基于MMDetection训练VOC格式数据集
一 环境说明
基于前述安装MMDetection,数据集为VOC格式,主要版本如下:
Python:3.7.8
CUDA:11.3
cuDNN:8.4.0
torch:1.12.0
torchvision:0.13.0
mmcv-full:1.6.0
MMDetection:2.25.3二 数据集准备
使用VOC格式进行模型训练,利用labelimg对图像进行标注,生成xml文件,准备好图片和标注文件,并对数据集进行划分,文件目录如下图所示。
mmdetection
├── mmdet
├── tools
├── configs
├── dataset
│ ├── ACID # 自己给数据集取名字
│ │ ├── VOC2007
│ │ │ ├── Annotations # xml文件
│ │ │ ├── JPEGImages # 图片文件
│ │ │ ├── ImageSets
│ │ │ │ ├── Main
│ │ │ │ │ ├── test.txt
│ │ │ │ │ ├── trainval.txt
三 修改默认labels
1、在 .\mmdetection-v2.25.3\mmdet\core\evaluation\class_names.py中,修改函数
voc_classes下面的默认类别,修改为自己标注的类别。
def voc_classes():
# return [
# 'aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat',
# 'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike', 'person',
# 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor'
# ]
# SODA的数据标签,一共 15 个
# 把配电箱 ebox,写成了 electric box,一直报错,所以要先检查labels
# return [
# 'person', 'vest', 'helmet', 'board', 'wood',
# 'rebar', 'brick', 'scaffold', 'handcart', 'cutter',
# 'ebox', 'hopper', 'hook', 'fence', 'slogan'
# ]
# ACID数据集标签,一共3个
return [
'excavator', 'dump_truck', 'concrete_mixer_truck'
]2、在 .\mmdetection-v2.25.3\mmdet\datasets\voc.py中,修改默认的VOC CLASSES为自己标注的类别,如下图所示。
class VOCDataset(XMLDataset):
# CLASSES = ('aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car',
# 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse',
# 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train',
# 'tvmonitor')
# 修改为 SODA的类别
# CLASSES = ('person', 'vest', 'helmet', 'board', 'wood',
# 'rebar', 'brick', 'scaffold', 'handcart', 'cutter',
# 'ebox', 'hopper', 'hook', 'fence', 'slogan')
# ACID的类别,3个 'excavator', 'dump_truck', 'concrete_mixer_truck'
CLASSES = ('excavator', 'dump_truck', 'concrete_mixer_truck')四 选择模型
在 .\mmdetection-v2.25.3\configs文件夹下,有很多模型,到底选择哪一个,到底那个支持VOC格式进行直接训练呢?
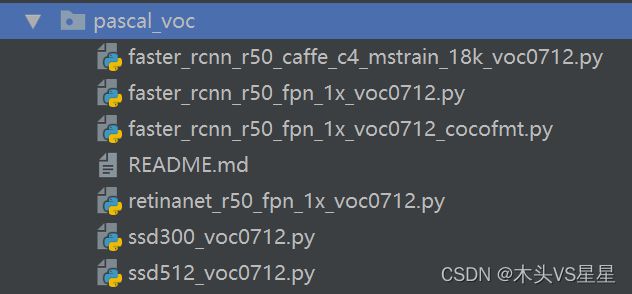
目前,支持VOC直接训练的模型在 .\mmdetection-v2.25.3\configs\pascal_voc文件夹下,模型的数量不多,主要模型如下图所示。
默认都是COCO格式的,COCO格式的模型也是可以手动改为VOC格式的,那个后面再说。
【 刚开始以为随便一个模型都可以用来训练数据,结果报莫名其妙的错误 】
五 生成模型全部配置文件
当选择好模型后,需要对进行模型的参数进行配置,一种比较好的方法是生成单独的全部的配置文件,具体操作方法如下:
python tools/train.py configs/pascal_voc/faster_rcnn_r50_fpn_1x_voc0712.py --work-dir VOC_SSD300生成的配置文件在定义的工作目录下,下一步对配置文件进行配置即可。
六 配置文件修改
重点修改标注的类别数,数据的路径,结果保存路径,大部分都不需要修改了。
num_classes=3 # 类别数
dataset_type = 'VOCDataset'
data_root = 'dataset/A/'
ann_file='dataset/A/VOC2007/ImageSets/Main/test.txt'
img_prefix='dataset/A/VOC2007/',
work_dir = 'VOC_SSD300' # 工作目录
load_from = None # 预训练模型七 预训练模型下载
训练时通常加载预训练模型,一种方法是直接取model zoo下载,另一种是使用命令直接下载,指定配置文件名称和下载路径即可。
mim download mmdet --config yolov3_mobilenetv2_mstrain-416_300e_coco --dest checkpoints八 训练模型
模型训练的脚本就比较简单了,指定你配置文件的路径和结果保存路径即可,如下:
python tools/train.py my_config\ssd300_voc0712.py --work-dir VOC_SSD300LAST 可能会遇到的问题
1、class_names.py和voc.py中的类别都改了,但训练的时候还是报错:
AssertionError: The `num_classes` (15) in SSDHead of MMDataParallel does not matches the length of `CLASSES` 20) in RepeatDatasetn
你定义的类别数和默认的VOC的20个类别不一致,但是你已经改了文件,就是不起作业,解决方法见下图,将修改好的2个文件替换到安装包里的。

2、待补充