.利用GPU训练
在对程序调用GPU运算时,只需对网络模型、数据(imgs,targets),损失函数 这三个地方进行调用GPU的命令即可。调用GPU共有两种方法。
(1)直接 .cuda() 调用
import torchvision
import torch
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from model import Tudui
#准备数据集
train_data = torchvision.datasets.CIFAR10("./CIFAR10",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10("./cifar10",train=False,transform=torchvision.transforms.ToTensor(),download=True)
train_data_size = len(train_data)
print(f"训练数据集的长度为{train_data_size}")
test_data_size = len(test_data)
print(f"测试数据集的长度为{test_data_size}")
#利用dataloader加载数据集
train_dataloder = DataLoader(train_data,batch_size=64)
test_dataloder = DataLoader(test_data,batch_size=64)
#搭建神经网络
tudui = Tudui()
————————————————————————调用GPU————————————————————
if torch.cuda.is_available(): #############一个良好的习惯,万一电脑没有GPU就不调用GPU
tudui = tudui.cuda()
———————————————————————————————————————————————————
#创建损失函数
loss_fn = nn.CrossEntropyLoss() #交叉熵
————————————————————————调用GPU————————————————————
if torch.cuda.is_available():
loss_fn = loss_fn.cuda()
———————————————————————————————————————————————————
#优化器
learning_rate = 1e-2 #就是0.01,科学计数法
optimizer = torch.optim.SGD(tudui.parameters(),lr=learning_rate) #这样写,方便修改。
#设置训练网络参数
total_train_step = 0 #记录训练次数
total_test_step = 0 #记录测试次数
epoch = 100 #训练的轮数
#tensorboard添加
writer = SummaryWriter("./logs_train")
for i in range(epoch):
print(f"--------第{i+1}轮训练开始----------")
#训练步骤开始
for data in train_dataloder:
imgs,targets = data
————————————————————————调用GPU————————————————————
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
——————————————————————————————————————————————————
outputs = tudui(imgs)
loss = loss_fn(outputs,targets) #前输出 后目标
#优化器优化模型
optimizer.zero_grad() #梯度归零初始化
loss.backward() #反向传播
optimizer.step() #梯度下降
total_train_step +=1
if total_train_step % 100 == 0: #如果训练次数是100的整数倍,才打印,避免出现一次一次的训练结果刷屏。
print(f"训练次数:{total_train_step},loss:{loss.item()}")
writer.add_scalar("train_loss",loss.item(),global_step=total_train_step)
#测试步骤开始
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloder:
imgs,targets = data
————————————————————————调用GPU————————————————————
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
——————————————————————————————————————————————————
outputs = tudui (imgs)
loss = loss_fn(outputs,targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
print(f"整体测试集上的Loss:{total_test_loss}")
print(f"整体测试集上的准确率:{accuracy/test_data_size}")
writer.add_scalar("test_loss",total_test_loss,total_test_step)
total_test_loss += 1
writer.close()
(2)先定义cuda设备,再用to调用设备,依然是对特定的三个位置进行调用。
import torchvision
import torch
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from model import Tudui
——————————————定义训练的CUDA设备——————————————
device = torch.device("cuda")
—————————————————————————————————————————
#准备数据集
train_data = torchvision.datasets.CIFAR10("./CIFAR10",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_data = torchvision.datasets.CIFAR10("./cifar10",train=False,transform=torchvision.transforms.ToTensor(),download=True)
train_data_size = len(train_data)
print(f"训练数据集的长度为{train_data_size}")
test_data_size = len(test_data)
print(f"测试数据集的长度为{test_data_size}")
#利用dataloader加载数据集
train_dataloder = DataLoader(train_data,batch_size=64)
test_dataloder = DataLoader(test_data,batch_size=64)
#搭建神经网络
tudui = Tudui()
————————————————————调用CUDA————————————————————
tudui = tudui.to(device)
————————————————————————————————————————————————
#创建损失函数
loss_fn = nn.CrossEntropyLoss() #交叉熵
————————————————————调用CUDA————————————————————
loss_fn = loss_fn.to(device)
————————————————————————————————————————————————
#优化器
learning_rate = 1e-2 #就是0.01,科学计数法
optimizer = torch.optim.SGD(tudui.parameters(),lr=learning_rate) #这样写,方便修改。
#设置训练网络参数
total_train_step = 0 #记录训练次数
total_test_step = 0 #记录测试次数
epoch = 10 #训练的轮数
#tensorboard添加
writer = SummaryWriter("./logs_train")
for i in range(epoch):
print(f"--------第{i+1}轮训练开始----------")
#训练步骤开始
for data in train_dataloder:
imgs,targets = data
————————————————————调用CUDA————————————————————
imgs = imgs.to(device)
targets = targets.to(device)
————————————————————————————————————————————————
outputs = tudui(imgs)
loss = loss_fn(outputs,targets) #前输出 后目标
#优化器优化模型
optimizer.zero_grad() #梯度归零初始化
loss.backward() #反向传播
optimizer.step() #梯度下降
total_train_step +=1
if total_train_step % 100 == 0: #如果训练次数是100的整数倍,才打印,避免出现一次一次的训练结果刷屏。
print(f"训练次数:{total_train_step},loss:{loss.item()}")
writer.add_scalar("train_loss",loss.item(),global_step=total_train_step)
#测试步骤开始
total_test_loss = 0
total_accuracy = 0
with torch.no_grad():
for data in test_dataloder:
imgs,targets = data
————————————————————调用CUDA————————————————————
imgs = imgs.to(device)
targets = targets.to(device)
————————————————————————————————————————————————
outputs = tudui (imgs)
loss = loss_fn(outputs,targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
print(f"整体测试集上的Loss:{total_test_loss}")
print(f"整体测试集上的准确率:{accuracy/test_data_size}")
writer.add_scalar("test_loss",total_test_loss,total_test_step)
total_test_loss += 1
writer.close()
torch.device("设备名称")
这里的设备名称只能填入如下:cpu, cuda, ipu, xpu, mkldnn, opengl, opencl, ideep, hip, ve, ort, mps, xla, lazy, vulkan, meta, hpu。
这里我就认识cuda和cpu。