时间序列预处理
数据预处理的主要流程为:数据清洗、特征选择、归一化处理、划分窗口、Shuffle和划分数据集等五个阶段。选用何种方法没有统一的标准,只能根据不同类型的分析数据和业务需求,在对数据特性做了充分的理解之后,再选择与其最适配的数据预处理技术。
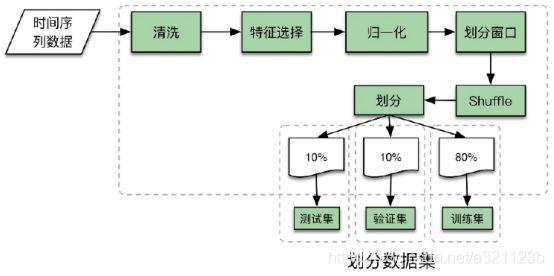
下面来详细介绍每个阶段的处理
数据预处理-平稳性检验
一种是根据时序图和自相关图做出判断的图检验方法;一种是构造检验统计量进行假设检验的方法。 图检验操作简便,运用广泛,它的缺点是判别结论带有很强的主观色彩。所以最好能用统计检验的方法加以辅助判断。目前最常用的平稳性检验方法是单位根检验(unit root test)。
1.时序图检验
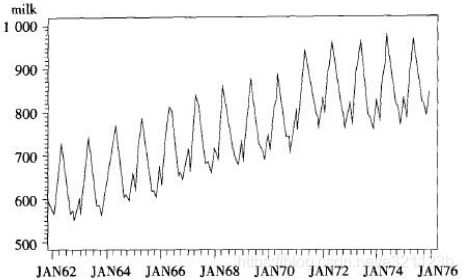
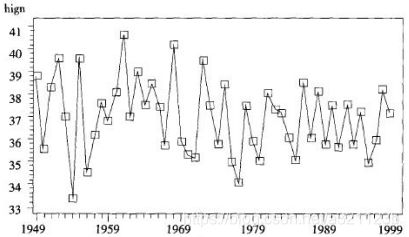
根据平稳时间序列均值、方差Wie常数的性质,平稳时间序列的时序图应该是显示出该数列始终在一个常数值附近随机波动,而且波动的范围有界的特点。如下图中,图1为非平稳序列,图2为平稳序列。
2.自相关图检验
自相关图就是一个平面二维坐标垂线图,一个坐标轴表示延迟时期数,另一个坐标轴表示自相关系数,通过以垂线表示自相关系数的大小。
平稳时间序列通常具有短期相关性,该性质使用自相关系数来描述就是随着延迟期数k的增加,平稳时间序列的自相关系数ρ会很快地衰减为0;反之,非平稳序列的自相关系数ρ衰减向0的速度通常会比较慢。
数据预处理-清洗转换
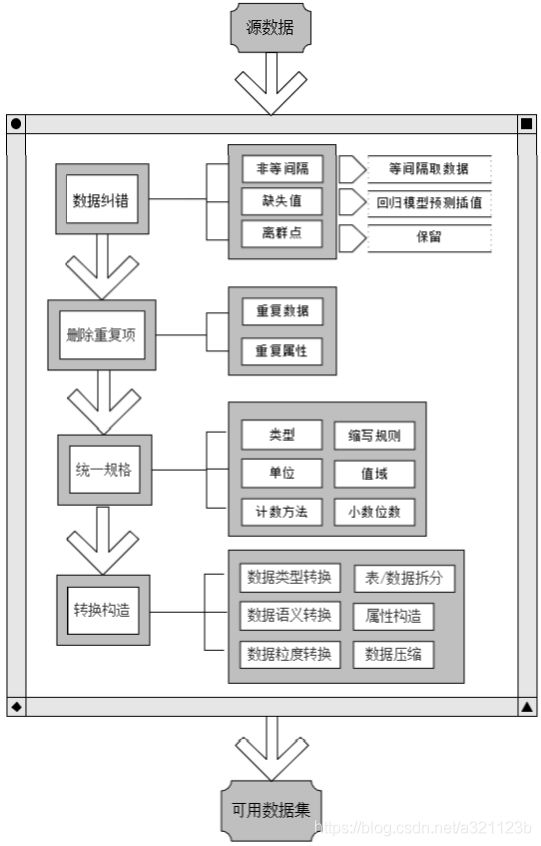
当数据质量校验完成后,针对有问题的数据要进行的是数据清洗和转换,另外还包括对正常数据的转换。数据清洗的主要作用包括:纠正错误、删除重复项、统一规格、转换构造。
一、纠正错误
错误数据是数据源环境中经常出现的一类问题。数据错误的形式包括:
数据值错误: 数据直接是错误的,例如超过固定域集、超过极值、拼写错误、属性错误、源错误等。
数据类型错误: 数据的存储类型不符合实际情况,如日期类型的以数值型存储,时间戳存为字符串等。
数据编码错误: 数据存储的编码错误,例如将UTF-8写成UTF-80。
数据格式错误: 数据的存储格式问题,如半角全角字符、中英文字符等。
数据异常错误: 如数值数据输成全角数字字符、字符串数据后面有一个回车操作、日期越界、数据前后有不可见字符等。
依赖冲突: 某些数据字段间存储依赖关系,例如城市与邮政编码应该满足对应关系,但可能存在二者不匹配的问题。
多值错误: 大多数情况下,每个字段存储的是单个值,但也存在一个字段存储多个值的情况,其中有些可能是不符合实际业务规则的。这类错误产生的原因是业务系统不够健全,尤其是在数据产生之初的校验和入库规则不规范,导致在接收输入后没有进行判断或无法检测而直接写入后台数据库造成的。
具体示例:
1.处理非等间隔
处理非等间隔时间序列的方法有两类,一类是内插法,最常用的是线性内插法。然而内插法往往会带来显著的且不易量化的偏差,因为分析拟合误差时往往不能区分哪些是模型本身带来的误差,哪些是由于内插带来的误差。另一类是直接对数据建模,例如可以把处理等间隔时间序列方法通过某种变换再应用之,或者直接考虑新的适用于非等间隔序列的模型。
2.处理缺失值
常见的方法有两种,一种是直接丢弃含缺失数据的记录;另一种是用新值替代缺失数据。实际中,后者的处理方式更常用,因为前者对数据分析而言是很大的浪费。用新值替代缺失值的常见方法有如下几种:
1)替代法: 可考虑用该序列中已观测序列值的均值替代;或最近邻域替代法,即设t时刻的序列值缺失,而已观测到t-1时刻的序列值 x t − 1 x_{t-1} xt−1,则寻找整个序列中与 x t − 1 x_{t-1} xt−1最接近的观测值x且其后一时刻 x s + 1 x_{s+1} xs+1非缺失,则可用 x s + 1 x_{s+1} xs+1替代t时刻的序列值。
2)内插法: 线性内插法,即根据两个时刻的观测值内插得到这两个时刻之间的时刻的序贯估计值。例如,设某一天的温度序列中,一点钟的气温为20℃,三点钟时为14℃,可以用线性内插法推测一点半及两点钟时的气温分别是18。5℃及17℃;K-最近距离法,即根据欧式距离或相关分析选取离缺失值最近的K个已观测序列值,将这K个值按照距离长度加权平均来估计该样本的缺失数据。
3)统计模型: 即通过一些建模方法获得缺失处的预测值,常见的有样条法和回归模型法。样条法是通过对已观测序列值建立样条模型,如三阶样条、光滑样条等,从而预测出缺失值。回归模型包括一元线性回归和多元线性回归,即根据观测序列,构造出回归模型所需的自变量和因变量,从而得到自变量与因变量之间的关系,并得到缺失处的预测值。
4)多重插补: 其思想来源于贝叶斯估计,认为待插补的值是随机的。实际中,通常先估计出待插补的值,然后再加上不同的噪声,形成多组可选插补值;对每个插补数据集合,都用针对完整数据集的统计方法进行统计分析,从而得到不同的结果;并根据评分函数进行选择,产生最终的插补值。
以上四种插补方法,均值替代法是最容易实现的,也是以前人们经常使用的,但是它对样本存在极大的干扰,尤其是当插补后的值作为解释变量进行回归时,参数的估计值与真实值的偏差很大。实践证明,线性内插法等直观方法所产生的结果也并不理想。回归模型往往效果不错,即用已有数据作为训练样本来建立预测模型,预测缺失数据。该方法最大限度地利用已知的相关数据,是比较流行的缺失数据处理技术。此外,多重插补法综合比较其他各种处理方法,并得到在某种评分准则下最优的处理方法,故应用较多。
除了上述处理方法之外,还有基于EM算法的替代模型,最大似然估计,外推法如增长量推算法、发展速度推算法、比例推算法等方法。
3.处理离群点
离群点(Outlier)是指一个时间序列中,远离序列一般水平的极端大值和极端小值。
离群点可分为四种类型:
1)加性离群点: 该干扰只影响发生的那一个时刻t时的序列值而不影响该时刻以后的序列值;
2)更新离群点: 造成离群点的干扰不仅作用于Xt,且影响t时刻以后序列的所有观测值;
3)水平移位离群点: 造成这种离群点的干扰是在某一时刻t系统的结构发生了变化,并持续影响t时刻以后的所有观测值,在数列上往往表现出t时刻前后的序列均值发生水平位移;
4)暂时变更离群点: 造成这种离群点的干扰是在t时刻干扰发生时具有一定初始效应,以后随时间根据衰减因子的大小呈指数衰减。
离群点常见的检测方法
1.将序列值与平滑值(时间序列的平滑方法可百度/谷歌自查)进行比较,根据差异,结合相应的评价准则检验其是否显著大(或小)。这种方法比较简单,但对于判断离群点的类型存在着不足。
2.干预分析法,其思想是,首先根据数据建立模型,利用拟合模型的残差序列计算特定的统计量,测出显著的离群点及其类型,并用所建立的模型对离群点进行修正,然后用修正后的时间序列再建立模型,重复上面的工作方法。
3.检测序列值与其相应的时间序列平滑估计值的绝对离差是否大于某预先设定的值。
离群点处理方法
若是离群点正是我们所关心的信息,直接提取出来并加以分析;若离群点不是我们所希望见到的,可以考虑把离群点光滑化,即用某些值替代离群点,然后再对处理后的时间序列进行分析。
二、 删除重复项
由于各种原因,数据中可能存在重复记录或重复字段(列),对于这些重复项目(行和列)需要做去重处理。
对于重复项的判断,基本思想是“排序和合并”,先将数据库中的记录按一定规则排序,然后通过比较邻近记录是否相似来检测记录是否重复。这里面其实包含了两个操作,一是排序,二是计算相似度。
常见的排序算法:插入排序、冒泡排序、选择排序、快速排序、堆排序、归并排序、基数排序、希尔排序。
常见的判断相似度的算法:基本的字段匹配算法标准化欧氏距离、汉明距离、夹角余弦、杰卡德距离、马氏距离、曼哈顿距离、闵可夫斯基距离、欧氏距离、切比雪夫距离、相关系数、信息熵。
对于重复的数据项,尽量需要经过业务确认并进行整理提取出规则。在清洗转换阶段,对于重复数据项尽量不要轻易做出删除决策,尤其不能将重要的或有业务意义的数据过滤掉,校验和重复确认的工作必不可少。
三、统一规格
由于数据源系统分散在各个业务线,不同业务线对于数据的要求、理解和规格不同,导致对于同一数据对象描述规格完全不同,因此在清洗过程中需要统一数据规格并将一致性的内容抽象出来。
数据字段的规则大致可以从以下几个方面进行统一:
名称: 对于同一个数据对象的名称首先应该是一致的。例如对于访问深度这个字段,可能的名称包括访问深度、人均页面浏览量、每访问PV数。
类型: 同一个数据对象的数据类型必须统一,且表示方法一致。例如普通日期的类型和时间戳的类型需要区分。
单位: 对于数值型字段,单位需要统一。例如万、十万、百万等单位度量。
格式: 在同一类型下,不同的表示格式也会产生差异。例如日期中的长日期、短日期、英文、中文、年月日制式和缩写等格式均不一样。
长度: 同一字段长度必须一致。
小数位数: 小数位数对于数值型字段尤为重要,尤其当数据量累积较大时会因为位数的不同而产生巨大偏差。
计数方法: 对于数值型等的千分位、科学计数法等的计数方法的统一。
缩写规则: 对于常用字段的缩写,例如单位、姓名、日期、月份等的统一。例如将周一表示为Monday还是Mon还是M。
值域:对于离散型和连续型的变量都应该根据业务规则进行统一的值域约束。
约束: 是否允许控制、唯一性、外键约束、主键等的统一。
统一数据规格的过程中,需要注意的一点是确认不同业务线带来数据的规格一致性,这需要业务部门的参与、讨论和确认,以明确不同体系数据的统一标准。
四、转换构造
数据变换是数据清理过程的重要步骤,是对数据的一个的标准的处理,几乎所有的数据处理过程都会涉及该步骤。数据转换常见的内容包括:数据类型转换、数据语义转换、数据值域转换、数据粒度转换、表/数据拆分、行列转换、数据离散化、提炼新字段、属性构造、数据压缩等。
1.数据类型转换
当数据来自不同数据源时,不同类型的数据源数据类型不兼容可能导致系统报错。这时需要将不同数据源的数据类型进行统一转换为一种兼容的数据类型。
2.数据语义转换
传统数据仓库中基于第三范式可能存在维度表、事实表等,此时在事实表中会有很多字段需要结合维度表才能进行语义上的解析。例如,假如字段M的业务含义是浏览器类型,其取值分为是1/2/3/4/5,这5个数字如果不加转换则很难理解为业务语言,更无法在后期被解读和应用。
3.数据粒度转换
业务系统一般存储的是明细数据,有些系统甚至存储的是基于时间戳的数据,而数据仓库中的数据是用来分析的,不需要非常明细的数据,一般情况下,会将业务系统数据按照数据仓库中不同的粒度需求进行聚合。
4.表/数据拆分
某些字段可能存储多中数据信息,例如时间戳中包含了年、月、日、小时、分、秒等信息,有些规则中需要将其中部分或者全部时间属性进行拆分,以此来满足多粒度下的数据聚合需求。同样的,一个表内的多个字段,也可能存在表字段拆分的情况。
5.行列转换
某些情况下,表内的行列数据会需要进行转换(又称为转置),例如协同过滤的计算之前,user和term之间的关系即互为行列并且可相互转换,可用来满足基于项目和基于用户的相似度推荐计算。
6.数据离散化
将连续取值的属性离散化成若干区间,来帮助消减一个连续属性的取值个数。例如对于收入这个字段,为了便于做统计,根据业务经验可能分为几个不同的区间:0~3000、3001~5000、5001~10000、10001~30000、大于30000,或者在此基础上分别用1、2、3、4、5来表示。
7.数据标准化
不同字段间由于字段本身的业务含义不同,有些时间需要消除变量之间不同数量级造成的数值之间的悬殊差异。例如将销售额进行离散化处理,以消除不同销售额之间由于量级关系导致的无法进行多列的复合计算。数据标准化过程还可以用来解决个别数值较高的属性对聚类结果的影响。
8.提炼新字段
很多情况下,需要基于业务规则提取新的字段,这些字段也称为复合字段。这些字段通常都是基于单一字段产生,但需要进行复合运算甚至复杂算法模型才能得到新的指标。
9.属性构造
有些建模过程中,也会需要根据已有的属性集构造新的属性。例如,几乎所有的机器学习都会讲样本分为训练集、测试集、验证集三类,那么数据集的分类(或者叫分区)就属于需要新构建的属性,用户做机器学习不同阶段的样本使用。
数据预处理-特征选择
一、基于Filter的
1.方差选择法
使用方差选择法,先要计算各个特征的方差,然后根据阈值,选择方差大于阈值的特征。
2.相关系数法
使用相关系数法,先要计算各个特征对目标值的相关系数以及相关系数的P值。
3.卡方检验
经典的卡方检验是检验定性自变量对定性因变量的相关性。假设自变量有N种取值,因变量有M种取值,考虑自变量等于i且因变量等于j的样本频数的观察值与期望的差距,构建统计量:
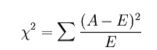
不难发现,这个统计量的含义简而言之就是自变量对因变量的相关性。
4.互信息法
经典的互信息也是评价定性自变量对定性因变量的相关性的,互信息计算公式如下:
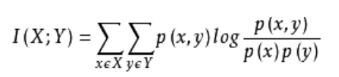
二、基于Wrapper的
递归特征消除法
递归消除特征法使用一个基模型来进行多轮训练,每轮训练后,消除若干权值系数的特征,再基于新的特征集进行下一轮训练。
三、基于Embedded的
基于惩罚项的特征选择法
使用带惩罚项的基模型,除了筛选出特征外,同时也进行了降维。如LASSO:Least Absolute Shrinkage and Selection Operator 最小绝对收缩和选择算子。
基于树模型的特征选择法
树模型中的GBDT也可用来作为基模型进行特征选择。
数据预处理-降维
主成分分析法(PCA)和线性判别分析(LDA),线性判别分析本身也是一个分类模型。PCA和LDA有很多的相似点,其本质是要将原始的样本映射到维度更低的样本空间中,但是PCA和LDA的映射目标不一样:PCA是为了让映射后的样本具有最大的发散性;而LDA是为了让映射后的样本有最好的分类性能。所以说PCA是一种无监督的降维方法,而LDA是一种有监督的降维方法。
数据预处理-归一化处理
数据归一化是对所有维度的数据进行数值上缩放到统一的固定区间,不同维度上的数据具有不同范围的数据将会导致模型收敛很慢甚至很难收敛。常用归一化方法主要为 Min-Max 和 Z-score。
Min-Max 也被称为离差标准化,是对原有数据的线性变换,使得数据被缩放至[0,1]区间,其变换公式为: x ^ = x − x min x max − x min \widehat{x}=\dfrac{x-x_{\min }}{x_{\max }-x_{\min }} x =xmax−xminx−xmin 。
Z-score 则利用原始数据的均值和方差进行放缩: x ^ = x − μ σ \widehat{x}=\dfrac{x-\mu }{\sigma } x =σx−μ,归一化后的数据将符合标准正态分布,同时消除数据量纲对建模的影响。
数据预处理-划分窗口
划分窗口是将数据集按照时间步长进行划分,同时也意味着模型根据一个窗口长度的历史数据信息进行预测。
数据预处理-Shuffle与数据集划分
Shuffle 阶段是打乱上一步骤划分滑动窗口的输出序列,而数据集化分则将原始数据集大小按照 10%,10%,20%进行划分,其中训练集数据量占原始数据的 80%,验证集占10%用于调整模型参数,最后测试集占10%用于评估模型性能。
学识浅薄,欢迎指正补充。