论文笔记(十六):Learning to Walk in Minutes Using Massively Parallel Deep Reinforcement Learning
Learning to Walk in Minutes Using Massively Parallel Deep Reinforcement Learning
- 文章概括
- 摘要
- 1 介绍
- 2 大规模并行强化学习
-
- 2.1 仿真吞吐量
- 2.2 DRL算法
-
- 2.2.1 超参数的修改
- 2.2.2 重置处理
- 3 任务描述
-
- 3.1 以游戏为灵感的课程
- 3.2 观察、行动和奖励
- 3.3 模拟到现实的补充
- 4. 结果
-
- 4.1 大规模并行化的影响
- 4.2 Simulation
- 4.3 模拟到真实的转移
- 5. 结论
- A 附件
-
- A.1 仿真吞吐量分析
-
- A.1.1 时间步长
- A.1.2 联系处理
- A.2 超时引导的影响
- A.3 奖励条款
- A.4 PPO超参数
- A.5 观察中的噪音水平
Parallel Deep Reinforcement Learning)
文章概括
作者:Nikita Rudin,David Hoeller,Philipp Reist and Marco Hutter
来源:5th Annual Conference on Robot Learning,CoRL2021
原文:https://openreview.net/forum?id=wK2fDDJ5VcF
代码、数据和视频:
系列文章目录:
上一篇:
论文笔记(十五):Deep Convolutional Likelihood Particle Filter for Visual Tracking
下一篇:
摘要
在这项工作中,我们提出并研究了一种训练设置,通过在单个工作站的GPU上使用大规模并行性,实现了现实世界机器人任务的快速策略生成。我们分析和讨论了大规模并行系统中不同训练算法组件对最终策略性能和训练时间的影响。此外,我们提出了一个新的游戏启发的课程,它很适合与成千上万的模拟机器人并行训练。我们通过训练四足机器人ANYmal在具有挑战性的地形上行走来评估这种方法。并行方法允许在四分钟内对平坦的地形进行训练,而对不平坦的地形进行训练则需要20分钟。与以前的工作相比,这代表了多个数量级的速度提升。最后,我们将这些策略转移到真实的机器人上,以验证该方法。我们开源了我们的训练代码,以帮助加速在学习腿部运动领域的进一步研究:https://leggedrobotics.github.io/legged_gym/。
关键词: 强化学习,腿机器人,模拟现实

1 介绍
深度强化学习(DRL)被证明是机器人技术的一个强大工具。诸如腿部运动[1]、操纵[2]和导航[3]等任务,已经用这些新工具解决了,而且研究还在继续,不断增加更多的挑战性任务。训练一个策略所需的数据量随着任务的复杂性而增加。出于这个原因,大多数工作都集中在模拟训练上,然后再转移到真实的机器人上。我们已经达到了这样的程度:用目前的模拟器完全训练一个代理需要多天甚至几周的时间。例如,OpenAI的块状重定向任务的训练时间长达14天,他们的魔方解题策略需要几个月的训练[4]。深度强化学习需要超参数调整以获得合适的解决方案,这需要依次重新运行耗时的训练,这使得问题更加严重。因此,使用这里提出的大规模并行方法减少训练时间有助于提高DRL策略的质量和部署时间,因为训练设置可以在相同的时间范围内更频繁地迭代进行。
在本文中,我们研究了大规模并行对政策性DRL算法的影响,并提出了对标准RL表述和最常用的超参数应如何调整以在高度并行的制度下有效学习的考虑。此外,我们还提出了一种新的游戏启发课程,它能自动将任务难度与策略的性能相适应。所提出的课程体系结构是直接实现的,不需要调整,并且很适合于大规模并行制度。常见的机器人模拟器,如Mujoco[5]、Bullet[6]或Raisim[7],具有高效的多体动力学实现。然而,它们被开发成只在具有较少并行性的CPU上运行。在这项工作中,我们使用了NVIDIA的Isaac Gym仿真环境[8],它在GPU上运行仿真和训练,能够并行模拟数千个机器人。
大规模并行训练机制之前已经在分布式系统的背景下进行过探索[4, 9],该系统由成千上万个CPU组成的网络,每个CPU运行一个单独的模拟实例。并行化是通过在不减少每个代理提供的样本数量的情况下,对不同工作者之间的梯度进行平均来实现的。这导致了每次策略更新的大批量数百万样本,改善了学习的动态性,但没有优化整个训练时间。同时,最近的工作旨在提高模拟吞吐量,减少标准DRL基准任务的训练时间。有人提出了一个将并行仿真与多GPU训练相结合的框架[10],以实现使用数百个并行代理的快速训练。在视觉导航方面,大批量模拟被用来提高训练吞吐量[11]。此外,GPU加速的物理模拟已被证明可以显著提高人形机器人运行任务的训练时间[12]。一个运行在谷歌TPU上的可微分模拟器也被证明可以大大加速多个任务的训练[13]。我们在[10, 12]的基础上,进一步推动并行化,优化训练算法,并将该方法应用于一个具有挑战性的现实世界的机器人任务。
腿部机器人在非结构化环境中的感知和动态运动是一项要求很高的任务,直到最近,才用复杂的基于模型的方法进行了部分论证[14, 15]。基于学习的方法正在成为一种有希望的替代方法。对于四足动物来说,DRL已经被用来训练对高度不平坦地面的盲目政策[16](12小时的训练)。通过将学习与优化控制技术相结合,实现了在挑战性地形上的感知运动[17, 18](82和88小时的训练),最近,一种完全学习的方法在这种环境下显示出了极大的鲁棒性[19](120小时的训练)。同样地,双足机器人也被训练成在楼梯上盲目行走[20](训练时间未报告)。通过我们的方法,我们可以在20分钟之内在单个GPU上训练一个感知策略,模拟到现实的复杂性转移到硬件上,这增加了对性能和鲁棒性的要求,并对整个方法提供了明确的验证。在几分钟内训练这样的行为开启了新的令人兴奋的可能性,从自动调整到使用特定环境的扫描进行定制训练。
2 大规模并行强化学习
目前的(政策上的)强化学习算法分为两部分:数据收集和政策更新。政策更新,相当于神经网络的反向传播,很容易在GPU上并行执行。数据收集的并行化就不那么简单了。每个步骤都包括策略推理、模拟、奖励和观察计算。目前流行的管道在CPU上计算模拟和奖励/观察,由于通信瓶颈,GPU不适合进行策略推断。众所周知,PCIe上的数据传输是GPU加速的最薄弱环节,其速度可能比单独的GPU处理时间慢50倍之多[21]。此外,在CPU数据收集的情况下,每次策略更新都必须向GPU发送大量的数据,从而减慢了整个过程。通过使用多个CPU核心并催生许多进程,每个进程为一个代理运行模拟,可以实现有限的并行化。然而,代理的数量很快就会受到内核数量和其他问题的限制,如内存使用。我们通过Isaac Gym的端到端数据收集和政策更新在GPU上探索大规模并行化的潜力,大大减少了数据复制,提高了仿真的吞吐量。
2.1 仿真吞吐量
影响总仿真吞吐量的主要因素是并行仿真的机器人数量。现代GPU可以处理数以万计的并行指令。同样,IsaacGym的PhysX引擎可以在一次模拟中处理数以千计的机器人,而且我们管道的所有其他计算都是矢量的,可以随着机器人数量的增加而有利地扩展。使用单个模拟处理成千上万的机器人会带来一些新的挑战。例如,必须使用单一的通用地形网,而且在每次重置时不能轻易改变。我们通过创建所有地形类型和水平并排的整个网格来规避这个问题。我们通过在网格上的物理移动来改变机器人的地形水平。在补充材料中,我们展示了管道不同部分的计算时间,研究了这些时间是如何随着机器人数量的增加而增加的,并提供了其他技术来优化模拟的吞吐量。
2.2 DRL算法
我们建立在近似策略优化(PPO)算法的定制实现之上[22]。我们的实现被设计为在GPU上执行每一个操作并存储所有的数据。为了有效地从成千上万的机器人中并行学习,我们对算法进行了一些必要的修改,并改变了一些常用的超参数值。
2.2.1 超参数的修改
在诸如PPO这样的政策性算法中,一个固定的政策在进行下一次政策更新之前会收集一定数量的数据。这个批量大小, B B B,是成功学习的一个关键超参数。如果数据太少,梯度将过于嘈杂,算法将无法有效学习。数据太多,样本会变得重复,算法无法从中提取更多信息。这些样本代表了浪费的模拟时间,并减缓了整个训练的速度。我们有 B = n r o b o t s n s t e p s B = n_{robots}n_{steps} B=nrobotsnsteps,其中 n s t e p s n_{steps} nsteps是每个机器人每次策略更新的步骤数, n r o b o t s n_{robots} nrobots是平行模拟的机器人数量。由于我们将 n r o b o t s n_{robots} nrobots增加了几个数量级,我们必须选择一个小的 n s t e p s n_{steps} nsteps来保持 B B B的合理性,从而优化训练时间,这是一个尚未被广泛探索的政策性强化学习算法的设置。事实证明,我们不能把 n s t e p s n_{steps} nsteps选择得任意低。该算法需要有连贯的时间信息的轨迹来有效地学习。即使在理论上,可以使用单步的信息,但我们发现该算法无法收敛到低于某个阈值的最优解。这可以解释为我们使用了广义优势估计(GAE)[23],它需要多个时间步骤的奖励才能有效。对于我们的任务,我们发现,当我们提供少于25个连续步骤,相当于0.5秒的模拟时间时,算法就会陷入困境。重要的是要将 n s t e p s n_{steps} nsteps与导致超时和重置的最大情节长度区分开来,我们将其定义为20秒。环境在达到这个最大长度时被重置,而不是在每次迭代之后,这意味着一个情节可以涵盖许多政策更新。这限制了并行训练的机器人总数,因此,禁止我们使用GPU的全部计算能力。
迷你批次的大小代表了批次大小被分割以执行反向传播的块的大小。我们发现,拥有比通常认为的最佳做法大得多的迷你批尺寸对我们的大规模并行使用案例是有益的。我们使用数以万计的样本的迷你批,并观察到它稳定了学习过程而不增加总的训练时间。
2.2.2 重置处理
在训练过程中,每当机器人跌倒时必须重新设置,而且在一段时间后也要让它们继续探索新的轨迹和地形。PPO算法包括一个预测未来折现奖励的无限地平线总和的批评者。重置打破了这个无限水平线的假设,如果不小心处理的话,会导致批评家的性能降低。基于失败或达到目标的重置不是一个问题,因为批评家可以预测它们。然而,基于超时的重置是无法预测的(我们在观察中没有提供插曲时间)。解决方案是区分这两种终止模式,并在超时情况下用预期的未来奖励的无限总和来增加奖励。换句话说,我们用自己的预测来引导批评者的目标。这个解决方案已经在[24]中讨论过了,但有趣的是,这个区别并不是广泛使用的Gym环境接口[25]的一部分,而且被流行的实现,如Stable-Baselines[26]1所忽略了。在调查了多种实现方式后,我们得出结论,这个重要的细节往往被假设为环境永远不会超时,或者只在批量收集的最后一步超时,从而避免了这个细节。在我们的案例中,每批机器人的步骤很少,我们不能做这样的假设,因为一个有意义的情节长度涵盖了许多批的收集。我们修改了标准的Gym接口来检测超时,并实现了引导方案。在补充材料中,我们展示了这个解决方案对总奖励和批评者损失的影响。

3 任务描述
一个四足机器人必须学会在具有挑战性的地形上行走,包括不平坦的表面、斜坡、楼梯和障碍物,同时遵循基点方向和线性速度指令。我们在ANYbotics ANYmal C机器人上进行了大部分的模拟和真实世界的部署实验。然而,在模拟中,我们通过对ANYmal B、带有连接臂的ANYmal C和Unitree A1机器人进行额外的训练策略来证明该方法的广泛适用性。
3.1 以游戏为灵感的课程
这些地形被选为真实世界环境的代表。我们创建了五种程序化生成的地形,如图2所示:平坦、倾斜、随机粗糙、离散障碍物和楼梯。这些地形是边长为8米的方块瓷砖。机器人从地形的中心开始,并被赋予随机的方向和速度指令(在一个事件的持续时间内保持不变),推动他们在地形上行走。斜坡和楼梯被组织成金字塔形,以允许在各个方向上的穿越。
以前的工作表明,使用任务难度的自动课程来学习复杂的运动策略的好处[28, 29, 16]。同样,我们发现,在逐步增加复杂性之前,首先在难度较低的地形上训练策略是非常必要的。我们采用了受[16]启发的解决方案,但用一个新的游戏启发的自动课程来取代粒子过滤器方法。所有的机器人都被分配了一个地形类型和一个代表该地形难度的级别。对于楼梯和随机的障碍物,我们将台阶高度从5厘米逐渐增加到20厘米。如果一个机器人设法走过其地形的边界,它的级别就会提高,在下一次重置时,它将在更困难的地形上开始。
然而,如果在一集结束时,它移动的距离不到目标速度所要求的一半,它的水平就会再次降低。解决了最高级别的机器人被循环到一个随机选择的级别,以增加多样性,避免灾难性的遗忘。这种方法的优点是在适合其性能的难度水平上训练机器人,不需要任何外部调整。它为每种地形类型单独调整难度,并为我们提供关于训练进展的视觉和定量反馈。当机器人达到最后的水平,并且由于回环而均匀地分布在所有的地形上时,我们可以断定它们已经完全学会了解决这个任务。
建议的课程结构很适合大规模并行制度。面对成千上万的机器人,我们可以直接使用它们目前在课程中的进度作为策略的性能分布,而不需要用生成器网络来学习它[30]。此外,我们的方法不需要调整,直接以并行的方式实现,处理成本接近零。我们消除了粒子过滤器方法所需的重新取样和重新生成新地形的计算开销。
图3显示了机器人在训练过程中的两个不同阶段的地形进展。在复杂的地形类型上,机器人需要更多的训练迭代才能达到最高水平。500次迭代后的机器人分布显示,虽然该策略能够穿越斜坡地形和下楼梯,但爬楼梯和穿越障碍需要更多的训练迭代。然而,在1000次迭代之后,机器人已经达到了所有地形类型中最具挑战性的水平,并且分布在整个地图上。我们总共训练了1500次迭代,让策略收敛到最高性能。

3.2 观察、行动和奖励
该策略接收机器人的本体感觉测量值以及机器人基地周围的地形信息。观察结果包括:基地的线性和角速度,重力矢量的测量,关节位置和速度,策略选择的先前行动,以及最后,从机器人基地周围的网格中抽取的108个地形测量。每个测量值都是从地形表面到机器人底座高度的距离。
总的奖励是九个条款的加权和,详见补充材料。主要条款鼓励机器人遵循命令的速度,同时避免沿其他轴的不想要的基本速度。为了创造一个更平滑、更自然的运动,我们还对关节扭力、关节加速度、关节目标变化和碰撞进行惩罚。与膝盖、小腿或脚与垂直表面之间的接触被认为是碰撞,而与基地的接触被认为是碰撞,并导致复位。最后,我们增加了一个额外的奖励条款,鼓励机器人采取更长的步骤,这将导致更有视觉吸引力的行为。我们为所有的地形训练一个具有相同奖励的单一策略。
这些动作被解释为所需的关节位置,并发送给电机。在那里,一个PD控制器产生电机扭矩。与其他工作[16, 20]相比,奖励函数和动作空间都没有任何与步态相关的元素。
3.3 模拟到现实的补充
为了使训练好的策略适合于从模拟到现实的转换,我们将地面的摩擦力随机化,在观察中加入噪音,并在剧情中随机推送机器人,以教他们采取更稳定的姿态。每个机器人都有一个在[0.5, 1.25]中均匀采样的摩擦系数。机器人的底座在X和Y方向上的加速度为±1米/秒。噪声量是基于在机器人上测得的真实数据,详细情况见补充材料。
ANYmal机器人使用具有相当复杂动力学特性的串联弹性执行器,这很难在仿真中建模。由于这个原因,并遵循以前的工作方法[1],我们使用一个神经网络来计算关节位置指令的扭矩。然而,我们简化了模型的输入。我们没有将过去的测量值在固定的时间步长上连接起来,并将所有的信息发送给一个标准的前馈网络,而是只将当前的测量值提供给一个LSTM网络。这种设置的一个潜在缺点是,政策没有像以前的工作那样拥有执行器的时间信息。我们试验了各种通过记忆机制为策略提供该信息的方法,但发现这并不能提高最终的性能。
4. 结果
4.1 大规模并行化的影响
在这一节中,我们研究平行机器人的数量对政策的最终性能的影响。为了将总奖励作为一个单一的代表指标,我们必须删除课程,否则一个性能更强的策略会看到其任务难度增加,从而导致总奖励的减少。因此,我们通过减少楼梯和障碍物的最大步长来简化任务,并直接对机器人进行全方位的难度训练。
我们首先设定一个基线, n r o b o t s = 20000 n_{robots}=20000 nrobots=20000, n s t e p s = 50 n_{steps}=50 nsteps=50,导致批量大小为1M的样本。使用这个非常大的批处理量可以得到最好的策略,但代价是训练时间相对较长。
然后,我们进行实验,在保持批量大小不变的情况下增加机器人的数量。结果,每个机器人每次更新策略的步骤数减少了。在这种情况下,训练时间随着机器人数量的增加而减少,但如果数量太高,策略性能就会下降。我们从128个机器人开始,对应于以前的CPU实现的并行化水平,并将这个数字增加到16384,这接近于我们用Isaac Gym在单个工作站GPU上运行的粗糙地形上所能模拟的最大机器人数量。
在图4中,我们将这些结果与基线进行了比较,这使得我们能够在政策性能和训练时间之间选择最有利的权衡。我们看到两个有趣的效果在起作用。首先,当机器人的数量太多,性能急剧下降,这可以解释为每个机器人的时间范围变得太小。正如预期的那样,随着批量大小的增加,整体奖励会更高,时间范围的影响也会转移,这意味着我们可以在看到下降之前使用更多机器人。另一方面,在某个阈值以下,我们看到使用较少的机器人,性能会缓慢下降。我们认为这是因为每个机器人有很多步骤的样本非常相似,因为它们之间的时间步长相对较小。这意味着,对于相同数量的样本,数据的多样性较少。换句话说,在机器人数量较少的情况下,我们进一步远离了样本是独立和相同分布的标准假设,这似乎对训练过程有明显的影响。在训练时间方面,我们看到在4000个机器人之前几乎是线性扩展,之后仿真吞吐量的收益就会放缓。因此,我们可以得出结论,增加机器人的数量对最终性能和训练时间都有好处,但这个数量有一个上限,超过这个上限后,政策性算法就不能有效地学习。将批量大小增加到比类似工作中通常使用的值大得多,似乎非常有益。不幸的是,它也会增加训练时间,所以这是一个必须平衡的权衡。从第三幅图中,我们可以得出结论,使用2048到4096个机器人,批量大小为 ≈ 100 k ≈100k ≈100k或 ≈ 200 k ≈200k ≈200k,为这个特定的任务提供了最佳的权衡。



4.2 Simulation
对于我们的模拟和部署实验,我们使用了一个用4096个机器人和98304个批次大小训练的策略,我们在20分钟内训练了1500个策略更新。我们首先测量我们训练的策略在模拟中的性能。为此,我们进行了稳健性和可穿越性测试。对于每一种地形类型,我们命令机器人以高速前进的方式穿越具有代表性难度的地形,并测量成功率。成功被定义为成功穿越地形,同时避免与机器人的基座发生任何接触。图5显示了不同地形的结果。对于楼梯,我们看到0.2米以下的台阶的成功率几乎为100%,这是我们训练的最难的台阶难度,接近我们机器人的运动极限。随机障碍物的要求似乎更高,成功率在稳步下降。我们必须注意,在这种情况下,最大的一步是报告高度的两倍,因为相邻的障碍物可能有正负高度。在斜坡的情况下,我们可以观察到,在25度之后,机器人就不能再攀爬了,但仍能学会以中等的成功率滑下来。
鉴于我们相对简单的奖励和行动空间,该政策可以自由地采取任何步态和行为。有趣的是,它总是收敛于小跑的步态,但在行为中经常会出现一些假象,如拖着腿或不合理的高低基数。在对奖励权重进行调整后,我们可以得到一个尊重我们所有约束条件的策略,并可以转移到物理机器人上。
为了验证该方法的通用性,我们对具有相同设置的多个机器人进行策略训练。我们使用带有固定机械臂的ANYmal C机器人,它增加了大约20%的额外重量,以及ANYmal B机器人,它具有类似的尺寸,但运动学和动力学特性有所改变。在这两种情况下,我们可以在不修改奖励或算法超参数的情况下重新训练一个策略,并获得非常相似的性能。接下来,我们使用Unitree A1机器人,它的尺寸更小,重量低四倍,腿部配置也不同。在这种情况下,我们删除了ANYdrive电机的执行器模型,减少PD增益和扭矩惩罚,并改变默认的关节配置。我们可以训练一个动态策略,即使机器人的尺寸减少,也能学会解决同样的地形。最后,我们将我们的方法应用于Agility机器人公司的双足机器人Cassie。我们发现,鼓励单脚站立的额外奖励对于实现行走的步态是必要的。有了这个额外的奖励,我们就能够在与四足机器人相同的地形上训练该机器人。图6显示了不同的机器人。
4.3 模拟到真实的转移
在物理机器人上,我们的策略是固定的。我们从机器人的传感器中计算出观察结果,将其输入到策略中,并直接将产生的动作作为目标关节位置发送给电机。我们不应用任何额外的过滤或约束满足检查。地形高度的测量是从机器人从激光雷达扫描中建立的高程地图中查询的。
不幸的是,这个高度图远非完美,这导致模拟和现实之间的稳健性下降。我们观察到这些问题主要发生在高速度下,因此将部署在硬件上的策略的最大线速度指令降低到0.6米/秒。该机器人可以上下楼梯,并以动态方式处理障碍物。我们在图7和补充视频中展示了这些实验的样本。为了克服不完善的地形图或状态估计漂移的问题,[19]的作者实施了一个师生设置,即使在恶劣的条件下也能提供出色的稳健性。作为未来工作的一部分,我们计划将这两种方法合并。

5. 结论
在这项工作中,我们证明了一个复杂的现实世界的机器人任务可以在几分钟内用一个政策性的深度强化学习算法进行训练。使用一个端到端的GPU管道,并行模拟了数千个机器人,结合我们提出的课程结构,我们表明,与以前的工作相比,训练时间可以减少多个数量级。我们讨论了对学习算法的多种修改以及有效使用大规模并行机制所需的标准超参数。利用我们的快速训练管道,我们进行了许多训练运行,简化了设置,只保留了基本组件。我们表明,这项任务可以用简单的观察和行动空间以及相对直接的奖励来解决,而不需要鼓励特定的步态或提供运动原形。
这项工作的目的不是为了获得具有最高鲁棒性的绝对最佳表现的政策。对于这个用例,许多其他技术可以被纳入到管道中。我们的目的是表明,用我们的设置可以在创纪录的时间内训练出一个策略,同时在真实的硬件上仍然可以使用。我们希望改变其他研究人员对真实世界应用所需训练时间的看法,并希望我们的工作可以作为未来研究的参考。我们期望许多其他任务能从大规模并行制度中受益。通过减少这些未来机器人任务的训练时间,我们可以大大加快这一领域的发展。
A 附件
A.1 仿真吞吐量分析
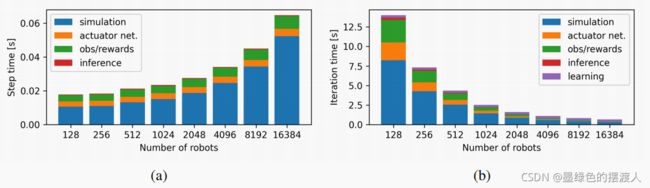
在图8中,我们显示了一个环境步骤的每个部分的计算时间,以及不同数量的机器人的学习迭代所需的总时间。在图8(a)中,我们观察到模拟是最耗时的步骤,其时间随着机器人数量的增加而慢慢增加。观察和奖励的计算时间是第二慢的步骤,也随着机器人数量的增加而慢慢增加,而策略的推理和执行器网络的计算时间几乎是恒定的。图8(b)显示了收集固定数量的样本和执行策略更新所需的总时间。增加并行机器人的数量会减少所有子部分的总时间,除了学习步骤,这与机器人的数量无关。在图9中,我们检查了训练不同数量的机器人所需的GPU VRAM,无论是否有图形渲染。我们看到,启用渲染后,运行4096个机器人需要9Gb。如果没有图形输出,6Gb就足够了。在平坦的地形上,这些数字分别减少到7Gb和5Gb。
在A.1.1和A.1.2节中,我们描述了用于优化仿真吞吐量的额外技术。
A.1.1 时间步长
仿真的时间步骤需要最大化,以获得最大的吞吐量。对于每个策略步骤,我们以50赫兹的速度运行,我们需要执行多个执行器和模拟器步骤,以获得稳定的模拟。由于这些增加的步骤直接扩大了计算量,我们的目标是尽可能地减少它们。我们发现,我们不能使用小于0.005秒的时间步长,这相当于每个策略步骤有四个仿真步骤。这个限制是由执行器网络(近似于离散时间PD控制器)变得不稳定而不是由仿真本身强加的。
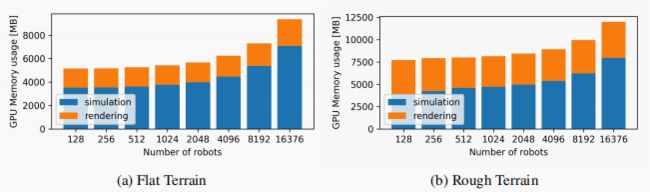
图9:在平坦和粗糙的地形上,不同数量的机器人在训练期间的GPU VRAM使用情况,批量大小为B = 98304个样本。
A.1.2 联系处理
仿真器的很大一部分计算时间都花在了接触检测和处理上。减少潜在的接触对的数量可以增加模拟的吞吐量。我们优化机器人的模型,只保留必要的碰撞体:脚、小腿、膝盖和底座。
地形的分辨率在接触优化中起着重要作用。高度场是一种非常常见的地形表示类型,其中高度被定义在一个统一的网格上。然而它的一个不幸的特性是它不可能得到垂直的表面。为了得到一个近似于垂直台阶的陡峭斜坡,我们需要高分辨率,这就降低了模拟性能。相反,我们将低分辨率的高度场转换为三角形网格,并修正垂直面。
最后,在PhysX(Isaac Gym的物理引擎)中,即使不同机器人之间的接触被忽略了,但仍然可以检测到它们。因此,机器人在地形中的位置影响了计算负荷。将机器人彼此之间的距离拉开是非常有益的。在这里介绍的课程中,我们需要在训练开始时将许多机器人放在一起,但随着训练的进行,它们很快就会分散开。此外,一旦机器人学会了避免碰撞,与底座和膝盖的接触就会减少,昂贵的重置也会减少。我们看到,在训练的最初几分钟和结束时,模拟时间相差2倍
A.2 超时引导的影响
我们分析了2.2.2节中描述的在超时时引导奖励的效果,比较了有无超时处理的总奖励和批评者损失。图10显示了平坦和粗糙地形任务的结果。我们看到,在没有引导的情况下,批评者的损失更高,相应地,总奖励也更低。即使没有这个补充,学习也能成功,但它大大降低了批评者的损失,并使两项任务的总奖励提高了大约10%至20%。

A.3 奖励条款

A.4 PPO超参数
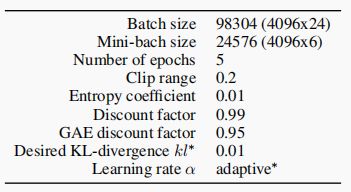

A.5 观察中的噪音水平