Pytorch入门之一文看懂nn.Linear
导入方式:
torch.nn.Linear(features_in, features_out, bias=False)参数说明:
features_in其实就是输入的神经元个数,features_out就是输出神经元个数,bias默认为True,这里为了表达方便,就写了False,一般调用都是torch.nn.Linear(10, 5),就是输入10个,输出5个神经元,且考虑偏置。
该函数实现的功能:就是制造出一个全连接层的框架,即y=X*W.T + b,对给定一个具体的输入X,就会输出相应的y
下面我们来看看源码:
class Linear(Module):
...
__constants__ = ['bias']
def __init__(self, in_features, out_features, bias=True):
super(Linear, self).__init__()
self.in_features = in_features
self.out_features = out_features
self.weight = Parameter(torch.Tensor(out_features, in_features))
if bias:
self.bias = Parameter(torch.Tensor(out_features))
else:
self.register_parameter('bias', None)
self.reset_parameters()
...
note:可以看到两个重要的属性self.weight、self.bias
@weak_script_method
def forward(self, input):
return F.linear(input, self.weight, self.bias)
note:这是用来计算y=X*W.T + b的前向传播
接下来我用一个具体的例子来实现这个全连接层
import torch
x = torch.rand(10, 5) # 默认下required_grad=False
Affine_layers = torch.nn.Linear(5, 3)
Out = Affine_layers(x) # ******************
print(Out, Out.size())
print(Affine_layers.weight, Affine_layers.bias)输出结果:
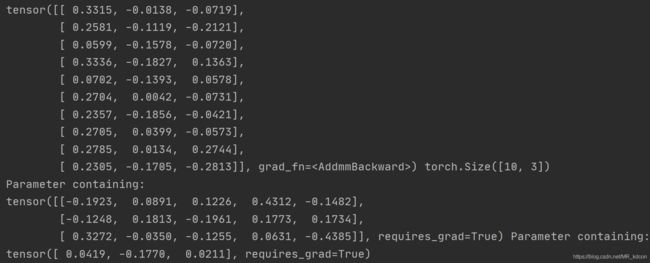
从上面可以看出,输出y是(10,3) , weight是(3,5) ,b是(1,3),且w、b的requires_grad均为True
总结:
这个函数Linear做了什么工作呢?
首先我们输入X,一般都是mini-batch形式,然后它会将配置一个转置之后可以与X进行矩阵乘法的W,当然还有偏置,形成y=X*W.T+b的Affine层(全连接层)结构。当我们对这个类实例化成对象Affine_layers并给定具体输入X的时候,该对象就会调用forward进行线性运算并输入结果。
在forward代码中,他的主要源码如下:
if input.dim() == 2 and bias is not None:
# fused op is marginally faster
ret = torch.addmm(bias, input, weight.t())
else:
output = input.matmul(weight.t())
if bias is not None:
output += bias
ret = output
return ret从matmul可以看出全连接层的输入可以是二维张量,也可以是一维张量,但不能是标量,且bias可有可无。特别要注意的是:如果输入为一维张量,那么根据matmul的特性,输出也是一维张量。
例如:
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc = nn.Sequential(
nn.Linear(1, 10),
nn.ReLU(),
nn.Linear(10, 2)
)
def forward(self, x):
out = self.fc(x)
return out
net = Net()
# x = torch.tensor(5, dtype=torch.float32) # 0维不可以
x = torch.tensor([5], dtype=torch.float32) # 1维可以
# x = torch.arange(6, dtype=torch.float32).view(6, 1) # 二维可以
y = net(x)
print(y)
注意:
1、这里可能有刚接触python的同学看不懂 上面打“******************”的地方,会认为为啥例化后实例对象进行着类似函数的操作。
其实是因为__call__(self, *args, **kwargs)这个魔法方法的存在,Linear这个类继承了nn.Module,Linear提供了自动的__call__实现,那么__call__实现代表了什呢?
这个是官方的解释:
object.__call__(self[, args...])
Called when the instance is “called” as a function; if this method is defined, x(arg1, arg2, ...) is a shorthand for x.__call__(arg1, arg2, ...).
简而言之,就是__call__实现了将例化对象当作函数使用
因此Affine_layers(x) 等价于 Affine_layers.forward(x)
理解了这个,就能明白为啥下面out1和out2的内容是相同的了
class LinearNet(nn.Module):
def __init__(self, featuresin):
super().__init__()
self.linear = nn.Linear(featuresin, 1) # 实例化对象做属性
def forward(self, input):
out = self.linear(input)
return out
x = torch.rand(10, 5)
net = LinearNet(x.size()[1]) #实例化
out1 = net(x)
out2 = net.linear(x) # out1=out2
2、
全连接层的初始化采用标准初始化(读者可以去看看源码)。也就是说pytorch对全连接层默认使用了标准初始化方式,好处是,不需要自己再去初始化,坏处就是,无法达到最优,比如我们常用Relu做激活函数,那么根据何凯明大神指出,relu函数最佳的初始化方式是He初始化,因此如果想要最优初始化参数的话,就必须要调用torch.nn.init模块中的初始化方式来重新对FC层进行初始化当然,默认的方式问题也不大,也可以一直使用的。