Python中的Pandas包
Pandas是Python data analysis的英文缩写。
Pandas提供了快速便捷的组织和处理结构化数据的数据结构和大量功能丰富的函数,使Python拥有强大高效的数据处理和分析环境。目前,pandas广泛应用于统计、金融、经济学、数据分析等众多领域,成为数据科学中重要的Python库。Pandas的主要特点如下:
1、Pandas是基于Numpy构建的。数据组织上,pandas在numpy的N维数组的基础上,增加了用户自定义索引,构建了一套特色鲜明的数据组织方式。其中,序列(Series)对应1维数组,数据类型可以是整型数、浮点数、字符串、布尔值等,数据框(DataFrame)对应2维表格型数据结构,可视为多个序列的集合(因此也称数据框为序列的容器)。其中各元素的数据类型可以相同也可以不相同。
2、Pandas数据框是存储机器学习数据集的常用形式。Pandas数据框的行对应数据集中的样本观测,列对应变量,依实际问题,各变量的存储类型可以相同也可以不同。Pandas对数据框的访问方式与Numpy类似,但其具有复杂而精细的索引,通过索引能更方便地实现数据子集的选取和访问等。此外,Pandas还提供了丰富的函数和方法,能够便捷地完成数据的预处理、加工和基本分析。
一、pandas的序列和索引
import pandas as pd
import numpy as np
from pandas import Series,DataFrame
data = Series([1,2,3,4,5,6,7,8,9],index=['ID1','ID2','ID3','ID4','ID5','ID6','ID7','ID8','ID9'])
print('序列中的值:\n{0}'.format(data.values))
print('序列中的索引:\n{0}'.format(data.index))
# 利用索引号(从0开始)访问指定元素,应以列表形式(如[0,2])指定多个索引号
print('访问序列的第1和第3上的值:\n{0}'.format(data[[0,2]]))
# 利用索引名访问指定元素
print('访问序列索引为ID1和ID3上的值:\n{0}'.format(data[['ID1','ID3']]))
# 利用python运算符in,判断是否存在某个索引名
print('判断ID1索引是否存在:%s;判断ID10索引是否存在:%s' %('ID1' in data,'ID10' in data))
二、pandas的数据框和应用
import pandas as pd
from pandas import Series,DataFrame
data=pd.read_excel('./yuanli/北京市空气质量数据.xlsx')
print('date的类型:{0}'.format(type(data)))
# 数据框的.index和.columns属性中存储着数据框的行索引和列索引名。
# 这里,行索引默认取值:0至样本量N-1。列索引名默认为数据文件中第一行的变量名。
print('数据框的行索引:{0}'.format(data.index))
print('数据框的列名:{0}'.format(data.columns))![]()
# 利用列索引名访问指定变量。多个列索引名应以列表形式放在方括号中
print('访问AQI和PM2.5所有值:\n{0}'.format(data[['AQI','PM2.5']]))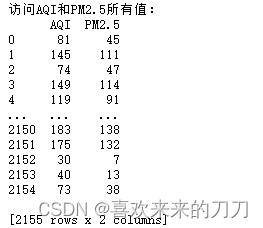
# 利用数据框的.loc属性访问指定行索引和变量名上的元素。 注意:数据框对应二维表格,应给两个索引。
print('访问第2至3行的AQI和PM2.5:\n{0}'.format(data.loc[1:2,['AQI','PM2.5']]))
# 利用数据框的.iloc属性访问指定行索引和列索引号上的元素。 注意:使用行索引时冒号:后的行不包括在内
print('访问索引1至索引2的第2和4列:\n{0}'.format(data.iloc[1:3,[1,3]]))
# 利用数据框的info()方法显示数据框的行索引、列索引以及数据类型等信息。
data.info() 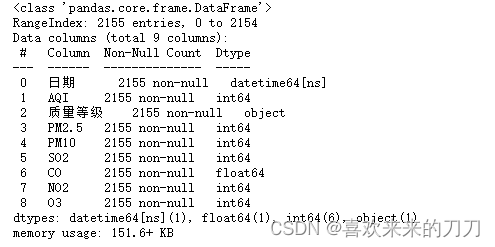
三、pandas的加工处理
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
# 基于python字典建立数据框
# 数据框中的数据不仅可以来自python列表,也可来自python字典
# 优势在于引入键,可通过键来更加灵活地访问数据
# 下面的字典包括key和var1两个键,两组键值分别是冒号后面的
# 从数据集的角度看,key和var1两个键对应两个变量,即数据集的两个列。两组键值对应数据集两列上的取值
# 需要说明的是,字典本身并不要求各组键值的个数相等,但是对应到数据集上,不相等就意味着有些样本观测在某个变量上没有具体取值
# 当指定数据框的数据来自字典时,是不允许的
df1=DataFrame({'key':['a','d','c','a','b','d','c'],'var1':range(7)})
print('df1:\n',df1)
df2=DataFrame({'key':['a','b','c','c'],'var2':[0,1,2,2]})
print('df2:\n',df2)
# 利用Pandas函数merge()将两个数据框依指定关键字做横向合并,生成一个新数据框。
# 这里将数据框df1和df2按变量key的取值做横向“全合并”,若某个样本观测在某个变量上没有取值,默认为缺失值,以NaN表示
df=pd.merge(df1,df2,on='key',how='outer')
print('合并后的数据:\n',df)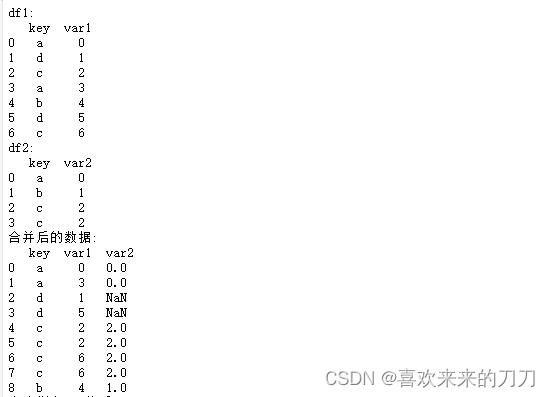
print('人为指定NaN值后:\n{0}'.format(df))
# 利用函数drop_duplicates()剔除数据框中在全部变量上均重复取值的样本观测
df=df.drop_duplicates()
print('删除重复数据行后的数据:\n{0}'.format(df)) 
print('判断是否为缺失值:\n{0}'.format(df.isnull()))
print('判断是否不为缺失值:\n{0}'.format(df.notnull()))
# 利用数据框.dropna()方法剔除取NaN的样本观测。
print('删除缺失值后的数据:\n{0}'.format(df.dropna()))
# 利用数据框.apply()方法以及匿名函数计算各个变量的均值,并存储在名为fill_value的序列中。
# apply方法的本质是实现循环处理,匿名函数告知了循环处理的步骤。
# 例如,df[['var1','var2']].apply(lambda x:x.mean())的意思是:循环或依次对数据框df中变量var1和var2(均为序列)做匿名函数指定的处理
# 匿名函数是一种最简单的用户自定义函数,其中x是函数所需要的参数(x将依次取值为var1和var2),处理过程是对x取平均值
fill_value=df[['var1','var2']].apply(lambda x:x.mean())
# 利用数据框的.fillna()方法,将所有NaN替换为指定值(这里为fill_value)。
print('以均值替换缺失值:\n{0}'.format(df.fillna(fill_value))) 
四、pandas数据的加工处理和应用
import numpy as np
import pandas as pd
from pandas import Series,DataFrame
data=pd.read_excel('./yuanli/北京市空气质量数据.xlsx')
# 利用数据框函数replace将数据框中的0(表示无检测结果)替换为缺失值(NaN)
data=data.replace(0,np.NaN)
# 利用apply方法和匿名函数,基于“日期”变量得到每个观测样本的年份和月份
# 数据中的“日期”是python的datetime型,专用于存储日期和时间格式变量
# python有整套处理datetime型数据的函数、方法或属性,.year和.month两个属性分别存储年份和月份
data['年']=data['日期'].apply(lambda x:x.year)
month=data['日期'].apply(lambda x:x.month)
# 建立一个关于月份和季度的字典 quarter_month
quarter_month={'1':'一季度','2':'一季度','3':'一季度',
'4':'二季度','5':'二季度','6':'二季度',
'7':'三季度','8':'三季度','9':'三季度',
'10':'四季度','11':'四季度','12':'四季度'}
# 利用函数map,依据字典quarter_month,将序列month中的1,2,3月份映射到相应的季度上
# map对一个给定的可迭代对象,依据指定的函数,对其中各个元素进行处理
# 这里对可迭代序列month中的每个元素进行处理,处理方法由匿名函数指定,即输出字典quarter_month中给定键对应的值
data['季度']=month.map(lambda x:quarter_month[str(x)])
# 定义一个用于对AQI分组的列表bins
bins=[0,50,100,150,200,300,1000]
# 利用pandas的cut方法对AQI进行分组
# cut方法用于对连续数据分组,也称对连续数据进行离散化处理
data['等级']=pd.cut(data['AQI'],bins,labels=['一级优','二级良','三级轻度污染','四级中度污染','五级重度污染','六级严重污染'])
print('对AQI的分组结果:\n{0}'.format(data[['日期','AQI','等级','季度']]))
# 利用数据框的groupby()方法,计算各季度AQI和PM2.5的平均值。
# groupby方法是将数据按指定变量分组,对分组结果可以进一步计算均值等
print('各季度AQI和PM2.5的均值:\n{0}'.format(data.loc[:,['AQI','PM2.5']].groupby(data['季度']).mean()))
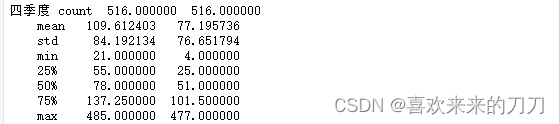
# 计算几个季度AQI和PM2.5的基本描述统计量(均值,标准差,最小值,四分位数,最大值)。
# 这里将groupby、apply以及匿名函数放在一起使用,首先将数据按季度分组,然后依次对分组后的AQI和PM2.5根据匿名函数指定的步骤处理
print('各季度AQI和PM2.5的描述统计量:\n',data.groupby(data['季度'])['AQI','PM2.5'].apply(lambda x:x.describe()))
# 定义了一个名为top的用户自定义函数:对给定数据框,按指定列(默认AQI列)值的降序排序,返回排在前n(默认10)条数据。
def top(df,n=10,column='AQI'):
return df.sort_values(by=column,ascending=False)[:n]
# 调用用户自定义函数top,对data数据框中,按AQI值的降序排序并返回前5条数据,即AQI最高的5天的数据。
print('空气质量最差的5天:\n',top(data,n=5)[['日期','AQI','PM2.5','等级']])
# 首先对数据按季度分组,依次对分组数据调用用户自定义函数top,得到各季度AQI最高的3天数据。
print('各季度空气质量最差的3天:\n',data.groupby(data['季度']).apply(lambda x:top(x,n=3)[['日期','AQI','PM2.5','等级']])) 
# 利用Pandas函数crosstab()对数据按季度和空气质量等级交叉分组,并给出各个组的样本量。
# crosstab方法可以方便地编制两个分类变量的列联表。列联表单元格可以是频数,也可以是百分比。可指定是否添加行列合计等
print('各季度空气质量情况:\n',pd.crosstab(data['等级'],data['季度'],margins=True,margins_name='总计',normalize=False))
# 利用Pandas的get_dummies得到分类型变量“等级”的哑变量。
# 哑变量是统计学处理分类型数据的一种常用方式。对具有K个类别的分类型变量X,可生成K个变量如X1,X2,...,XK,且每个变量仅有0和1两个取值
# 这些变量称为分类型变量X的哑变量。其中,1表示是某个类别,0表示不是某个类别
pd.get_dummies(data['等级'])
# 利用数据框的join()方法,将原始数据和哑变量数据,按行索引进行横向合并。
# 使用join方法进行数据的横向合并时,应确保两份数据的样本观测在行索引上是一一对应的,否则会出现张冠李戴的错误。
data.join(pd.get_dummies(data['等级']))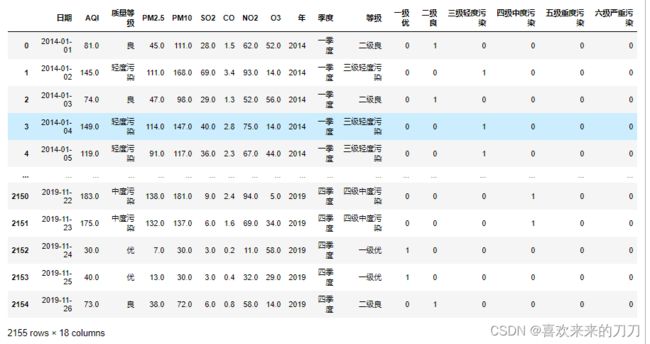
np.random.seed(123)
# 利用Pandas函数random.randint()在指定范围内随机抽取指定个数(这里是10)的随机数。
sampler=np.random.randint(0,len(data),10)
print(sampler)
# 利用Pandas函数random.permutation是对数据随机打乱重排。之后再抽取前10个样本观测。
sampler=np.random.permutation(len(data))[:10]
print(sampler)
# 利用数据框的take()方法,基于指定随机数获得数据集的一个子集。
data.take(sampler)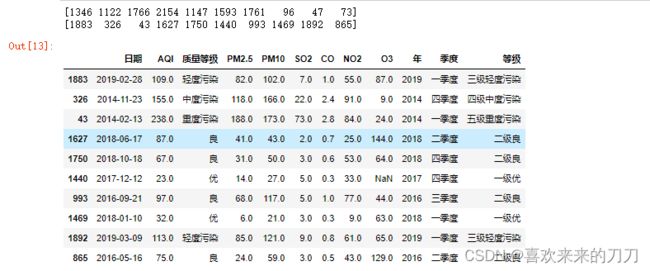
# 利用数据框访问的方式,抽取满足指定条件(质量等级等于优)行的数据。
data.loc[data['质量等级']=='优',:]
# np.take(a, indices, axis=None, out=None, mode='raise')
# 作用: 沿轴从数组中获取元素。
import numpy as np
a = np.array([[1,2,4,([1,2,6])],
[3,2,6,([6,5,1])],
[6,9,4,([3,7,5])]], dtype=object)
print(a.take(indices=1,axis=0))
print(a.take(indices=2,axis=0)) # axis=0 按行; axis=1 按列 (二维数组,so,只能取0或1)
print(a.take(indices=0,axis=1))
print(a.take(indices=3,axis=1)) 
import numpy as np
b = np.array([[1, 2, 4, ([1, 2, 5])],
[3, 2, 6, ([6, 5, 1])],
[6, 9, 4, ([3, 7, 5])]], dtype=object)
print(b.take(1,1)) # 按列,取第1列
print(b.take(0,1)) # 按列,取第0列
print(b.take(0,0)) # 按行,取第0行
print(b.take(1,0)) # 按行,取第1行 
print(a.take(1,0)) ![]()
print(a.take(1,1)) ![]()