Torch 池化操作大全 MaxPool2d MaxUnpool2d AvgPool2d FractionalMaxPool2d LPPool2d AdaptivePool2d dilation详解
torch 池化操作
-
- 1 池化操作
- 2 类型
-
- 2.1 MaxPool2d()
- 2.2 MaxUnPool2d()
- 2.3 AvgPool2d()
- 2.4 FractionalMaxPool2d()
- 2.5LPPool2d()
- 2.6AdaptiveMaxPool2d()
- 2.7 AdaptiveAvgPool2d()
- 3 总结
自我学习记录,他人转载请注明出处
1 池化操作
作用: 提取图片重点特征,减小图片尺寸大小,从而减少最后的输出数量,池化有不同类型,以下包含torch中针对图像的所有池化操作讲解。
2 类型
2.1 MaxPool2d()
参数:
torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)

需要注意的是
- 当stride不给参数的时候,stride=kernel_size;
- dilation默认为1,当dilation大于等于
2时,则每个卷积核中元素之间相隔diliation-1个位置,然后进行采样,这里只是增加采样区间,但是采样的个数还是不变的,例如kernel_size=3,那么卷积核为33一共9个元素中找最大的,如果dilation为2,那么卷积核为**55**,范围是5*5,但是采样的个数还是9个中找最大,例子如下:

dilation>=2,只是扩大了搜索范围,但是能采样的点数量不变!!!
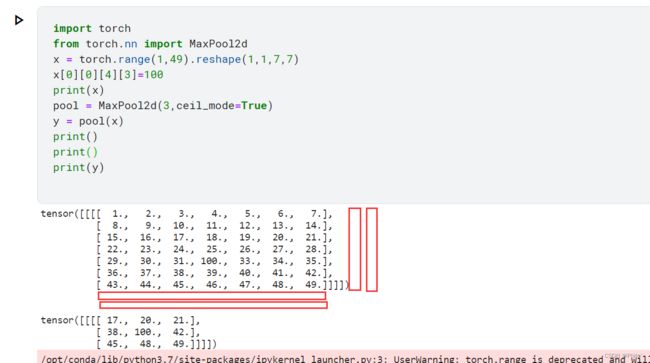
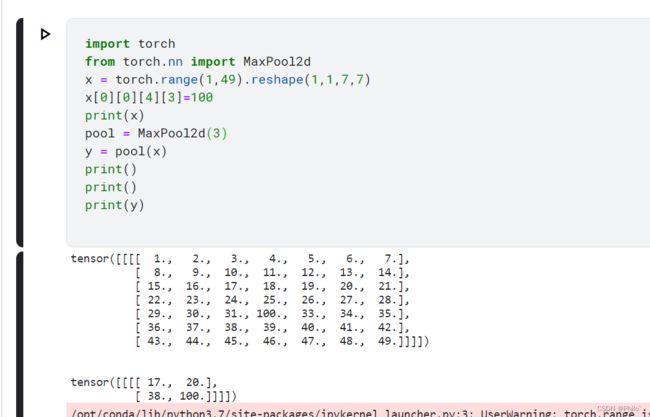
- ceil_model默认为False,当设置为True时,增加取样点的,每一列的右边增加了kernel_size-W%kernel_size列数,下面增加了kernel-H%kernel_size行数!
ceil_model=True:
ceul_mode= False:
- return_indices默认为False,如果为True,则也会返回采样值的位置信息
return_indices=True:
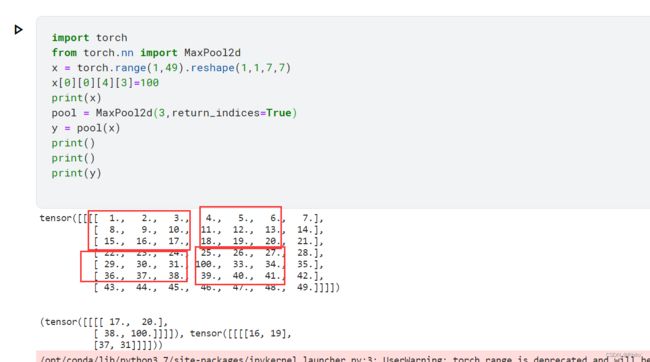
因为是从0开始计数的,所以返回的索引值是能看懂的吧,这里挖个坑,我猜SegNet中最重要的Pool Indices就是借助这个参数实现的!
2.2 MaxUnPool2d()
真相了,最近看过segNet论文,模型铁定是借助了MaxPool2d和MaxUnPoold实现最关键的Pool Indices的,如果不是回来打脸!
参数:
torch.nn.MaxUnpool2d(kernel_size, stride=None, padding=0)

直接上例子:
from torch.nn import MaxPool2d,MaxUnpool2d
x = torch.randn(1,1,4,4)
pool = MaxPool2d(2,return_indices=True) # 这个返回两个东西,一个是最大值,一个是最大值的索引
unPool = MaxUnpool2d(2)
print("原始数据:",x)
y, ind= pool(x)
print("采样数据:",y)
print("索引值:",ind)
print("恢复值:",unPool(y,ind))

需要注意的地方就是,当MaxPool2d中的return_indices=True时,返回值是两个,需要使用两个东西进行接收;同时在使用MaxUnpool2d时候,也是需要传入两个参数的
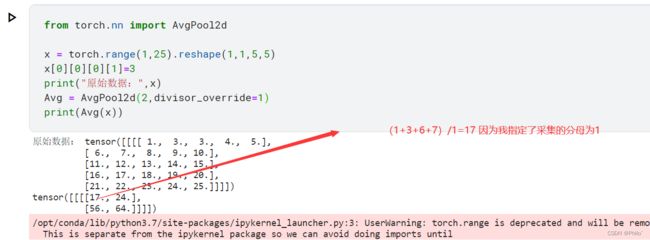
2.3 AvgPool2d()
参数:
torch.nn.AvgPool2d(kernel_size, stride=None, padding=0, ceil_mode=False, count_include_pad=True, divisor_override=None)

ceil_model的含义见2.1,count_nclude_pad参数名字就是指的是求均值时,padding的值是否需要计算在内,divisor_override见图片标记。
直接上例子:
素的:
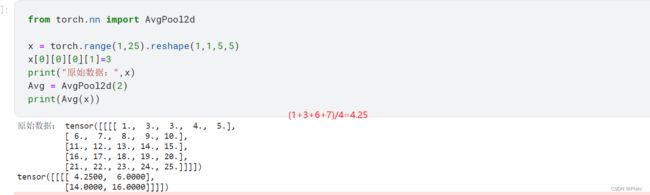
padding=1+count_include_pad=False

divisor_override=1
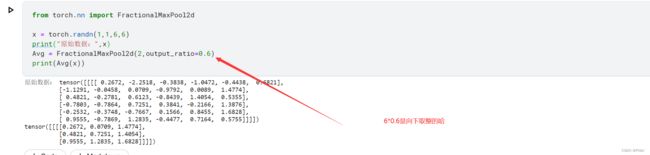
2.4 FractionalMaxPool2d()
参数:
torch.nn.FractionalMaxPool2d(kernel_size, output_size=None, output_ratio=None, return_indices=False, _random_samples=None)

还是比较好理解的,直接上例子:
output_size=(5,5)

output_ratio=0.6
return_indices+MaxunPool2d
from torch.nn import FractionalMaxPool2d,MaxUnpool2d
x = torch.randn(1,1,6,6)
print("原始数据:",x)
Avg = FractionalMaxPool2d(2,output_ratio=0.5, return_indices=True)
y , ind = Avg(x)
print("采样数据:",y)
print("索引值:", ind)
unPool = MaxUnpool2d(2)
print("恢复数据:",unPool(y, ind))
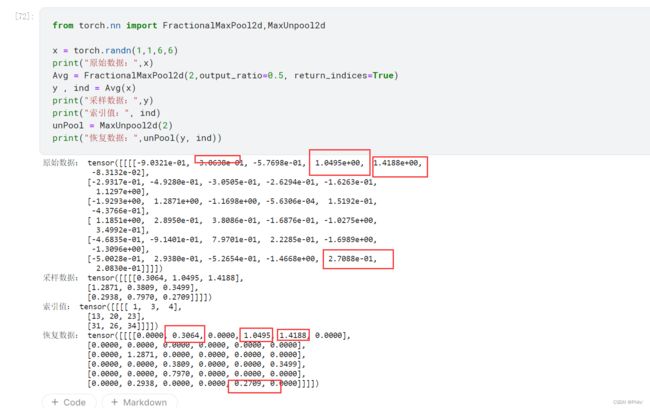
恢复的完美,这个池化操作,更多的是让网络学习步长吧,不知道是不是的,以后填坑!
2.5LPPool2d()
参数:
torch.nn.LPPool2d(norm_type, kernel_size, stride=None, ceil_mode=False)

作用:
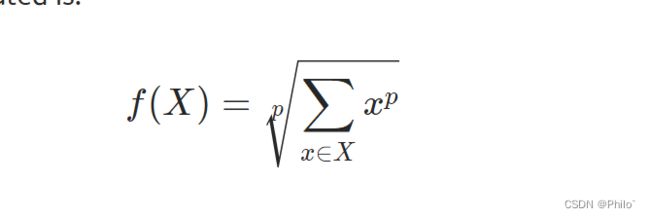
就是计算X内所有数据P次方和后再开P次方
使用时,需要指定P,当P为无穷大时,相当于MaxPooling,想一下,没毛病,如果P=1,就相当于SumPooling
例子:p=2+k=2
from torch.nn import LPPool2d
import torch
import math
x = torch.range(1,20).reshape(1,1,4,5)
print("原始数据:", x)
pool = LPPool2d(norm_type=2, kernel_size=2)
print("pool后数据:",pool(x))
print(math.sqrt(90), math.sqrt(9+16+64+81))

P=30+k=2:
from torch.nn import LPPool2d
import torch
import math
x = torch.range(1,20).reshape(1,1,4,5)
print("原始数据:", x)
pool = LPPool2d(norm_type=30, kernel_size=2)
print("pool后数据:",pool(x))
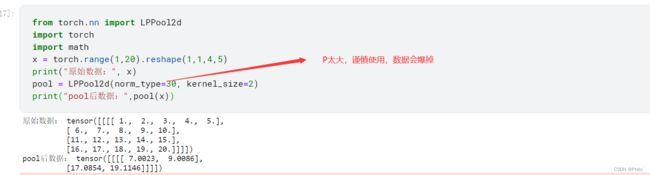
剩下参数ceil_mode就不写例子了,详情看上面的,都是一样的意思!
2.6AdaptiveMaxPool2d()
参数:
torch.nn.AdaptiveMaxPool2d(output_size, return_indices=False)

注意这里和 FractionalMaxPool2d比较一下, FractionalMaxPool2d是指定卷积核大小,但是这个AdaptiveMaxPool2d,不设置卷积核大小,随缘,可学习,所以注意区分。
直接上例子:return_indices+MaxUnpool2d
from torch.nn import AdaptiveMaxPool2d, MaxUnpool2d
import torch
import math
x = torch.range(1,20).reshape(1,1,4,5)
print("原始数据:", x)
pool = AdaptiveMaxPool2d(output_size=3, return_indices=True)
y, ind = pool(x)
unpool = MaxUnpool2d(2)
print("pool后数据:",y)
print("索引为:", ind)
print("恢复后的数据:",unpool(y, ind))
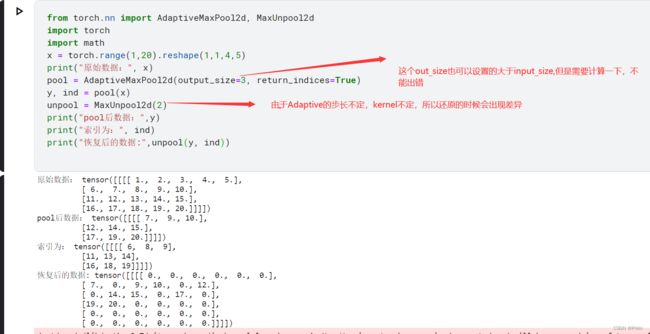
个人认为这里的AdaptiveMaxPool2d很少和MaxUnpool2d一起用,因为Adaptive固定不了kernel,所以还原的时候存在偏差
2.7 AdaptiveAvgPool2d()
torch.nn.AdaptiveAvgPool2d(output_size)

作用: 更简单了,就是自适应平均池化层,指定输出大小就行了
直接上例子:
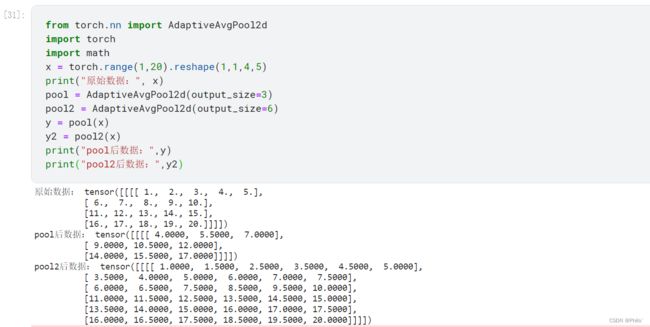
这里的output_size可以大于input_size大小
3 总结
从torch官网看,针对图片,有这7中池化操作,大概分为最大池化类,平均池化类,杂类
- 最大池化实现有四种方式,MaxPool2d,可以设置k,s,p,但是不能设置输出大小,输出大小是计算好的;FractionalMaxPool2d,可以设置k,和输出大小,单数s和p不能设置;AdaptiveMaxPool2d,只能设置输出大小,其余的都设置不了;LPPool2d,这个纯属特列才可以使用,并且特例中的功能还是MaxPool2d的阉割版;除了LPPool2d,其余逐步自由化,增加了网络设置的随机性;
- 平均池化实现有两种方式,AvgPool2d,可以设置k,s,p,分母,是否计算pad值,输出大小不能设置,是计算出来的;AdaptiveAvgPool2d,只能设置一个输出大小,其余的都不能设置,也是逐步自由化;
- 杂类,MaxUnpool2d,是实现Max池化特征恢复的好手段,主要就是配合Max池化操作;LPPool2d,当p为1时,可以实现Sum Pool操作,同时AvgPool2d中指定分母也是可以实现Sum Pool操作的