Catching Both Gray and Black Swans: Open-set Supervised Anomaly Detection
Catching Both Gray and Black Swans: Open-set Supervised Anomaly Detection
摘要
尽管大多数现有的异常检测研究只假设有正常的训练样本,但在许多现实世界的应用中往往有一些标记的异常例子,如随机质量检查中发现的缺陷样本,日常医疗检查中由放射科医生确认的病变图像等。这些异常例子提供了关于特定应用异常的有价值的知识,使得在最近的一些模型中对类似异常的检测有了明显的改善。然而,在训练过程中看到的那些异常往往不能说明每一种可能的异常类别,使得这些模型不能有效地归纳出未见过的异常类别。本文讨论了开放集监督的异常检测,其中我们使用异常实例学习检测模型,目的是检测已见的异常("灰天鹅")和未见的异常("黑天鹅")。我们提出了一种新的方法,学习由所见异常、伪异常和潜伏的残余异常(即在潜伏空间中与正常数据相比具有不寻常的残余的样本)所说明的异常的分解表示,最后两种异常被设计用来检测未见异常。在9个真实世界的异常检测数据集上进行的广泛实验表明,我们的模型在不同的设置下,在检测可见和不可见的异常方面有卓越的表现。代码和数据可在以下网站获得:https://github.com/choubo/DRA
1. 引言
异常检测(AD)旨在识别不符合预期模式的特殊样本[36]。它在不同领域有广泛的应用,例如,医学图像分析中的病变检测[49, 57, 71],工业检测中的微裂纹/缺陷检测[3,4],视频监控中的犯罪/事故检测[11, 21, 52, 70],以及自动驾驶中的未知物体检测[10, 56]。现有的大多数异常检测方法[2,8,11,13,33,39,39,42,44,46,47,49,58-60,69,74]是无监督的,它们假设只有正常的训练样本,即无异常的训练数据,因为很难,甚至不可能收集大规模的异常数据。然而,在许多相关的实际应用中,往往有少量(例如,一个到多个)标记的异常实例,例如在随机质量检查中发现的一些缺陷样本,日常医疗检查中由放射科医生确认的病变图像等。这些异常实例提供了关于特定应用异常的宝贵知识[30, 35, 37, 45],但无监督检测器无法利用它们。
由于缺乏关于异常的知识,无监督模型中学习的特征没有足够的鉴别力来区分异常(尤其是一些具有挑战性的异常)和正常数据,如图1中的KDAD[47],一个最近最先进的(SotA)无监督方法,在两个MVTec AD缺陷检测数据集[3]上的结果说明了这一点。近年来,有一些研究[30,35,37,45]在探索监督检测范式,旨在利用那些小的、容易获得的异常数据--罕见但先前发生的特殊案例/事件,又称灰天鹅[23]--来训练异常情况下的检测模型。这条线上目前的方法主要是使用单类度量学习来拟合这些异常例子,将异常现象作为负面样本[30,45]或单侧的以异常现象为重点的偏差损失[35,37]。尽管异常数据的数量有限,但他们在检测与训练期间看到的异常例子相似的异常现象方面取得了很大的改进。然而,这些看到的异常往往不能说明每一类可能的异常,因为
i)异常本身是未知的,
ii)看到的和未看到的异常类别可能在很大程度上彼此不同[36],例如,颜色污渍的缺陷特征与皮革缺陷检测中的褶皱和切割的缺陷特征非常不同。
因此,这些模型可以过度拟合所看到的异常现象,而不能归纳到未见/未知的异常类--罕见的和以前未知的特殊案例/事件,又称黑天鹅[55],如图1中DevNet[35, 37]的结果所示,DevNet在检测所看到的异常现象方面比KDAD有所改进,但未能将未见的异常现象与正常样本区分开。事实上,这些监督模型可能会被给定的异常例子所误导,在检测未见的异常现象方面变得不如无监督的检测器有效(见图1中DevNet与KDAD在Tile数据集上的对比)。

图1. SotA非监督模型(KDAD[47])和监督模型(DevNet[35, 37])以及我们的开放集监督模型(DRA)在两个MVTec AD数据集(Leather和Tile)的测试数据上学到的特征的t-SNE可视化。KDAD只用正常数据进行训练,学习的鉴别特征比DevNet和DRA少,而DevNet和DRA除了正常数据外,还用所看到的异常类的十个样本进行训练。DevNet容易对看到的异常情况进行过度拟合,无法将未看到的异常情况与正常数据区分开来,而DRA则有效地缓解了这个问题。
为了解决这个问题,本文讨论了开放集监督异常检测,在开放集环境中,检测模型是使用小的异常例子来训练的,也就是说,目标是检测看到的异常("灰天鹅")和未看到的异常("黑天鹅")。为此,我们提出了一种新的异常检测方法,称为DRA,它可以学习异常情况的分解表征,以实现普遍的检测。特别是,我们将无界的异常情况分解为三个大类:与有限的可见异常情况相似的异常情况、与从数据增强或外部数据源创建的伪异常情况相似的异常情况,以及在一些基于潜在残差的复合特征空间中可以检测到的未见异常情况。我们进一步设计了一个多头网络,用单独的头强制学习这三种分离的异常的每一种类型。这样一来,我们的模型就可以学习多样化的异常表征,而不是只学习已知的异常,这样就可以从正常数据中分辨出看到和未看到的异常,如图1所示。
综上所述,我们做出了以下主要贡献。
- - 为了解决开放集监督的AD,我们建议学习由所见异常、伪异常和基于潜在残余的异常所说明的异常的分解表示。这样可以学习多样化的异常表征,将寻求的异常集合扩展到可见和不可见的异常。
- - 我们提出了一个新的基于多头神经网络的模型DRA来学习分离的异常表征,每个头专门用来捕捉一种特定的异常类型。
- - 我们进一步引入了一个基于潜在残差的异常性学习模块,根据正常和异常样本的中间特征图之间的残差来学习异常性。这有助于学习鉴别性的复合特征,以检测在原始非复合特征空间中无法检测到的硬性异常(例如,未见过的异常)。
- - 我们对来自工业检测、基于漫游者的行星探测和医学图像分析的9个实际应用数据集进行了综合实验。结果表明,我们的模型在不同的环境中大大超过了五个SotA竞争模型。这些结果也为这个重要的新兴方向的未来工作建立了新的基线。
2. 相关工作
无监督的方法。大多数现有的异常检测方法,如基于自动编码器的方法[13, 19, 39, 72, 74]、基于GAN的方法[40, 46, 49, 69]、自我监督的方法[2, 11, 12, 26, 51, 57, 61]和单类分类方法[7,8,41,44],假定在训练期间只能访问正常数据。尽管它们没有偏向所见异常的风险,但由于缺乏对真实异常的了解,它们很难将异常与正常样本区分开来。
监督的方法。最近出现的一个方向是监督(或半监督)异常检测,通过利用小的异常例子来学习异常信息模型,缓解了异常信息的缺乏。这是通过将异常点作为负样本的单类度量学习[14, 30, 34, 45]或单侧异常点关注的偏差损失[35,37,71]实现。然而,这些模型在很大程度上依赖于所看到的异常情况,并可能过度拟合已知的异常情况。在[38]中引入了一种强化学习方法来缓解这种过拟合问题,但是它假设有大规模的未标记数据,并且在这些数据中存在未见过的异常现象。监督异常检测与不平衡分类[6,16,31]类似,它们都是用少数标记的例子检测罕见的类别。然而,由于异常现象的非约束性和不可知性,异常检测本质上是一个开放集任务,而不平衡分类任务通常被表述为一个封闭集问题。
学习分布内和分布外。分布外(OOD)检测[17, 18, 20, 29, 43, 68]和开放集识别[1, 30, 48, 66, 73]是与我们相关的任务。然而,他们的目标是在检测OOD/不确定样本的同时保证准确的多类内尔分类,而我们的任务只关注异常检测。此外,尽管使用像异常点暴露这样的伪异常现象[18, 20]显示了有效的性能,但这两个任务中的现有模型也被认为是无法接触到任何真正的异常样本。
3.方法

3.建议的方法
问题陈述 所研究的问题,即开放集监督的AD,可以正式陈述如下。给定一组训练样本X = {xi}N i=1 +M,其中Xn = {x1, x2, - -, xN }是正常样本集,Xa = {xN+1, xN+2, - -, xN+M }(M ≪N≫)是一个非常小的注释异常集,它提供了一些关于异常的知识。(M ≪N≫)是一个非常小的注释异常集,它提供了一些关于真实异常的知识,M个异常属于看到的异常类S⊂C,其中C = {ci}| iC=1 |表示所有可能的异常类集合,然后目标是通过学习异常评分函数g来检测看到和未看到的异常类。X → R,对已见和未见的异常现象都赋予比正常样本更大的异常得分。
3.1. 我们的方法概述
我们提出的方法DRA旨在学习各种异常情况的分解表征,以有效地检测可见和不可见的异常情况。学习到的异常表征包括由有限的给定异常例子说明的看到的异常,以及由伪异常和潜在的残余异常说明的看不到的异常(即在学习到的特征空间中与正常例子相比具有不寻常残余的样本)。这样一来,DRA减轻了对所见异常现象的偏见问题,并学习了通用的检测模型。
- 图2a提供了我们提出的框架的高层次概述,它由三个主要模块组成,包括已见、伪和潜在的残余异常学习头。
- 前两个头在普通(非复合)特征空间中学习异常表示,如图2b所示,
- 而最后一个头通过研究输入样本的残余特征与一些参考(即正常)图像在学习特征空间中的偏差,学习复合异常表示,如图2c所示。
特别是,给定一个特征提取网络f : X → M,用于从训练图像x∈X ⊂Rc′×h′×w′中提取中间特征图,以及一组异常学习头G = {gi}| iG=1 | ,其中每个头g :M→R学习一种类型的异常得分,那么DRA的总体目标可以被赋予如下。

其中Θ包含所有权重参数,yx表示x的监督信息,ℓi表示一个头的损失函数。特征网络f是由所有下游的异常学习头共同优化的,而这些头在学习具体的异常时是相互独立的。下面我们详细介绍每个头。
3.2.学习分离的异常点
用所见的异常点学习异常点。大多数现实世界中的异常图像与正常图像只有一些细微的差别,与正常图像共享大部分的共同特征。补丁式异常学习[4, 35, 60, 65]为每个小图像补丁学习异常分数,在解决这个问题上表现出令人印象深刻的性能。受此启发,DRA利用[35]中基于top-K多实例学习(MIL)的方法来有效地学习所看到的异常情况。如图2b所示,对于每个输入图像x的特征图Mx,我们生成像素向量表示D = {di}h i=1 ′×w′,每个表示对应于输入图像的一个小斑块的特征向量。然后,这些像素向量表示被映射到异常分类器gs,以学习图像斑块的异常分数。D→R。 由于只有选择性的图像斑块包含异常特征,我们利用top-K MIL的优化,根据最异常的K个图像斑块来学习一个图像的异常得分,损失函数定义如下。

其中ΨK(Mx)是一组K个向量,在Mx的所有向量中具有最大的异常得分。
异常学习与伪异常。我们进一步设计一个单独的头来学习与所见异常不同的异常,并模拟一些可能的未见异常的类别。有两种有效的方法来创建这种伪异常,包括基于数据增强的方法[26,54]和离群点暴露[18,42]。特别是,对于基于数据增强的方法,我们改编了流行的CutMix方法[67],从正常图像xn中生成伪异常图像x˜用于训练,其定义如下。

其中,R∈{0,1}h×w表示随机矩形的二进制掩码,1是全一矩阵,⊙是元素相乘,T(-)是随机平移变换,C(-)是随机颜色抖动。如图2a所示,伪异常学习使用与所见异常学习相同的架构和异常评分方法来学习细粒度的伪异常特征。

其中,如果x是伪异常,即x=x˜,则yx=1;如果x是正常样本,则yx=0;gp(Mx;Θp)与公式(3)中的gs完全相同,但gp是在一个单独的头中用与gs不同的异常数据和参数来学习伪异常的训练的。如第4.1和4.6节所述,离群点暴露法[18]被用于医学数据集的异常检测。在这种情况下,伪异常点x˜是从外部数据中随机抽取的样本,而不是从公式(4)中创建。
用潜伏的剩余异常点进行异常学习。有些异常现象,如以前未知的异常现象,与所见的异常现象没有共同的异常特征,与正常样本只有很小的差异,只用异常现象本身的特征是很难检测出来的,但只要复合特征具有较强的鉴别力,就可以在高阶复合特征空间中轻松检测出来。由于异常现象的特点是与正常数据的差异,我们利用异常现象的特征和正常特征表征之间的差异来学习这种辨别性的复合特征。更具体地说,我们提出了潜在的残差异常学习,即根据样本的特征残差与一些参考图像(正常图像)的特征相比较,在学习的特征空间中学习异常的分数。如图2c所示,为了获得潜在特征残差,我们首先使用从正常数据中随机抽取的一小部分图像作为参考数据,并计算其特征图的平均值以获得参考正常特征图。
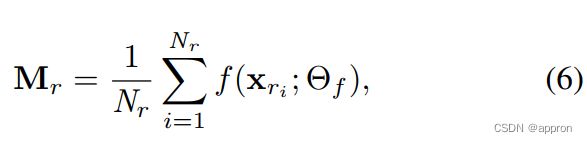
其中xri是参考正态图像,Nr是一个超参数,表示参考集的大小。对于一个给定的训练图像x,我们在其特征图Mx和对所有训练和测试样本固定的参考正态特征图Mr之间进行逐元相减,结果是x的残余特征图Mr⊖x。

其中⊖表示逐项减去。然后,我们对这些残留的特征进行异常分类。

其中yx=1,如果x是一个看到的或伪异常,yx=0,如果x是一个正常的样本,否则。同样,gr使用与公式3中gs完全相同的方法来获得异常得分,但它是在一个单独的头中使用不同的训练输入,即残余特征图Mr⊖x来训练参数Θr。
由于gs、gp和gr头侧重于学习异常表征,f中联合学习的特征图不能很好地模拟正常特征。为了解决这个问题,我们增加了一个单独的正常性学习头,如下所示。

训练和推理。在训练过程中,特征映射网络f是由所有四个头gs、gp、gr和gn共享和共同训练的。这四个头是相互独立的,因此它们的参数并不共享和独立优化。在我们所有的头中,默认使用一种叫做偏差损失[35,37]的损失函数来实现损失函数ℓ,因为它能使一般比其他损失函数如交叉熵损失或焦点损失更稳定和有效的性能(见附录C.2)。在推理过程中,给定一个测试图像,我们将所有来自异常学习头(gs、gp和gr)的分数相加,然后减去来自常态头gn的分数,得到其异常分数。
其中 gn :D→R是一个全连接的二元异常分类器,可以将正常样本从所有看到的和假的异常中区分出来。与异常特征通常是细粒度的局部特征不同,正常特征是整体性的全局特征。因此,gn不象其他头那样使用基于MIL的top-K异常评分,而是学习整体的正常评分。
实验
数据集
许多研究在合成异常检测数据集上评估他们的模型,这些数据集由流行的图像分类基准转换而来,如MNIST[25]、Fashion-MNIST[64]、CIFAR-10[24],使用一比一或一比一协议。这种转换的结果是异常点与正常样本明显不一样。然而,在现实世界的应用中,如工业缺陷检测和医学图像中的病变检测,异常和正常样本通常只有细微/微小的差别。受此启发,继[26, 35, 65]之后,我们把重点放在具有自然异常的数据集上,而不是基于一比一/一比二的合成异常。特别是,在我们的实验中使用了9个具有真实异常情况的不同数据集,包括5个工业缺陷检测数据集。MVTec AD[3]、AITEX[50]、SDD[53]、ELPV[9]和Optical[63],我们的目标是检测有缺陷的图像样本;一个行星探测数据集。Mastcam[22],我们的目标是识别火星探测车拍摄的具有地质意义的/新颖的图像;以及三个用于检测不同器官病变的医学图像数据集。BrainMRI [47], HeadCT [47] 和Hyper-Kvasir [5]。这些数据集是各自研究领域的流行基准,最近也成为异常检测的重要基准[4, 19, 35, 47, 65](关于这些数据集的详细介绍见附录A)。
4.1. 实施细节
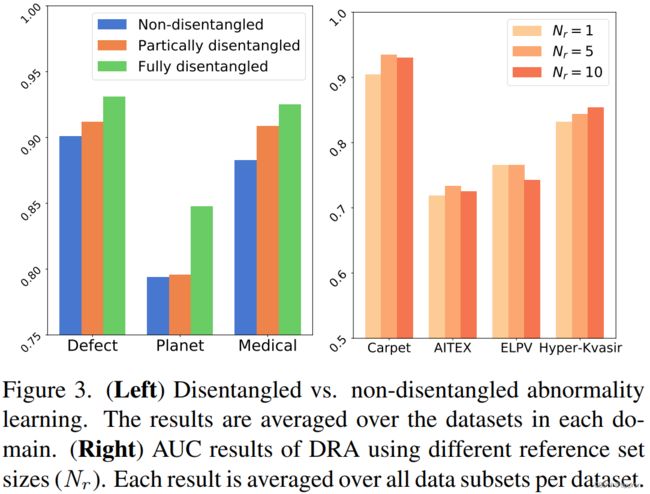
DRA使用ResNet-18作为特征学习主干。它的所有头都是用30个epochs联合训练的,每个epoch有20次迭代,批次大小为48。Adam用于参数优化,初始学习率为10-3,权重衰减为10-2。DRA中的top-K MIL与DevNet[35]中的相同,即top-K MIL中的K被设置为每个分数图中所有分数数的10%。在残留异常学习中默认使用Nr = 5(见第4.6节)。伪异常学习使用CutMix[67]在所有数据集上创建伪异常样本,除了三个医疗数据集,在这三个数据集上DRA使用另一个医疗数据集LAG[27]的外部数据作为伪异常源(见第4.6节)。我们的模型DRA与最近的五个密切相关的最先进的(SotA)方法进行了比较,包括MLEP[30]、偏差网络(DevNet)[35, 37]、SAOE(将基于数据增强的合成异常[26, 32, 54]与异常点暴露[18, 42]相结合)、无监督异常检测器KDAD[47]和焦点损失驱动分类器(FLOS)[28](与其他两个方法的比较见附录C.1 [45, 62] )。MLEP和DevNet解决的是与我们相同的开放集AD问题。KDAD是最近的一种无监督AD方法,只在正常训练数据上工作。人们普遍认为,在检测未见的异常情况时,无监督检测器比有监督检测器更可取,因为后者可能会偏向于已见异常情况。受此启发,KDAD被用作基线。DevNet和KDAD的实现来自其作者。MLEP适用于图像任务,设置与DRA相同。SAOE利用了基于数据增强和基于离群点暴露的方法的伪异常,其性能优于使用这些异常创建方法之一的个体。FLOS是一个用焦点损失训练的不平衡分类器。为了进行公平的比较,除了KDAD需要自己的特殊网络架构来进行训练和推理外,所有竞争方法都使用与DRA相同的网络主干(即ResNet-18)。附录B中提供了DRA及其竞争方法的进一步实施细节。
4.2. 实验协议 我们使用以下两个实验协议。
一般设置模拟开放集AD的一般情况,其中给定的异常例子是从每个数据集中所有可能的异常类别中随机抽取的几个样本。然后从测试数据中删除这些抽样的异常情况。这是为了复制现实世界的应用,我们无法确定哪些异常类是已知的,以及给定的异常例子跨越多少个异常类。因此,数据集可以包含已见和未见的异常类,或者只包含已见的异常类,这取决于应用的基本复杂性(例如,所有可能的异常类的数量)。
硬设置的目的是专门评估模型在检测未见过的异常类方面的性能,这是开放集AD中非常关键的挑战。为此,异常例子的抽样被限制在只从一个单一的异常类中抽取,并且这个异常类中的所有异常样本都从测试集中删除,以确保测试集只包含未见过的异常类。请注意,这种设置只适用于具有不少于两个异常类的数据集。
由于标记的异常点由于其稀有性和不可知性而难以获得,在这两种设置中,我们只使用非常有限的标记的异常点,即给定的异常点例子的数量分别固定为1个和10个。使用流行的性能指标,ROC曲线下面积(AUC)。每个模型产生一个异常排名,它的AUC是根据该排名计算的。所有报告的AUC是三次独立运行的平均结果。
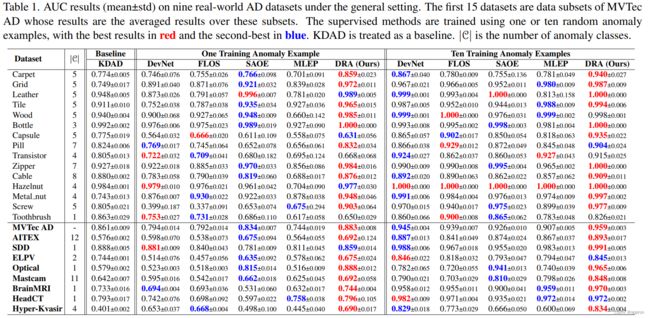
4.3. 一般设置标签下的结果。图1显示了一般设置协议下的比较结果。下面我们详细讨论这些结果。应用域的视角。尽管数据集来自不同的应用领域,包括工业缺陷检测、基于漫游器的行星探测和医学图像分析,但我们的模型在几乎所有的数据集上都取得了最佳的AUC性能,即在一次拍摄(十次拍摄)设置中,九个数据集中有八个(七个),在其他数据集上则是第二好的结果。在具有挑战性的数据集上,如MVTec AD、AITEX、Mastcam和Hyper-Kvasir,其中有更多可能的异常类别,我们的模型获得了持续更好的AUC结果,AUC最多增加了5%。样本效率。训练异常例子的减少通常会降低所有监督模型的性能。与竞争的检测器相比,我们的模型显示出更好的样本效率,即:i) 在减少异常例子的情况下,我们的模型的AUC下降得更少,即:。在9个数据集中,平均AUC下降15.1%,这比DevNet(22.3%)、FLOS(21.6%)、SAOE(19.7%)和MLEP(21.6%)要好得多;ii)我们用一个异常例子训练的模型可以在很大程度上超过用十个异常例子训练的强大竞争方法,如DevNet、FLOS和MLEP在光学上的表现,以及SAOE和MLEP在超Kvasir的表现。与无监督基线的比较。与无监督模型KDAD相比,我们的模型和其他监督模型在使用10个训练异常例子(即较少的开放集场景)时表现出持续更好的性能。在只使用一个异常例子的更开放的场景中,我们的方法是唯一一个在大多数数据集上仍然明显优于KDAD的模型,甚至在有许多异常类别的挑战性数据集上,如MVTec AD、AITEX和Mastcam。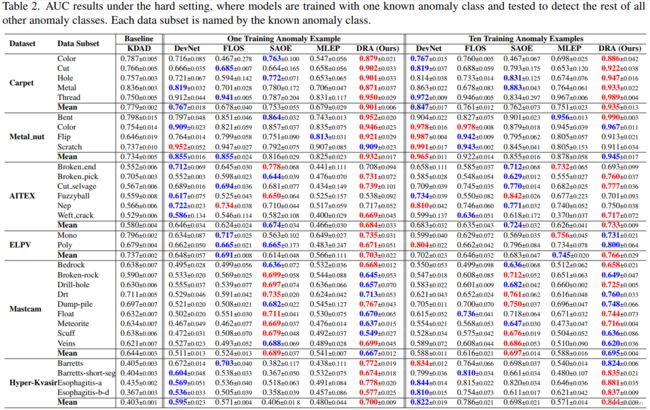
4.4. 硬环境下的结果 在硬环境下适用的六个数据集的检测性能见表。2. 应用域的角度。在不同应用数据集的单次和十次设置中,与竞争方法相比,我们的方法在大多数单个数据子集上表现最好;在数据集级别的表现上,与六个数据集中的大多数最佳竞争者相比,我们的模型实现了大约2%-10%的平均AUC增长,在其他数据集上接近最佳表现。这表明我们的模型在检测未见过的异常类方面的通用性大大优于其他有监督的检测器。样本效率。与一次拍摄的方案相比,我们的模型在数据集层面平均有5.5%的AUC下降,这比其他竞争方法要好。DevNet(9.8%)、FLOS(7.1%)、SAOE(7.8%)和MLEP(10%)。更令人印象深刻的是,在许多单独的数据子集和整体数据集上,我们用一个异常例子训练出来的模型比十次拍摄的竞争模型有很大的优势。与无监督基线的比较。目前的监督AD模型通常偏向于所看到的异常6类,而不能推广到未看到的异常类,在大多数数据集上的表现不如无监督的基线KDAD有效。相比之下,我们的模型具有明显的泛化能力,即使是在单次拍摄的情况下,也基本上胜过KDAD。我们在附录C.3中的跨领域异常检测的初步结果进一步支持了这种普适性。


5. 结论与讨论
本文提出了学习由可见异常、伪异常和基于潜在残差的异常所说明的异常的分解表示的框架,并介绍了DRA模型来有效地检测可见和不可见的异常。我们的综合结果见表。我们在表7和表2中的综合结果证明,这三种分散的异常表示可以在检测大体上不同的异常方面相互补充,以很大的幅度超过五个SotA无监督和有监督的异常检测器,特别是在具有挑战性的情况下,例如,只有一个训练异常例子,或检测未见过的异常。所研究的问题在很大程度上没有得到充分的探索,但它在许多相关的现实世界的应用中是非常重要的。正如表7和表2中的结果所示,仍有许多问题需要解决。如表7和表2所示,仍有许多重大挑战需要进一步研究,例如,从较少的类中的较小的异常例子中进行归纳,我们的模型和综合结果提供了一个良好的基线和广泛的基准结果。