【论文精读】GoSPA:一种高能效高性能的全局优化稀疏卷积神经网络加速器
GoSPA: An Energy-efficient High-performance Globally Optimized SParse Convolutional Neural Network Accelerator
一种高能效高性能的全局优化稀疏卷积神经网络加速器
1 问题引入
CNN模型同时存在激活稀疏性和模型稀疏性,这样以来,设计稀疏感知(sparsity-aware)CNN硬件就可以更好地加速CNN模型。
现有的稀疏CNN加速器利用intersection运算(这个intersection操作具体是啥后面介绍)
来搜索和识别两个稀疏向量之间匹配项的关键位置,从而避免不必要的计算。现今主流的设计有三个主要缺点:
- intersection操作的硬件开销很大
- 由于intersection和计算阶段之间的强数据依赖性,并且intersection操作的延迟都在关键的执行路径中,计算阶段会频繁暂停
- intersection操作会引起的不必要数据传输。
本文就是解决上面这三个问题
2 旧方法的弊端
2.1 SCNN:基于笛卡尔积的方法
见下图。

主要思想:
- 将非零权重和激活选出来,以笛卡尔积的方式相乘
- 从所有的结果中,筛选各个位置的结果
问题:
- 不必要的乘法运算:虚线框内容
- 不必要的数据传输:灰色方框内容
2.2 SparTen/ExTensor: 基于intersection的方法

思想:
1.将权重和激活矩阵的非零值,按卷积的运算过程,以流的形式依次配对;(intersection)
2.将匹配位置的权重和激活值相乘再相加得到相应位置的结果。
问题:
1.intersection操作的硬件开销很大(前缀和,CAM扫描搜索)
2.intersection操作的延迟对执行的时间影响很大
3.intersection操作引入了不必要的数据传输(灰色框)
3 GoSPA:概述
3.1 动态流和静态流
动态流:
执行计算前数据元素未知,取决于输入数据,比如激活值取决于输入特征或前一层的输出
静态流:
与动态流相反,数据元素是提前确定好的,且在执行计算过程中,不会改变,比如权重
利用intersection计算的通用方法:
将两个流的稀疏数据移动到intersection单元,执行intersection,然后根据intersection的结果计算,适用于两个动态流的情况,但DNN中的2维卷积有一个静态流,可以有更高效的方法。
3.2 即时的intersection操作
首先基于静态流的稀疏信息,生成SSF(静态稀疏过滤器)。SSF使用bit mask(位掩码)标明静态流中非零值元素的索引。类似下面这样:

简言之,先根据静态流生成SSF,动态流传输前经过SSF筛一次,只传输非零索引对应的元素到计算阶段。
3.3 专门的计算重排序
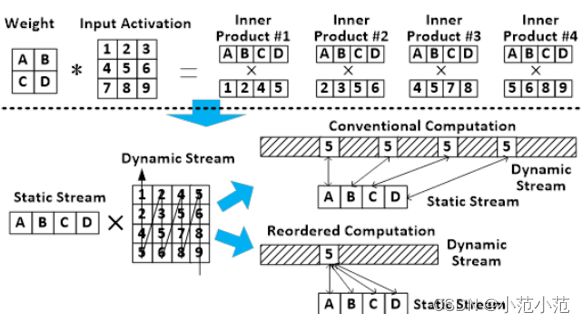
如图所示,一个激活值可能在不同的匹配中与不同的权重配对。之前的激活值是算一次就传一次,现在是把重复计算的激活值只传输一次。
4 GoSPA-数据流
4.1 权重值与激活值坐标的映射
前文提到的计算重排序需要通过CID和PID来实现,每个权重值对应一个PID,每个激活值有一个或多个CID和PID。CID的值代表一组卷积运算中的第几个,同时代表最终运算结果的矩阵中从左到右从上到下的次序。PID代表权重值在权重矩阵中从左到右从上到下的次序,在实际运算中,相同PID的权重和激活值会进行乘积运算,相同CID的一组激活值的运算结果加起来作为最终结果相应位置的值。CID和PID对应的数据从下图可以直观地了解。

首先解释一下其中的约束条件,注意权重和激活之间是多对多关系。
一些已知值:
F: 权重矩阵的维度
H: 激活矩阵的维度
S: 卷积运算的步长(stride)
-
第一个虚线框是权重坐标( W i j W_{ij} Wij)对应激活坐标( a x y a_{xy} axy)的公式,也就是给定权重坐标,求对应的激活坐标。想象卷积执行时权重矩阵在激活矩阵上移动
E = ( H − F ) / S + 1 E=(H-F)/S+1 E=(H−F)/S+1 是移动步数的上界(不可达)
自然得到权重对应激活的公式
x = i + m S x=i+mS x=i+mS
y = j + n S y=j+nS y=j+nS -
第二个虚线框是给定激活坐标,求对应的权重坐标。
P x = x % S P_x=x\%S Px=x%S表示 a x y a_{xy} axy在最后一次被权重矩阵匹配时,在权重矩阵中的相对位置的 x x x坐标 P y = y Py=y%S Py=y同上,表示y坐标。 a x y a_{xy} axy不一定只会被匹配一次,mS和nS表示枚举所有移动的可能
C x = x / S C_x=x/S Cx=x/S: a x y a_{xy} axy在最后一次被权重矩阵匹配时,权重矩阵向下移动了多少步
C y = y / S C_y=y/S Cy=y/S: a x y a_{xy} axy在最后一次被权重矩阵匹配时,权重矩阵向右移动了多少步G = F / S G=F/S G=F/S: 表示权重矩阵内元素,在一行/列扫描后最多被重复匹配几次
0 < = C x − m < E , 0 < = C y − n < E 0<=C_x-m
P x + m S < F , P y + n S < F P_x+mS
综上,激活坐标( a x y a_{xy} axy)对应的权重坐标( W i j W_{ij} Wij)可由如下公式求得:
i = p x + m S i=p_x+mS i=px+mS
j = p y + n S j=p_y+nS j=py+nS
Ps:如果二维坐标理解比较困难,可以先试着理解一维的关系。
4.2 计算CID和PID
有了权重坐标和激活坐标之间的关系,CID和PID是比较好算的,前面提到过,PID就是权重值在权重矩阵中的第几个(从左往右从上往下数),CID就是卷积运算匹配的顺序中的第几个。

权重 W i j W_{ij} Wij的PID是确定的,为 i F + j iF+j iF+j
对于激活a,可能有多个PID和CID,PID取决于配对时对应的权重 W i j W_{ij} Wij,在 a x y a_{xy} axy对应权重 W i j W_{ij} Wij时有:
i = P x + m S , j = P y + n S i=P_x+mS,j=P_y+nS i=Px+mS,j=Py+nS
此时对 a x y a_{xy} axy有:
P I D = i F + j = ( P x + m S ) F + P y + n S PID=iF+j=(P_x+mS)F+P_y+nS PID=iF+j=(Px+mS)F+Py+nS
a x y a_{xy} axy的CID代表此时在卷积运算过程中, a x y a_{xy} axy处于第几个匹配中。矩阵匹配的位置由 C x − m Cx-m Cx−m和 C y − n Cy-n Cy−n决定,E是一行最多移动几步,由于矩阵是从左到右,从上到下移动,于是
C I D = ( C x − m ) E + C y − n CID=(C_x-m)E+C_y-n CID=(Cx−m)E+Cy−n
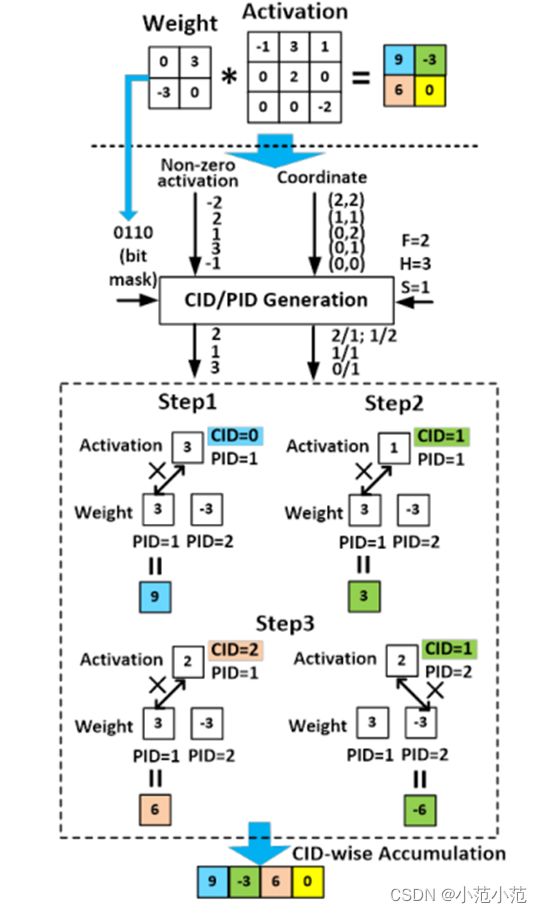
4.3 GoSPA数据流示例
如图,权重变成位掩码的形式(WSP)进入ID生成器,激活的非零值、坐标数据以及卷积参数也进入其中。最后出来的是有非零值匹配的激活值,以及对应的PID和CID值。下面的计算步骤就是PID相同的激活和权重相乘,接着CID相同的激活值的计算结果都加在一起作为输出的一个位置的值。最终按CID顺序排好就是卷积运算的结果。
5 GoSPA—硬件架构
5.1 总体组织架构
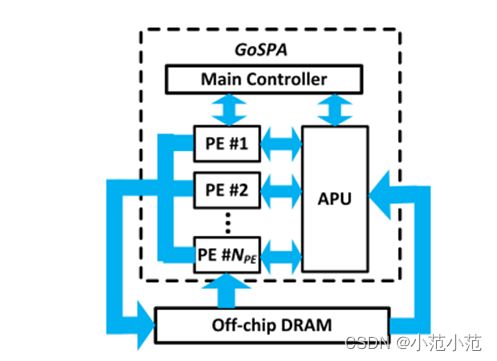
- off-chip DRAM:
存储权重和激活值。其中稀疏权重使用元数据位图表示(WSP),差不多就是前文提到的SSF;激活用压缩稀疏行(CSR)格式表示。CSR就是一种存储稀疏矩阵的方法,可自行百度了解。 - APU(激活处理单元):
计算每个激活值对应的PID和CID,并把数据传输到PE模块 - PE(处理单元):
识别与当前激活值相对应的权重值,并执行乘加操作。计算的结果被ReLU单元处理后,以CSR的形式送回DRAM。
5.2 APU模块
5.2.1 APU模块-概述
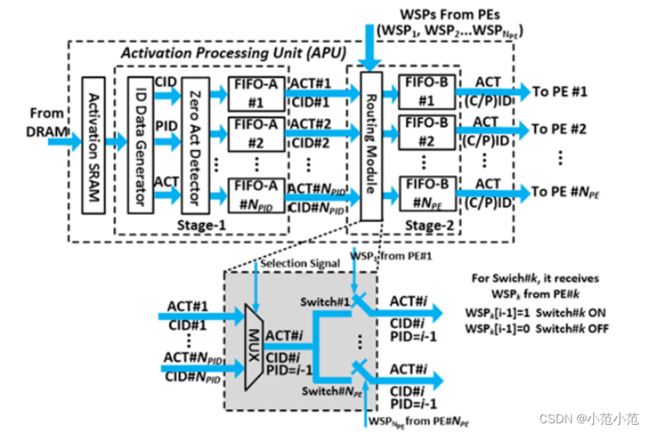
- Activation SRAM:
用来当个缓存,存储当前激活矩阵的行,避免因为卷积操作的重叠频繁访问DRAM获取相同的数据 - Stage-1:
为激活值生成PID和CID,并将这些数据按PID分组送到Stage-2 - Stage-2:
根据权重,将匹配的激活及相关ID信息送到各个PE中
5.2.2 APU模块-ID生成器

- CSR to Coordinate模块:
把CSR结构的数据转换成坐标形式,得到x和y的值。 - Position Locator模块:
计算Px、Py、Cx、Cy,前文有详细说明 - ID Generation模块:
有G*G个生成器单元,包含m和n组合的所有可能,每个生成器单元就拿着Px、Py、Cx、Cy、S等数据,根据上文公式计算一个激活值对应的所有CID和PID,当然还要检查一下这些数据是否能生成合法的ID(也是根据上文公式的限定条件)。最后生成的合法的数据(激活值+ID信息),通过零值检测后,按PID分组送到不同的FIFO-A队列中。
5.2.3 APU数据流演示

第一步:取非零激活值,用CSR表示,传入Stage-1
第二步:在Stage-1中计算每个激活值的PID和CID,具有相同PID的激活值及其CID按顺序传入同一个FIFO-A队列中。
第三步: 所有FIFO-A中的数据经过各个FIFO-B队列的筛选(利用WSP),进入相应的PE中。因为这里一个FIFO-B队列对应一个PE,也就是一个权重。一个FIFO-B筛选出来的激活值与一个权重进行运算。也就是说,每个FIFO-A中的数据要进入所有的FIFO-B队列。上图中skip的位置就是WSP为0的位置。
PE中的操作见后续解析。
5.3 PE模块
5.3.1 PE模块-硬件架构
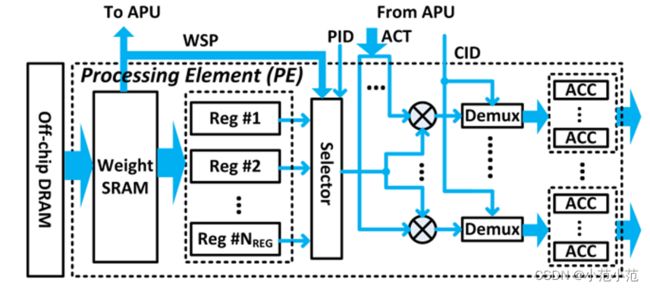
-
Weight SRAM模块:
存储权重数据,包括相应的WSP -
Reg 寄存器:
按顺序存储非零的权重的值,以及相应的PID信息 -
Selector模块:
根据传入激活值的PID选择相应的权重
后面是乘法器,以及根据CID分开的不同加法器阵列
5.3.2 PE模块-处理过程示例

首先看数据格式
权重:位掩码+非零数据
激活:按PID的顺序依次进入
主要是寄存器的处理过程,以一个寄存器为例:
数据存储:当前权重PID,下一个权重PID,当前权重值,下一个权重值
计算:传入的激活值PID等于当前权重PID就将当前权重和传入的激活值传入selector后进入乘法器计算
数据更新:传入的激活值PID不等于当前权重PID,将当前权重PID更新为下一个权重PID,当前权重值更新为下一个权重值,下一个权重PID和权重值从SRAM中读取数据更新。
考虑多个寄存器的情况,让传入的激活值按顺序进入不同的寄存器,将上述数据作为全局变量即可。
实验部分略。