基于卷积神经网络的图像分类
实验任务与要求:
使用PyTorch编写并训练卷积神经网络模型,用于识别花卉。花卉数据集17flowers.zip 与Resnet-50 预训练权值文件resnet50.pth 请从https://pan.baidu.com/s/10yigaKYGQyO9yWX0YN70Ng 下载, 其中17flowers.zip 中包含了train和val两个目录,分别为训练集与验证集,各有17种花卉的图像,该数据集是从oxfordflowers 17数据集构造的。
第1部分:自行设计一个卷积神经网络,实现对花卉图像的识别;
第2部分:使用ImageNet上预训练的ResNet-50模型,迁移到花卉识别任务上。
以上两个任务中,都要对你所训练的模型进行测试,计算出模型在训练集和验证集上的识别精度,以及混淆矩阵。根据混淆矩阵总结出下一步要如何调整改进。
网络结构设计
本实验采用计算机视觉中卷积神经网络进行图像的分类,卷积神经网络采用分级提取特征的原理,每一级的特征均有网络学习提取到,识别效果优于人工特征提取的算法。对图像进行卷积时,过滤器在不断滑动的过程中生成一张特征图,卷积网络可以减少神经网络的权重数目,池化的目的是降低数据的维度,实际上为下采样。
本卷积网络结构的设计,借鉴了经典的VGG模型,此模型在VGG网络相比AlexNet的一个改进是采用连续的几个3*3的卷积核代替AlexNet中的较大卷积核,对于给定的感受野,采用堆积的小卷积核是优于采用大的卷积核,因为多层非线性层可以增加网络深度来保证学习更复杂的模式,而且参数的个数较少。为了较好地处理图像中较小的花朵样本,尽可能保留较小花朵的形状等特征信息,输入图像的尺寸统一为(450,450),在一层卷积和池化的过程中,采用33的过滤器对图片进行卷积,产生16张448448的特征图,然后使用22的核,步长为2进行池化,最终生成16张224224的特征图,第二层采用两层的33的过滤器进行卷积,产生32张220220的特征图,再使用22的核,步长为2的进行池化,得到32张110110的特征图,再通过两层的33的卷积核,和22的池化层,得到64张5353的特征图,再通过四层33的卷积核,和33的池化层得到128张1515的特征图,再通过三层33的卷积层和一层33的池化层得到256张33的特征图,最后一层卷积层采用33的过滤器,得到512张1*1特征图,后面进行全连接层,第一层进行输入为512和输出256之间进行全连接,再进行256输入和64输出的全连接,最后进行64的输入和17输出的全连接,进而实现对17类别花卉的分类任务。
通过分析训练集和验证集的准确率,发现模型出现了过拟合的现象,因此通过数据集的增广和在全连接第一层后加入Dropout函数,来抑制过拟合。
迁移学习
迁移学习的原理是可以基于卷积神经网络中的每一层的卷积层负责抽取不同的特征,早期的卷积层抽取具有一般性的低级特征,晚期的卷积层抽取具有特殊性的高级特征。两个识别任务越相似,两者之间的高级特征就越相似,意味着只要根据任务的相似度适当微调卷积层范围,就可以实现两者之间的任务迁移。通过利用ImageNet上预训练的ResNet-50模型。
实验配置与结果
由于输入的图片尺寸不一致,首先进行图片尺寸的统一化,由于大多数网络采用450的尺寸大小,因此将图片尺寸统一为(450,450),同时将图片转变成张量,然后进行标准化,标准化采用ImageNet的中学习到的平均值和标准差:
transforms.Normalize(mean = [0.485,0.456,0.406],std = [0.229,0.224,0.225])])
神经网络的训练周期为150
自设计的卷积网络实验结果分析
本实验采用17flowers数据集,数据集有17类花卉,其中包括训练集和验证集,其中每类图片大约有80张图片,整个数据集有1360张图片。通过自己设计的卷积神经网络进行训练和测试,得到如下结果:
训练集准确率及混淆矩阵:
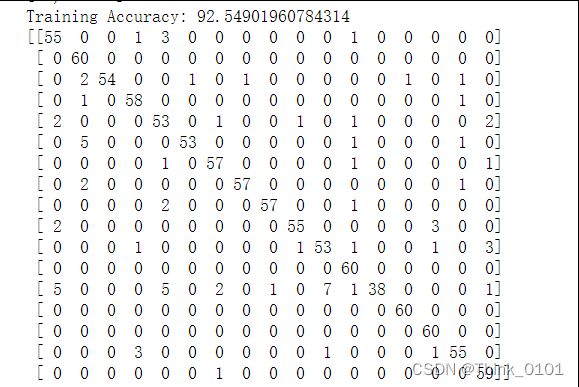
验证集准确率和混淆矩阵:
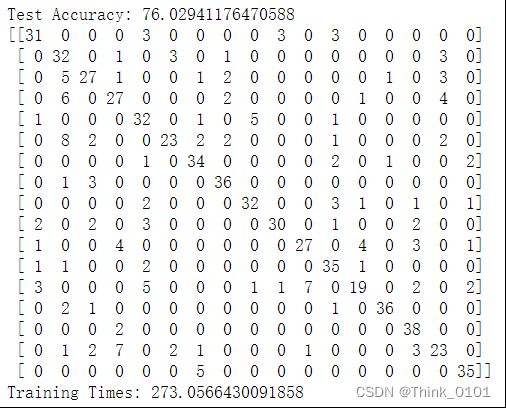
通过结果分析可发现:对于训练集卷积神经网络可以得到较高的准确率的模型,但是在验证集中准确率为76%,因此模型可能存在过拟合的情况,因此需要进行模型过拟合操作,对于模型过拟合可以采用加正则化(增加dropout)或增加训练样本,或简化模型,只训练高层的权重。因此,从两个方面来进行调整**,一方面进行数据的增广,另一方面添加正则化。**
方法一:数据集的增广
通过对样本图片进行一些变换,主要是图像翻转,随机缩放和比例变换,随机裁剪,RandomResizedCrop()指定的缩放系数范围scale和长宽比例范围ratio,对图像进行随机缩放和比例变换,然后随机裁剪为一幅size大小的图像。由于样本图像大部分的像素值为500700和500600,为了让样本进行有效裁剪,缩放系数采用[0.7,1.3],因此采用截取450*450的图片作为样本,可以确保较大概率样本在图片中。同时也增加了裁剪的随机性,有利于增加样本数据。ColorJitter()函数对PIL图像的亮度、对比度、饱和度以及色调进行随机扰动,增加数据样本,有利于提高模型的泛化能力。
方法二:dropout函数
由于模型的参数较多,而样本较少,导致模型易过拟合,通过dropout函数使得一部分神经元失活,达到抑制过拟合的效果。一般概率值取0.5或0.3。
通过以上的处理后重新训练模型得到的结果如下所示:

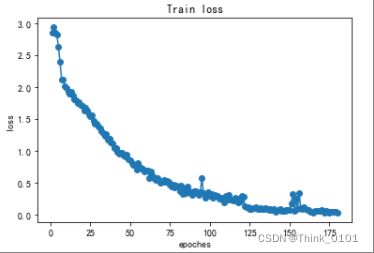
可以发现模型的准确率和泛化能力都提高了,其中通过画出模型训练过程的loss值得变化如下所示:
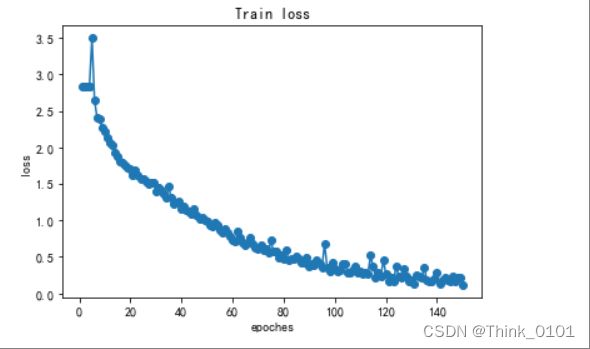
可以看出在训练过程中,模型的loss总体是一直下降的。
数据样本分析:
通过分析验证集上的混淆矩阵可以找到模型分类效果较差的种类,可以看出模型对第13类别的花分类出现较多错误,其中将12个样本分成了第11类,通过分别对此样本中的图像进行预测,打印出预测结果错误的样本,通过观察错误样本,找到可能存在的问题。由于训练集上第13类分成第11类的样本数为8,而验证集为12,因此可以发现,训练集样本为60个,验证集样本为40个反而错误数量更多,通过分析训练集与验证集的数据分布:
训练集样本:
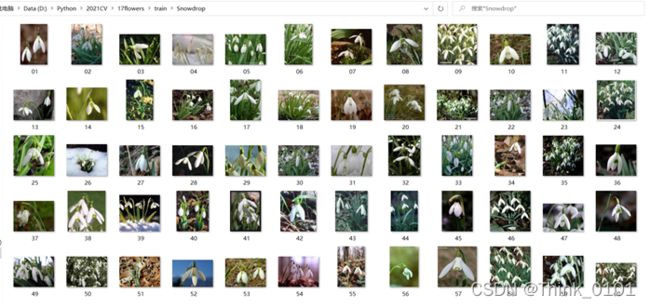
验证集样本:
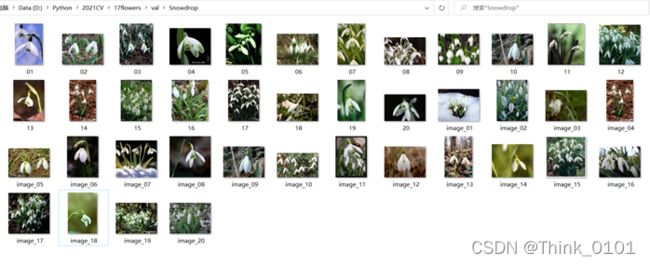
观察第11类别的分布如下:

可以明显发现,第11类别的样本存在较多的绿色的叶子作为背景,而观察第13类别的训练集和验证集中样本的分布可以发现,对于训练集中背景为绿色的样本数量为21,所在比例为35%,而验证集中背景为绿色的样本数量为23,所在比例为57.5%,因此可以发现训练集和验证集存在“分布漂移”现象**,模型很可能将第13类的一部分背景为较多绿色的样本分成了第11类,因此才会出现验证集的错误数比训练集多**(由于验证集中背景为绿色的更多)。
通过将模型预测错误的样本输出可以看出上述猜想很有可能:


因此,通过将训练集中的数据分布进行修改,即增加第13类的中的背景是绿色的样本数量,希望达到数据同分布,即复制一部分背景为绿色的样本图片放入训练集中,通过计算确定大概增加20张绿色背景的样本图片,增加模型对背景为绿色的样本的分类能力。构建新的训练数据集如下所示:
通过重新训练模型,并采用分阶段训练的方式,不断缩小学习率,使得loss可以继续下降,可以得到模型的结果如下:

可以看出模型较之前在准确率上有提升,可以明显看出对于第13类花的分类在训练集上已经没有出错,在验证集上出错的数量减少了一半,可以看出对数据的处理对模型的泛化能力还有有所帮助的。
迁移学习实验结果分析
训练集准确率和混淆矩阵:
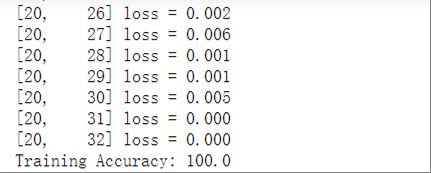
通过结果可以看出,训练的结果非常好,训练集上的损失几乎为0,准确率达到100%,因此就不存在混淆矩阵。
验证集准确率和混淆矩阵:
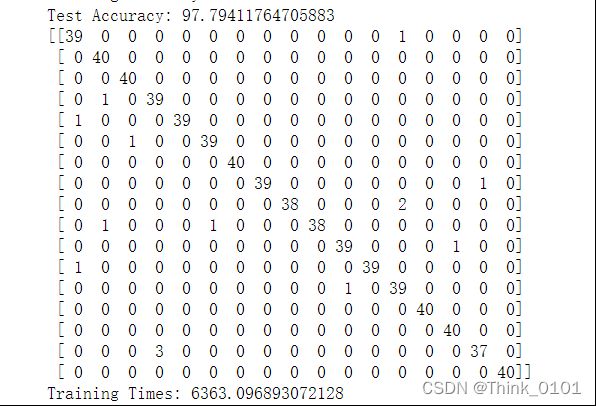
验通过结果可以看出,模型在验证集上也有非常好的分类性能,因此可以看出迁移学习后的模型有非常好的泛化能力。但是模型的复杂度较高,计算量较大,可以看出模型训练时间达到1.7小时左右。
源代码
#在下面编写你的代码
net = models.resnet50(pretrained=False)
#使用本地磁盘上的模型参数文件
state_dict = torch.load('./resnet50.pth')
#把读入的模型参数加载到模型model中:
net.load_state_dict(state_dict)
#原始ResNet模型是用于对ImageNet图像做分类的,分类层有1000个输出节点。在17Flower数据集上,要把这个分类层改造为输出102个节点。这只需要把原始网络中的FC层替换为新的全连接层即可
num_classes = 17
featureSize = net.fc.in_features
net.fc = nn.Linear(featureSize, num_classes)
from torchnet.meter import ConfusionMeter
#计算混淆矩阵
def evalWithCM(net, data_loader,num_classes,device):
net.eval()
correct = 0
total = 0
cm = ConfusionMeter(num_classes)
with torch.no_grad():
for data in data_loader:
images, labels = data[0].to(device), data[1].to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
cm.add(predicted, labels)
acc = correct / total
return acc, cm
# 训练模型
def train(net, optimizer, loss_fn, num_epoch, data_loader, device):
net.train()#进入训练模式
for epoch in range(num_epoch):
running_loss = 0.0
for i, data in enumerate(data_loader):
inputs, labels = data[0].to(device), data[1].to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = loss_fn(outputs, labels)
loss.backward()
optimizer.step()
running_loss = loss.item()
print('[%d, %5d] loss = %.3f' % (epoch+1, i+1, running_loss))
import time
t = time.time()
if torch.cuda.is_available():
device = torch.device('cuda')
else:
device = torch.device('cpu')
xentropy = nn.CrossEntropyLoss()
optimizer = optim.RMSprop(net.parameters(), lr=0.001)
num_epoch = 20
train(net=net,
optimizer=optimizer,
loss_fn=xentropy,
num_epoch=num_epoch,
data_loader=train_loader,
device=device)
train_acc,cm1 = evalWithCM(net=net,
data_loader = train_loader,num_classes = 17,
device=device)
val_acc ,cm2 = evalWithCM(net=net,
data_loader = val_loader,num_classes = 17,
device=device)
print('Training Accuracy:',100 * train_acc)
print('Test Accuracy:',100 * val_acc)
print(cm2.value())
print('Training Times:' ,time.time()-t)