人工智能之神经网络基础入门(最通俗版)
天天听人工智能,但你真的知道人工智能是什么吗?

大家眼里的人工智能
其实现阶段人工智能,狭义上指的是深度学习,而深度学习所包含的结构主要是神经网络。
所以今天就来做一个最通俗版的神经网络小白入门介绍,只用到初中或者高中的简单数学,小白也可以放心食用。本系列也会持续更新,欢迎点赞收藏加关注,持续关注后续文章。
理工科的思维方式
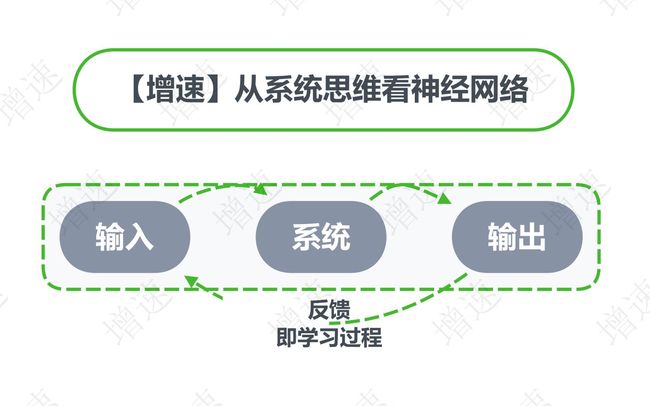
理工科一个思维的一个核心之一,我至少认为是就是“系统思维”,也就是输入输出思维。
其实不管是人工智能的学习过程,商业的模式,还是更广泛意义上的解决问题的方式,其实都是要明确输入和输出是什么,去从一个整体系统的角度去思考,这就是“系统思维”。我认为这个思维是贯穿在工科的学习以及后续工程实践过程中的。
接下来就带大家从输入、系统、输出的视角来看待神经网络。
神经网络是什么
神经网络通过模仿大脑神经元的感知系统,以一种机器感知、标记或聚类原始输入数据的方式来解释感官数据。他们识别的模式是数字化的,所有现实世界的数据,无论是图像、声音、文本还是时间序列,都必须转换成向量,再输入到神经网络之中。神经网络可以进行聚类和分类等人工智能相关多种任务。
神经网络的构成
神经网络的输入
说回神经网络,你的输入就是你的数据,所以首先要清楚你有什么的样的数据。
例如,如果你有分类问题,则需要标记数据。你需要的数据集是公开可用的,还是需要收集的,能否获得高质量的数据获得良好深度学习模型的重中之重。
但是你不能相信任何人会告诉你数据是否足够好,只有直接探索数据才能回答这个问题。
另外,要清楚你的数据输入格式,以及维度。
什么是数据维度呢?
这里需要普及一下线性代数的概念。莫慌,很好理解。
线性代数中有一个概念,是矩阵,可以把它想象成一个方阵,如m列n行的方阵,方阵中每一个点站着一个人。
只要把每个人,想象成一个数字,那这个m*n的方阵就是一个二维矩阵,如果是m*n*k的矩阵,就是三维,以此类推。
输入到神经网络中的数据,呈现形式都是一个“矩阵”,无论是音频序列、图像、视频(视频就是很多帧的图像)、文本,都是通过不同的处理方式,变成一堆数字的排列。
为什么说人工智能在不断发展呢,因为你比如一些特别笨拙的算法,他可能比如说每一个图片的像素点和他所有的像素点都要比较一遍,比如说这是最笨拙的方式,那新型的算法,它就会各种各样的改进思路,比如就是有一个注意力机制就挺有意思,就像人的注意力的这个机制一样,就是只关注图像其中的一个部分。然后这个怎么用数学来表达怎么去计算,就是他就是这个需要研究的。
另一个例子就是MP3的发展历程。在CD时代,对这个振幅频率进行采样,一秒钟要采样很多次,因此一个音乐用CD的形式可能将近几百兆,非常庞大的数字了。那MP3为什么能大大的压缩音频信息,但是你还听不出来有什么区别,因为他利用人耳的不敏感性,比如这一帧的音频,有很多东西是不动的,他就不显示了,只是把人儿最敏感的位置进行加工,其他的就掠过。因此它能大幅地压缩大小,同时保持音乐品质的不变,才让音乐能够大量普及。
神经网络的输出
神经网络有了输入,我们再来看输出。
这个就和你的目的有很大关系,例如,分类问题,识别花的种类、识别一张图片是猫还是狗,在分类问题中,判断一封电子邮件是不是垃圾邮件,其他类型的问题包括异常检测(在欺诈检测和制造设备的预测性维护中很有用)和聚类,这在一些应用的推荐系统中很有用。
神经网络的结构
接下来就来详细说一下神经网络的结构。
神经网络,自如其名,就是从大脑神经元的组织结构启发而来的。

对于神经网络,就是一层层的隐藏网络的叠加,只是不同网络的叠加方式各有差异。

人工智能是他这个输入其实就是一个一些数据的维度的组成,然后你输入到这个网络其实就是一个网络结构,这个网络结构的作用,可以理解为就是要提取它的特征。
特征也很好理解,就比如说你在识别一个人脸的时候,人怎么识别?他也是首先看这是不是耳朵鼻子,嘴巴,下巴,那就是特征,但是有些特征呢是人可以看到的,但是有些特征它是隐性的,或者比如说一些线条的特征啊,它不能直接就是说表达出来,那人工智能的深度学习为什么那么火,就是因为它是能够自动地去通过训练,有一个反馈,能学习到更有表征力而且更深度的特征。
机器学习是人工智能的一种传统的学习方法,因为他其实是它的特征就是人工来提取的,它的特征比如说是我认出了一些有用的特征,然后输入进去,然后最后学习,但是人提取的这个特征不一定一定是准的。
深度学习的越来越复杂的网络,它最重要的作用就是来提取特征,不管是音频视频还是还是文字什么的。
神经网络是通过权重的调节,来进行学习的。
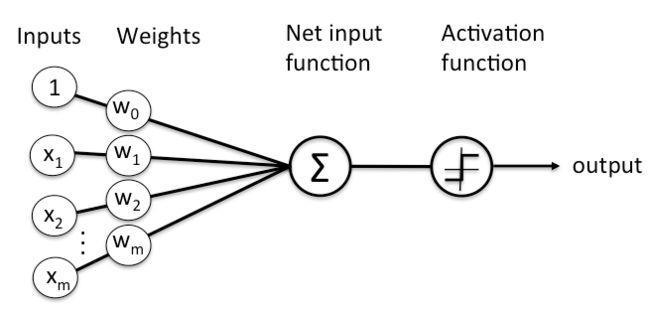
这张图说的就很清晰明了,最左侧是输入层,每一个输入都和下一层的神经元之间具有一定的“权重”,在每一层的权重之后,还有一个偏置项b,就类似于线性函数(一条直线)y=kx+b中控制直线上下的一个值,也是一个神经网络中的参数
权重,其实就是一个数字,数字越大,表示这个连接越重要。神经网络就是由一个个权重和偏置项组成的,每一个数字都称为一个参数。
现在的神经网络有巨大的参数量,比如OpenAI发布的GPT-3,是一个大规模预训练模型,达到了惊人的1750亿个参数!

梯度下降(进阶)
神经网络的模型搭建好了,那么最重要的其实是神经网络如何通过这样的结构进行学习?
这一部分涉及到高等数学的部分知识,之后如果想看的人多,也会单独出一篇详细讲解。
一种常用的优化函数,也就是它们学习的方式,是根据机器预测值与实际值之间的误差而调整权重的方式,我们称为“梯度下降”。
梯度是斜率的另一个词,斜率在 xy 图坐标上的典型形式中表示两个变量如何相互关联。 在这种特殊情况下,我们关心的斜率描述了网络的误差和单个权重之间的关系;即,随着权重的调整,误差如何变化。
更详细地说,哪个权重产生的误差最小?哪一个正确地表示了输入数据中包含的信号,并将它们转换为正确的分类?哪个参数能看到输入图像中的“鼻子”,并且知道应该将其标记为脸而不是一只猫?
随着神经网络的学习,它会慢慢调整许多权重,以便它们可以正确地将信号映射到含义。网络误差与这些权重中的每一个之间的关系是一个导数dE/dw,它衡量权重的轻微变化导致误差轻微变化的程度。
每个权重只是涉及许多变换的深度网络中的一个因素;权重的信号通过多个层的激活和求和,因此我们使用微积分的链式法则来进行网络激活和输出,最终得出有问题的权重,以及它与总体误差的关系。
人工智能的尽头是数学
人工智能学到最后就是数学,你研究深了,就是在研究数学,包括其中的优化理论、神经网络的设计、特征提取过程、输入输出过程,都是需要许多前置专业知识作为铺垫的。
而对于人工智能的应用,其实只要了解基本网络训练的原理、熟悉网络的结构,有高等数学、线性代数的先修基础(部分即可),编程的基础,接下来就是熟能生巧了。
有任何问题欢迎留言,本系列也会持续更新,欢迎点赞关注。