CNN+Transformer=SOTA!CNN丢掉的全局信息,Transformer来补
转自 新智元 来源:Microsoft
编辑:LRS、小匀
【新智元导读】微软在arxiv上发布新论文,把CNN带入Transformer后能够同时兼顾全局和局部的信息。
在计算机视觉技术发展中,最重要的模型当属卷积神经网络(CNN),它是其他复杂模型的基础。
CNN具备三个重要的特性:一定程度的旋转、缩放不变性;共享权值和局部感受野;层次化的结构,捕捉到的特征从细节到整体。
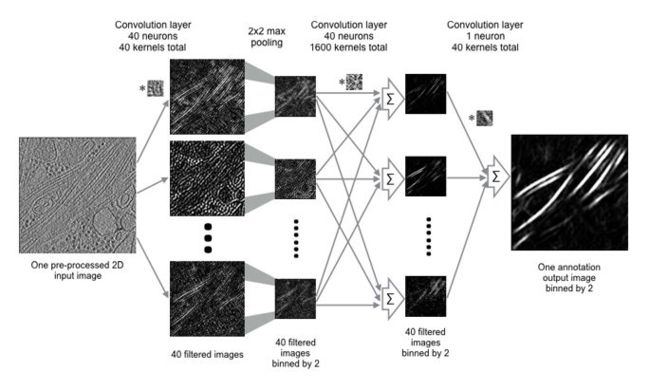
这些特性使得CNN非常适合计算机视觉任务,也使CNN成为深度学习时代计算机视觉领域的基石,但CNN的细节捕捉能力使它的全局建模能力较弱。
所以如何使CV模型捕获全局特征逐渐成为研究热点。
NLP的模型能解决CV问题?
2017年,Transformer横空出世,Attention is all you need!随后BERT类模型在各大NLP排行榜屠杀,不断逼近、超过人类的表现。
2020年Google Brain研究员提出的Vision Transformer(ViT)以最小的改动将Transformer应用于用CV领域。
Transformer的动态注意力机制、全局建模能力使得ViT在通过超大规模预训练后,表现出了很强的特征学习能力。
然而,ViT在设计上是没有充分利用视觉信号的空间信息,ViT仍然需要借助Transformer中的Position Embedding来弥补空间信息的损失。
视觉信号具有很强的2D结构信息,并且与局部特征具有很强的相关性,这些先验知识在ViT的设计中都没有被利用上。
CNN的设计又可以很好地弥补ViT设计中的这些不足,或者也可以说,ViT的设计弥补了CNN全局建模能力较弱的问题。
这篇论文提出一种全新的基础网络Convolutional vision Transformers (CvT),既具备Transforms的动态注意力机制、全局建模能力,又具备CNN的局部捕捉能力,同时结合局部和全局的建模能力。
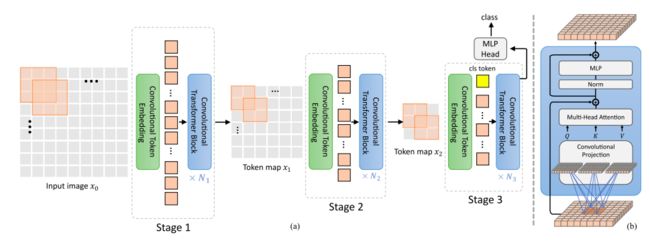
CvT是一种层级设计结构,在每一层级,2D的图像或Tokens通过Convolutional Embedding生成或更新特征向量。
每一层包括N个典型的Convolutional Transformer Block,把线性变换替换成卷积变换输入到多头attention机制,再进行Layer Norm。
Convolutional Projecton使得CvT网络可以维持图像信号的空间结构信息,也使得Tokens更好的利用了图像信息的局部信息相关性,同时也利用了注意力机制对全局信息进行建模。
而卷积操作的灵活性,使得我们可以通过设置卷积操作的步长来对key,value进行降采样,从而进一步提升Transformer结构的计算效率。
Convolutional Embedding和Convolutional Projection充分利用了视觉信号的空间特性,所以在CvT的结构中,空间信息不需要引入position embedding,使得CvT更灵活的应用于计算机视觉中各类下游任务,如物体检测,语义分割等。
性能表现
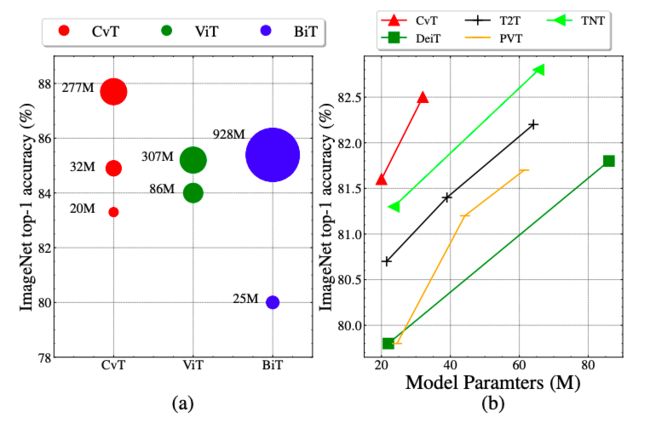
CvT与同时期的其他Transformer-based工作相比,在同等模型大小下在ImageNet1k上取得了明显优于其他模型的准确率。
此外,CvT在大规模数据集ImageNet22k的预训练上也取得了不错的性能,CvT-W24以更少的参数量,在ImageNet-1k 基准测试集上获得了87.7%的Top-1准确率,超越在同样规模数据集训练的ViT-H/L模型。
CvT 和SOTA模型模型在Image net, ImageNet Real和ImageNet V2这些数据集上性能的比较。同等规模和计算量情况下, CvT的效率优于ResNet和ViT,甚至同时期的其它Transformer-based的工作。
通过网络结构搜索技术,对CvT的模型结构像每层Convolutional Projection中的步长和每层MLP的expansion ratio进行有效的搜索后,最优的模型CvT-13-NAS。以18M的模型参数量, 4.1G的FLOPs在ImageNet1k上取得了82.2的结果。
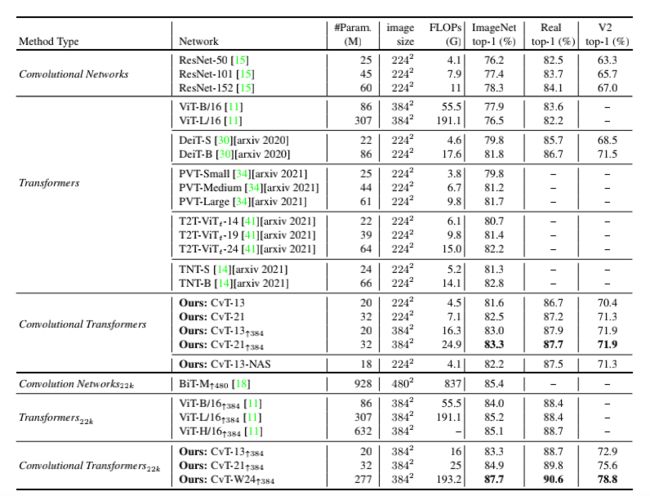
CvT 和Google的BiT,ViT在下游任务中的迁移能力,CvT-W24以更少的模型参数量在ImageNet1k上取得了87.7的结果,明显优于Google的BiT-152x4和ViT-H/16,进一步验证了CvT模型优异的性能。
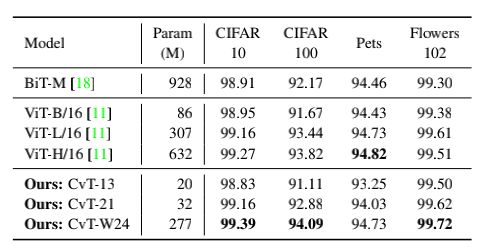
CvT是一种结合了CNN结构和Transformers结构各自优势的全新基础网络,实验结果也验证了CvT在ImageNet以及各种分类任务中的有效性。可以展望,这种融合的网络势必会对视觉其他的任务性能提高进一步影响。
参考资料:
https://arxiv.org/pdf/2103.15808.pdf
有很多好书推荐给大家,请扫码查看!

