蒸馏+Distilling Knowledge via Knowledge Review论文笔记
文章目录
- 一、前言
- 二、蒸馏
-
- 1.背景介绍
- 2.知识蒸馏和迁移学习之间的区别
- 3.Hinton提出的知识蒸馏
-
-
- Pipeline
-
- 4.蒸馏的知识形式
- 5.知识蒸馏的方法
- 三、Distilling Knowledge via Knowledge Review论文笔记
-
- 1.思想介绍
- 2.Pipeline
- 3.实验结果
- 参考文献
一、前言
近期在阅读cvpr 2021的一篇关于蒸馏学习的论文,正好趁此机会梳理一下蒸馏学习的相关内容,方便下次再阅读蒸馏学习论文时查阅。一下内容关于蒸馏学习的均是网上优秀文章总结,论文阅读笔记是自己总结。
网上找了一圈关于知识蒸馏的博客,发现绝大部分都是针对分类任务而言的,我觉得这样论述的话会给人一种错觉,知识蒸馏只适用于分类任务。故我准备参考综述论文《知识蒸馏研究综述》(计算机学报,黄震华,2022年3月)。
二、蒸馏
1.背景介绍
近年来深度学习由于对目标多样性变化有很好的鲁棒性,但性能越好的深度学习模型往往需要越多的资源,使其在物联网、移动互联网等低资源设备应用商店受限。因此需要一种方法保留模型的高性能同时满足低资源设备的低功耗和实时性等要求。目前常见的有5种方法可以完成该任务,如下:
- 直接手工设计轻量级网络模型
- 剪枝
- 量化
- 基于神经架构搜索的网络自动化设计
- 知识蒸馏
知识蒸馏是一种教师-学生(Teacher-Student)训 练结构,通常是已训练好的教师模型提供知识,学 生模型通过蒸馏训练来获取教师的知识. 它可以以 轻微的性能损失为代价将复杂教师模型的知识迁移到简单的学生模型中.在后续的研究中,学术界和工业界扩展了知识蒸馏的应用范畴,提出了利用知识蒸馏来实现模型性能的增强.

现阶段,常见的主要为模型压缩。且从知识蒸馏的定义来看,知识蒸馏主要聚焦与两个东西:蒸馏的知识是啥 和蒸馏的方式是啥
2.知识蒸馏和迁移学习之间的区别
虽然,知识蒸馏与迁移学习都涉及到知识的迁移,然而它们有以下4点不同:
- 数据域不同:知识蒸馏中的知识通常是在同一个目标数据集上进行迁移,而迁移学习中的知识往往在不同目标的数据集上进行转移。
- 网络结构不同:知识蒸馏的两个网络可以是同构或者异构的(结构一样或者不一样),而迁移学习通常是在单个网络上利用其它领域的数据知识。
- 学习方式不同:迁移学习使用其它领域的丰富数据的权重来帮助目标数据的学习,而知识蒸馏不会直接使用学到的权重。
- 目的不同:知识蒸馏通常是训练一个轻量级的网络来逼近复杂网络的性能,而迁移学习是将已经学习到的相关任务模型的权重来解决目标数据集的样本不足问题。
知识蒸馏更强调的是知识的迁移,而非权重的迁移。
3.Hinton提出的知识蒸馏
第1部分简单的介绍了知识蒸馏,接下来我们用具体的例子来看看知识蒸馏是咋进行的。Hinton的这篇文章算得上是知识蒸馏的开山鼻祖了。下面我们简单看看。
Pipeline

首先,要知道知识蒸馏目的是为了进行模型压缩,故训练结构和测试结构是不同的,其实不少文章的Pipeline训练和测试是不一样的。知识蒸馏只在模型训练时使用。毕竟真正投入使用的是训练好的测试部分。
其次,我们要知道啥是软目标、啥是硬目标、逻辑单元层(logits)。

简单滴说,分类任务通常最后一层为全连接层+Softmax,逻辑单元层(logits)就是全连接层的输出,logits通过Softmax便可以得到为各个类别的概率值,这些概率值和为一,概率值有大有小如上图所示,我们可以通过比较各个类别的概率值来判断属于哪一个类别。但是分类任务的标签(真实值)是知道属于哪一个类别的,不需要比较概率值的大小,故用0比较负样本、1表示正样本。Softmax函数表达式如下,其中 z i z_i zi表示逻辑单元层的值:
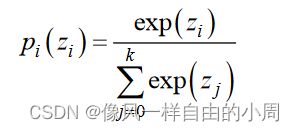
最后,我们要知道在这个Pipeline中的知识是啥,蒸馏方式是啥。在这里,我们可以选择逻辑单元、软标签作为知识(当然也可以选择别的,这是后话了)。但是,这两个使用起来都有一些小问题需要改进。
- 逻辑单元:不受约束的值在测试的时候可能会包含噪声信息,如图3所示,子网络测试时逻辑单元层中第3个类别的输出值时噪声。如果将其包含噪声信息的逻辑单元作为学生的监督信号,则会因为过拟合而限制了学生的泛化能力。(不知道咋就导致过拟合了,我觉得这个东西可能和接下来的软标签问题一样,负样本值太小,学习起来就像让学生学习硬目标知识,这样做有啥子坏处呢,举个简单的例子,如果预测出来的有一个负样本或者多个负样本的值和正样本值相近,这就会驱使模型去学习到更强的特征来区别正负样本。就像给模型样本“一”、“二”,标签为“三”,让模型去学习“三”的写法,这就较为简单了,可能学到的特征就是多一横少一横的,但如果给模型输入“四”、“五”,再让模型去生成“三”,这就驱使模型学习到更强的特征)。
- 软标签:由于负标签的概率被Softmax压扁后将会接近零而导致在网络训练时这部分信息丢失。例如,在网络训练时,类概率层(如图3中T=1事的软目标)的负标签输出的信息已经丢失。将该类概率作为学生的监督信号,相当于让学生学习硬目标知识,这就会浪费了负样本的信息,同时可能会导致过拟合。
针对,软标签这个问题,Hinton给Softmax添加了T变成了下面这个式子。
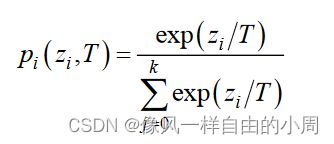
这个式子有啥奇妙用处呢,易见,当T=1时就是Softmax函数,当T越来越大便会导致输出值之间的欧式距离变短,对比一下图3中T=1和T=10之间的区别就可以看出,T越大,负样本的概率值和正样本的概率值越接近(T越大, z i z_i zi/T越小, e x p ( z i / T ) exp(z_i/T) exp(zi/T)越小,这样便缩小了差距)。当调大T的值,便可以让模型训练时给较小的逻辑单元更多的关注,从而使学生模型学习到这些负样本和正样本之间的关系信息——Dark Knowledge。好了,改进后,我们便可以用软标签来作为知识了。
注意看,学生模型和老师模型的输出都是软标签(概率值),对于同一个样本,我们的目的是使得教师模型的输出和学生模型的输出一样,那么咋一样呢。沿用我们传统的使得模型输出结果和标签一样的方法,使用约束函数,因为输出值为概率值,我们可以使用交叉熵作为约束函数。这就是蒸馏方法。

这里我们只讨论了学生模型和教师模型之间的交互,拜托还有标签(groundtruth)没有用呢,不能白白浪费这个信息,故在约束函数上又添加了学生网络和标签之间的约束函数。这里的Ls可以根据实际需要设计。

好了,相信看到这,大家心中已经知道了原始知识蒸馏的简单做法。但是,这是远远不够第!当教师网络变得更深时,仅仅学习软目标是不够滴,而且可以进行蒸馏的知识远不止软目标(如果不是分类问题,还有软目标吗,蒸馏学习就不能用了吗),知识蒸馏的方法也不止上面说的这些。反正就是革命尚未成功。好了,下面我们开始进阶。
4.蒸馏的知识形式
这个只是简单的分类,只是将现阶段常见的知识进行了分类,知识可能还不止这些。
-
输出特征知识:简单的说就是学生和教师网络的输出特征。任务的不同,输出特征形式也不一样。具体如下:

-
中间特征知识:教师和学生模型由于容量差异大导致它们存在着“代沟”。教师的中间层特征知识可以用于解决教师和学生模型在容量之间存在的“代沟”问题。主要思想是从教师中间的网络层中提取特征来充当学生模型中间层的提示(Hint),促使学生的隐含层能预测出与教师隐含层相近的输出。

蒸馏方式可以隔层、逐层和逐块地将教师的中间特征知识转移到学生模型中。不难看出,中间特征的知识蒸馏是要最小化教师与学生之间的中间特征映射距离,这一目标和度量学习的思想很相似。 -
关系特征知识:关系特征指的是教师模型不同层和不同数据样本之间的关系知识。教师模型不同层之间的关系经典例子如下。感觉就是利用一种方式把教师层的特征融合在一起用来学习特征和特征之间的关系,不像之前的中间特征知识,把层与层剥离,缺少了对于层与层之间特征关系的度量。相应的学生模型也要采用类似的做法。

基于样本间的关系特征知识蒸馏是额外利用了不同样本之间的关系知识,即把教师模型捕捉到的数据内部关系迁移到学生模型中,代表性的有“学生排名”(不晓得这是个啥东西,网上没有找到相关名词解释,等有机会找原论文看看)。 -
结构特征知识:emm,论文中说的贼模糊,也不知道这东西是个啥。个人觉得可能是上述三种知识的汇总处理。
我觉得第三部分要介绍的论文就属于关系特征知识+中间特征知识的融合。好了,废了老鼻子劲整理到了现在,下面我们看看常见的知识蒸馏方法。
5.知识蒸馏的方法
常见的知识蒸馏方法有知识合并、多教师学习、教师助理、跨模态蒸馏、互相蒸馏、终身蒸馏以及自蒸馏。
-
知识合并:
知识合并是将多个教师或多个任务的知识迁移到单个学生模型中,从而使其可以同时处理多个任务。知识合并的重点是学生应该如何将多个教师的知识用于更新单个学生模型参数,并且训练介素的学生模型能处理多个教师模型的原先任务。
目前,一种方法是将多个教师模型的特征知识进行融合。然后将所获得的融合特征作为学生模型学习参数的指导。举个例子,如下(这个例子为啥work,值得好好研究研究):

另一种方法是学生模型同时向多个教师模型学习多个任务的特征。这样就会有一个问题,并非所有的教师模型对于多任务表示学习都能产生有利的影响。为了解决这个问题,Shen等人引入了选择性学习,还可以通过共享网络层直接学习多教师特征来实现多任务知识的合并。 -
多教师学习
emm,这个多教师和知识合并多是针对多教师——单学生,那么这两个有啥子本质区别呢?知识合并是要促使学生模型能同时处理多个教师模型原先的任务,而多教师学习是提高学生模型在单个任务上的性能。多个教师去教授学生就涉及一个教授策略,毕竟学习模型容量小,之前一个老师都受不了,更别提多个老师了。常见的有投票机制,平均权重和非线性变化等。此外,多个老师之间的知识可以进行互补,例如,Jiang等人提出同时向能提供稳定信号的长期教师和高质量训练更新的短期教师学习来改善学生模型。长期的教师信号提供了稳定的教师信息,保证了师生的差异,而短期的教师信号则保证了高质量的教学。

-
教师助理
之前提到的中间特征知识可以用来弥补教师和学生模型由于容量差异大导致它们存在着“代沟”。我们可以使用教师助理网络去协助学生模型学习。教师助理先从教师模型中学习到知识后,再传递到学生模型中。举个例子如下(Wang 等人[56]使用 GAN 的判别器充当教师助理,其工作 原理如图 10 所示. 该工作将学生模型当做生成器, 判别器促使学生模型对输入数据生成和教师模型同 样的特征分布.):

-
跨模态蒸馏
在许多实际应用中,数据通常以多种模态存在, 一些不同模态的数据均是描述同一个事物或事件,我 们可以利用同步的模态信息实现跨模态蒸馏(Cross Modal Distillation). 其中有代表性的是 Albanie 等人[60] 提出的的跨模态情感识别方法,如图 11 所示. 人在 说话时脸部的情感和语音情感是一致的,利用这种 同步对齐的模态信息将无标签的视频作为输入数据 进行训练,视频中的图片进入预训练的人脸教师模 型中产生软目标来指导学生的语音模型训练.

-
相互蒸馏
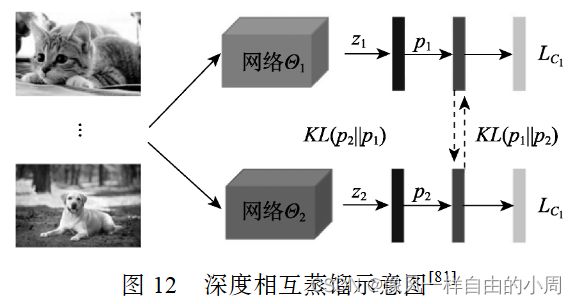
相互蒸馏是让一组未经训练的学生模型同时开始学习,并共同解决任务。举一个Zhang等人提出的深度互学习(DML)模型例子。

-
终身蒸馏
深度学习网络在学习新任务时,对旧任务的性 能就会急剧下降,这个现象被称为灾难性遗忘[85]. 这就需要使用终身学习来减轻这种影响,终身学习 也称为持续学习或增量学习.目前,有些工作使用知识蒸馏方法来实现终身 学习,称之为终身蒸馏(Lifelong Distillation). -
自蒸馏
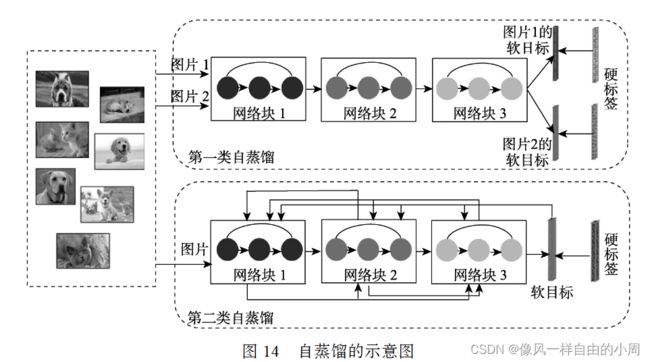
自蒸馏(Self-Distillation) 是单个网络被同时用 作教师和学生模型,让单个网络模型在自我学习的 过程中通过知识蒸馏去提升性能. 它也是一种在线 的知识蒸馏.Mobahi 等人认为自蒸馏是通过逐渐减少代表解 的基函数数量来不断修改正则化. Zhang 等人[89]认为 自蒸馏先前的迭代都能为后续的迭代充当教师作用, 从而通过多次的迭代之后能学习到多样性的知识.
自蒸馏主要分为两类,如图 14 所示. 第一类是 使用不同样本信息进行相互蒸馏. 其它样本的软标 签可以避免网络过度自信的预测,甚至能通过最小 化不同样本间的预测分布来减少类内距离. 另外 一些工作使用增强样本的信息,如利用数据在不同失真状态下的特征一致性来促进类内鲁棒性学习(如下图中的彩色图所示:选自论文Distill on the Go: Online knowledge distillation in self-supervised learning).另一类是单个网络的网络层间进行自蒸馏. 最通常的做法是使用深层网络的特征去指导浅层网络的学习,其中深层网络的特征包括了网络输出的软目标. 在序列特征的任务中,则是将先前帧中的知识传递给后续帧进行学习. 单个网络的各个网络块学习也可以是双向的,每一个块间可以进行协作学习,并在整个训练过程中互相指导学习(我觉得这个和FPN网络的级联像类似).自蒸馏:一种简单高效的优化方式这篇博客就举了几个自蒸馏例子,有需要可以阅读一下。

最后放一张图震震场。

三、Distilling Knowledge via Knowledge Review论文笔记
1.思想介绍
按照我的理解,教师模型的每一层类似于教育,层越深教师模型提取到的知识越丰富越牛,也就像咱们幼儿园、小学、高中。。。的教育。作为学生的咱们如果不是天才啥的是不能调级的,这样学习到的东西是没有依次接受幼儿园、小学、高中。。。教育好的。第二部分介绍的Hinton模型直接传授教师模型的输出层是不如每一层都给学生传授,就像中间特征知识。而这样做还是不太牛,咱们需要复习啊,还需要重温,故咱们可以把教师模型相对学生模型所在层的前面几层的知识蒸馏给学生(这就是knowledge review),这就像关系特征知识。
好了,一图胜千言,下图就是蒸馏学习架构的演变。从输出特征知识到中间特征知识到关系特征知识。下图的d就是作者提出的knowledge review——拿学生层的stage4举例,stage不止需要教师网络对应的层stage4的特征知识,也需要stage1——stage3的知识。

不对啊,这样搞能发顶会顶刊吗,必须再加点创新。关于创新点请看下文。
2.Pipeline
作者在上图中的d上又进行了深入的探讨。下图中的灰色矩阵块进行的操作目的是使得学生特征大小和教师特征大小一样,这样便于进行知识蒸馏(可以使用卷积网络啥的)。首先如果可以学生模型的最后一层进行Review(下图a),那为啥不能对学生的每一层进行Review(下图b)呢。但下图b的结构有两个个弊端:1.计算量大,2.不同层之间的特征差异较大,直接用来进行知识传递有点不靠谱,得处理一下。针对这两个弊端,作者提出了c来进行改进,也就是把原来几个层的特征先融合一下(特征融合),这里作者采用了一种Attention机制(Attention机制就是一种加权求和),也就是橙色矩阵块。但是,是不是觉得c图中的绿色的线太多了,作者采用一种Residual Learning Framework来进行替代,也就下图中的d。作者便提出HCL,利用空间金字塔池,将知识的转移分离到不同层次的上下文信息中。这样,信息在不同的抽象层次上得到了更好的提炼。结构非常简单:我们首先使用空间金字塔池从特征中提取不同层次的知识,然后使用 L2 距离分别在它们之间进行提取。尽管结构简单,但 HCL 适合我们的框架。

下图中的ABF两个输入特征先进行concentrate(合并),然后通过一个1*1网络一个新的特征分别和输入的两个特征进行相乘得到两个特征值,再把两个特征值相加就得到了输出。emm,不如直接放源码,便于理解,而且有一些细节框架图没有画出来。
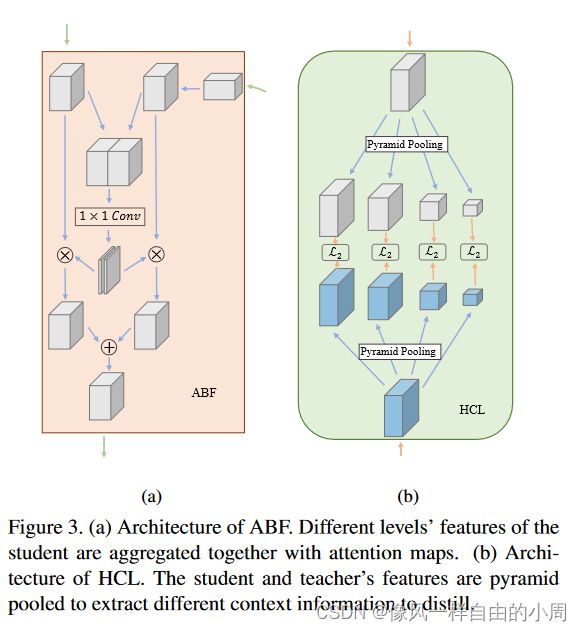
class ABF(nn.Module):
def __init__(self, in_channel, mid_channel, out_channel, fuse):
super(ABF, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(in_channel, mid_channel, kernel_size=1, bias=False),
nn.BatchNorm2d(mid_channel),
)
self.conv2 = nn.Sequential(
nn.Conv2d(mid_channel, out_channel,kernel_size=3,stride=1,padding=1,bias=False),
nn.BatchNorm2d(out_channel),
)
if fuse:
self.att_conv = nn.Sequential(
nn.Conv2d(mid_channel*2, 2, kernel_size=1),
nn.Sigmoid(),
)
else:
self.att_conv = None
nn.init.kaiming_uniform_(self.conv1[0].weight, a=1) # pyre-ignore
nn.init.kaiming_uniform_(self.conv2[0].weight, a=1) # pyre-ignore
def forward(self, x, y=None, shape=None, out_shape=None):
n,_,h,w = x.shape
# transform student features
x = self.conv1(x)
if self.att_conv is not None:
# upsample residual features
y = F.interpolate(y, (shape,shape), mode="nearest")
# fusion
z = torch.cat([x, y], dim=1)
z = self.att_conv(z)
x = (x * z[:,0].view(n,1,h,w) + y * z[:,1].view(n,1,h,w))
# output
if x.shape[-1] != out_shape:
x = F.interpolate(x, (out_shape, out_shape), mode="nearest")
y = self.conv2(x)
return y, x
def hcl(fstudent, fteacher):
loss_all = 0.0
for fs, ft in zip(fstudent, fteacher):
n,c,h,w = fs.shape
loss = F.mse_loss(fs, ft, reduction='mean')
cnt = 1.0
tot = 1.0
for l in [4,2,1]:
if l >=h:
continue
tmpfs = F.adaptive_avg_pool2d(fs, (l,l))
tmpft = F.adaptive_avg_pool2d(ft, (l,l))
cnt /= 2.0
loss += F.mse_loss(tmpfs, tmpft, reduction='mean') * cnt
tot += cnt
loss = loss / tot
loss_all = loss_all + loss
return loss_all
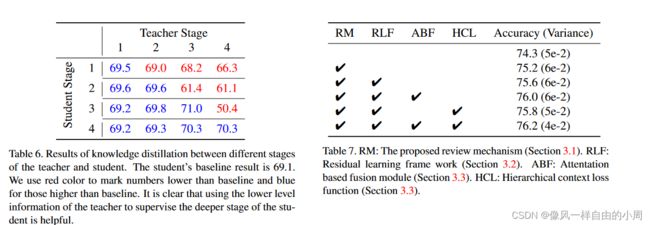
3.实验结果


参考文献
- 【经典简读】知识蒸馏(Knowledge Distillation) 经典之作
- 为什么使用softmax作为多分类的概率函数
- 自蒸馏:一种简单高效的优化方式