Task07 Transformer 解决文本分类任务、超参搜索
文章目录
- 1 微调预训练模型进行文本分类
-
- 1.1 加载数据
-
- 小小总结
- 1.2 数据预处理
- 1.3 微调预训练模型
- 1.4 超参数搜索
- 总结
1 微调预训练模型进行文本分类
GLUE榜单包含了9个句子级别的分类任务, 分别是 :
1 鉴别一个句子是否语法正确
2 给定一个假设 , 判断另外一个句子与该假设的关系
3 判断两个句子是否互为paraphrases
4 判断第2句是否包含第1句问题的答案
5 判断两个问句是否语义相同
6 判断一个句子是否与假设成entail关系
7 判断一个句子的情感正负向
8 判断两个句子的相似性
9 WNLI
简单的Dataset 库加载数据集 同时使用transformer 中的Trainer接口 对预训练模型进行微调
1.1 加载数据
from datasets import load_dataset, load_metric
小小总结
这里出现了一个bug是connect 连接错误的问题
估计是 国外的原因吧 这里贡献一个亲测解决的方法
1.通过https://githubusercontent.com.ipaddress.com/raw.githubusercontent.com这个网址,输入raw.githubusercontent.com查询到真实IP地址
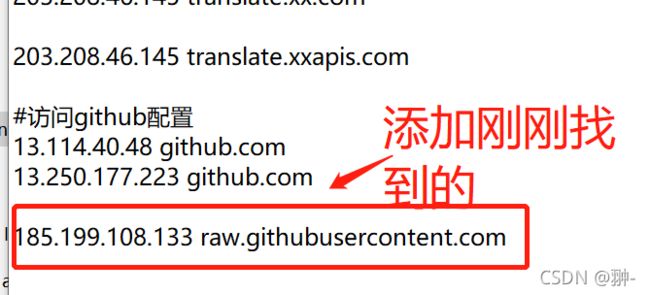
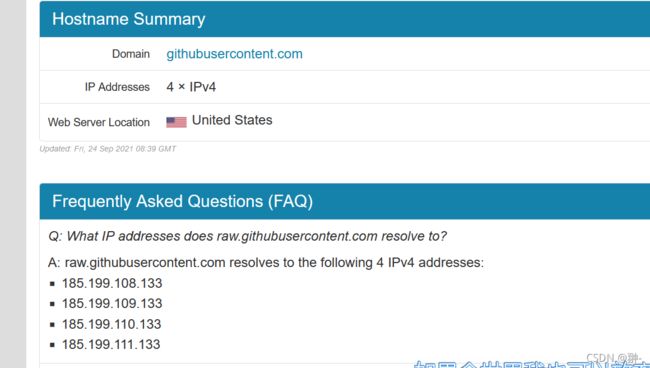 2 进行路径 C:\Windows\System32\drivers\etc 打开 hosts文件 文本形式
2 进行路径 C:\Windows\System32\drivers\etc 打开 hosts文件 文本形式
3 bug解决 散花!!!
后面有时也连接不上没有反应 难受
弄完一定要重启kernel!!!
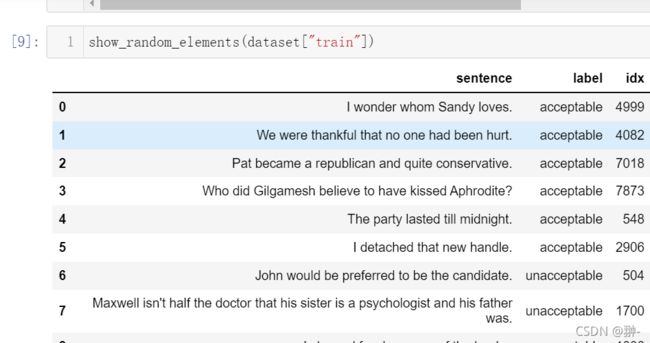
为了能够进一步理解数据长什么样子,下面的函数将从数据集里随机选择几个例子进行展示。
import datasets
import random
import pandas as pd
from IPython.display import display, HTML
def show_random_elements(dataset, num_examples=10):
assert num_examples <= len(dataset), "Can't pick more elements than there are in the dataset."
picks = []
for _ in range(num_examples):
pick = random.randint(0, len(dataset)-1)
while pick in picks:
pick = random.randint(0, len(dataset)-1)
picks.append(pick)
df = pd.DataFrame(dataset[picks])
for column, typ in dataset.features.items():
if isinstance(typ, datasets.ClassLabel):
df[column] = df[column].transform(lambda i: typ.names[i])
display(HTML(df.to_html()))
result
直接调用metric的compute方法,传入labels和predictions即可得到metric的值:
import numpy as np
fake_preds = np.random.randint(0, 2, size=(64,))
fake_labels = np.random.randint(0, 2, size=(64,))
metric.compute(predictions=fake_preds, references=fake_labels)
每一个文本分类任务所对应的metic有所不同,具体如下:
for CoLA: Matthews Correlation Coefficient
for MNLI (matched or mismatched): Accuracy
for MRPC: Accuracy and F1 score
for QNLI: Accuracy
for QQP: Accuracy and F1 score
for RTE: Accuracy
for SST-2: Accuracy
for STS-B: Pearson Correlation Coefficient and Spearman’s_Rank_Correlation_Coefficient
for WNLI: Accuracy
所以一定要将metric和任务对齐
1.2 数据预处理
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_checkpoint, use_fast=True)

tokenizer("Hello, this one sentence!", "And this sentence goes with it.")
为了预处理我们的数据,我们需要知道不同数据和对应的数据格式,因此我们定义下面这个dict。
task_to_keys = {
"cola": ("sentence", None),
"mnli": ("premise", "hypothesis"),
"mnli-mm": ("premise", "hypothesis"),
"mrpc": ("sentence1", "sentence2"),
"qnli": ("question", "sentence"),
"qqp": ("question1", "question2"),
"rte": ("sentence1", "sentence2"),
"sst2": ("sentence", None),
"stsb": ("sentence1", "sentence2"),
"wnli": ("sentence1", "sentence2"),
}
对数据格式进行检查:
sentence1_key, sentence2_key = task_to_keys[task]
if sentence2_key is None:
print(f"Sentence: {dataset['train'][0][sentence1_key]}")
else:
print(f"Sentence 1: {dataset['train'][0][sentence1_key]}")
print(f"Sentence 2: {dataset['train'][0][sentence2_key]}")
随后将预处理的代码放到一个函数中:
def preprocess_function(examples):
if sentence2_key is None:
return tokenizer(examples[sentence1_key], truncation=True)
return tokenizer(examples[sentence1_key], examples[sentence2_key], truncation=True)
接下来对数据集datasets里面的所有样本进行预处理,处理的方式是使用map函数,将预处理函数prepare_train_features应用到(map)所有样本上。
encoded_dataset = dataset.map(preprocess_function, batched=True)
1.3 微调预训练模型
STS-B是一个回归问题,MNLI是一个3分类问题:
from transformers import AutoModelForSequenceClassification, TrainingArguments, Trainer
num_labels = 3 if task.startswith("mnli") else 1 if task=="stsb" else 2
model = AutoModelForSequenceClassification.from_pretrained(model_checkpoint, num_labels=num_labels)
为了能够得到一个Trainer训练工具,我们还需要3个要素,其中最重要的是训练的设定/参数 TrainingArguments。这个训练设定包含了能够定义训练过程的所有属性。
metric_name = "pearson" if task == "stsb" else "matthews_correlation" if task == "cola" else "accuracy"
args = TrainingArguments(
"test-glue",
evaluation_strategy = "epoch",
save_strategy = "epoch",
learning_rate=2e-5,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
num_train_epochs=5,
weight_decay=0.01,
load_best_model_at_end=True,
metric_for_best_model=metric_name,
)
最后,由于不同的任务需要不同的评测指标,我们定一个函数来根据任务名字得到评价方法
def compute_metrics(eval_pred):
predictions, labels = eval_pred
if task != "stsb":
predictions = np.argmax(predictions, axis=1)
else:
predictions = predictions[:, 0]
return metric.compute(predictions=predictions, references=labels)
全部传给 Trainer:
validation_key = "validation_mismatched" if task == "mnli-mm" else "validation_matched" if task == "mnli" else "validation"
trainer = Trainer(
model,
args,
train_dataset=encoded_dataset["train"],
eval_dataset=encoded_dataset[validation_key],
tokenizer=tokenizer,
compute_metrics=compute_metrics
)
trainer.train()
训练完成后进行评估
trainer.evaluate()
 训练挺久的
训练挺久的
1.4 超参数搜索
反注释下面两行安装依赖:
! pip install optuna
! pip install ray[tune]
超参搜索时,Trainer将会返回多个训练好的模型,所以需要传入一个定义好的模型从而让Trainer可以不断重新初始化该传入的模型:
def model_init():
return AutoModelForSequenceClassification.from_pretrained(model_checkpoint, num_labels=num_labels)
和之前调用 Trainer类似:
trainer = Trainer(
model_init=model_init,
args=args,
train_dataset=encoded_dataset["train"],
eval_dataset=encoded_dataset[validation_key],
tokenizer=tokenizer,
compute_metrics=compute_metrics
)
调用方法hyperparameter_search。注意,这个过程可能很久,我们可以先用部分数据集进行超参搜索,再进行全量训练。 比如使用1/10的数据进行搜索:
best_run = trainer.hyperparameter_search(n_trials=10, direction="maximize")
hyperparameter_search会返回效果最好的模型相关的参数:
best_run
将Trainner设置为搜索到的最好参数,进行训练:
for n, v in best_run.hyperparameters.items():
setattr(trainer.args, n, v)
trainer.train()
总结
Datawhale基于transformers的自然语言处理(NLP入门)