基于ARIMA对我国居民消费价格指数的分析
1.数据收集
根据分析所需内容,搜集以下数据:
2015年到2018年cpi指数月度数据
(数据来源:中经网统计数据库)
2.数据整理
将以上数据整理成表:
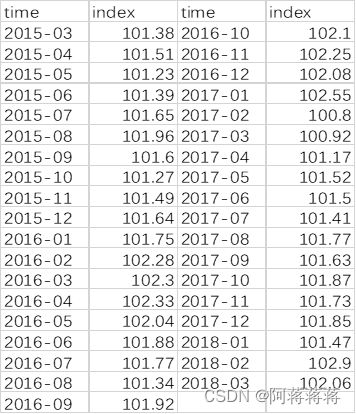
3.时间序列对象
本数据分析将使用R stdio 3.4.4。
4. .绘制时间序列图
4.1.1.平稳性检验
(一)绘制原始GDP序列的时序图
(1)编程
| > da<-read.xlsx("C:/Users/26259/Documents/R/da.xlsx") > dim(da) [1] 37 2 > head(da) year index 1 2015-03 101.38 2 2015-04 101.51 3 2015-05 101.23 4 2015-06 101.39 5 2015-07 101.65 6 2015-08 101.96 > index=log(da$index+1) > rtn=ts(index,frequency = 12,start = c(2015,3))(时间刻度) > plot(rtn,xlab='year',ylab='ln-rtn') |
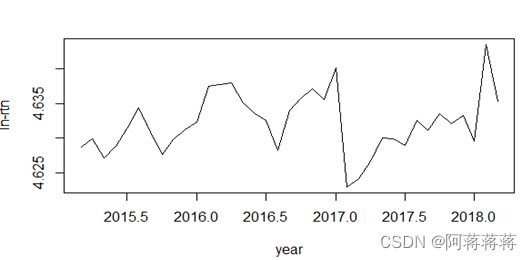
从图中可以看出居民消费价格指数具有明显的单调递增趋势,可以初步判断为非平稳序列。
(二)自相关性检验
(1)编程
acf(index,lag.max = 30)
> t.test(index)
One Sample t-test
data: index
t = 6563.6, df = 36, p-value < 2.2e-16
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
4.630743 4.633605
sample estimates:
mean of x
4.632174
(2)输出结果
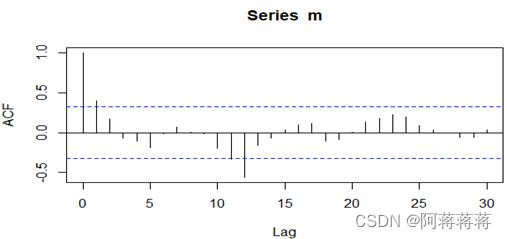
自相关图显示自相关系数长期大于零,T检验的p值显著小于0.05,说明序列间具有很强的长期相关性,可以判断为非平稳序列。
(三)单位根检验
| (1)编程 > > library(fUnitRoots) 载入需要的程辑包:timeDate 载入需要的程辑包:timeSeries 载入需要的程辑包:fBasics > unitrootTest(index) Title: Augmented Dickey-Fuller Test Test Results: PARAMETER: Lag Order: 1 STATISTIC: DF: 0.4131 P VALUE: t: 0.7972 n: 0.7802 可以看出单位根检验统计量对应的P值0.7972显著大于0.05,判断该序列为非平稳序列(非平稳序列一定不是白噪声序列)。 4.1.1.2.ln(cpi)的平稳性检验 对cpi进行对数化处理,绘制ln(cpi)时序图、自相关图以及进行单位根检验。 (1)编程 > m=log(index) > plot.ts(m,xlab="时间", ylab="lncpi") > acf(m,lag.max = 30) > unitrootTest(m)
自相关图显示自相关系数长期大于零,说明序列间具有很强的长期相关性,可以判断ln(cpi)为非平稳序列。 |
(2)输出结果
Title:
Augmented Dickey-Fuller Test
Test Results:
PARAMETER:
Lag Order: 1
STATISTIC:
DF: 0.4134
P VALUE:
t: 0.7973
n: 0.7803
可以看出单位根检验统计量对应的P值0.7973显著大于0.05,判断ln(cpi)序列为非平稳序列。
接下来对ln(cpi)数据进行一阶差分,并验证其平稳性。
4.1.2.平稳化处理
(1)编程
> difm=diff(m)
> plot.ts(difm,xlab="时间", ylab="ln(cpi)一阶差分")
> acf(difm,lag.max=30)
> unitrootTest(difm)
(2)输出结果
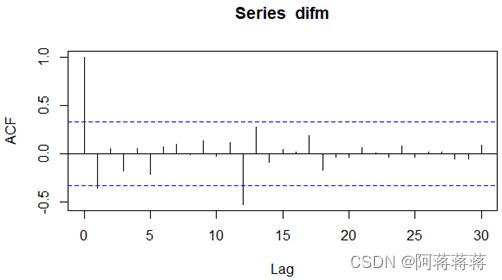

自相关图有很强的短期相关性。
Title:
Augmented Dickey-Fuller Test
Test Results:
PARAMETER:
Lag Order: 1
STATISTIC:
DF: -4.6384
P VALUE:
t: 2.804e-05
n: 0.1256
可以看出单位根检验统计量对应的P值小于0.05,所以一阶差分后的ln(cpi)序列是平稳序列。
4.2.时间序列模型的建立
4.2.1.m1模型
> library(TSA)
> acf(diflncpi,lag.max=30)
> pacf(diflncpi,lag.max=30)
> m1 <- arima(difm,order=c(1,1,0), seasonal=list(order=c(0,1,1), period=4))
> m1
Call:
arima(x = difm, order = c(1, 1, 0), seasonal = list(order = c(0, 1, 1), period = 4))
Coefficients:
ar1 sma1
-0.8013 -0.9991
s.e. 0.1627 0.4812
sigma^2 estimated as 1.636e-06: log likelihood = 158.15, aic = -312.29
可以考虑用ARIMA模型拟合一阶差分后的序列,即对原始序列建立ARIMA(1,1,0)模型,为模型m1,如下:
输出结果显示,序列ln(cpi)的模型一为ARIMA(1,1,0),即下式:
(1+0.80138B)(Xt-Xt-1)=(1+0.999B12)at
4.2.2. m2模型
(1)编程(续上)
> library(TSA)
> acf(diflncpi,lag.max=30)
> pacf(diflncpi,lag.max=30)
| > m2 <- arima(difm,order=c(12,1,0), seasonal=list(order=c(0,1,1), period=4)) > m2 |
(2)输出结果
Call:
arima(x = difm, order = c(12, 1, 0), seasonal = list(order = c(0, 1, 1), period = 4))
Coefficients:
ar1 ar2 ar3 ar4 ar5 ar6 ar7 ar8 ar9 ar10
-1.2376 -1.1499 -1.1840 -1.3368 -1.3927 -0.9996 -0.6678 -0.5013 -0.3648 -0.0047
s.e. 0.2088 0.3297 0.4289 0.5765 0.6778 0.7227 0.7245 0.6739 0.6041 0.5169
ar11 ar12 sma1
0.3583 0.0081 -0.3313
s.e. 0.3838 0.2515 0.4379
sigma^2 estimated as 7.178e-07: log likelihood = 170.43, aic = -314.85
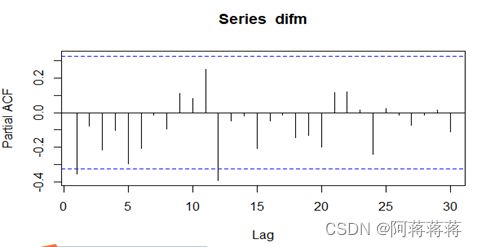

由图可以看出,在一阶差分之后序列的自相关图中,ACF值在二阶之后迅速跌入置信区间,并且数值徘徊在置信区间,没有收敛趋势,显示出拖尾性。
可以看出,在一阶差分之后序列的偏自相关图中,PACF值在一阶之后迅速跌入置信区间,并且数值徘徊在置信区间,没有收敛趋势,显示出拖尾性。所以可以考虑用ARIMA模型拟合一阶差分后的序列,即对原始序列建立ARIMA(12,1,0)模型,为模型m2,如下:
输出结果显示,序列ln(cpi)的模型一为ARIMA(12,1,0),即下式:
(1+1.238B)(Xt-Xt-1)=(1+0.34B12)at
4.2.3模型比较
(1)编程
> Box.test(m1$residuals,lag=12,type = "Ljung-Box")
> Box.test(m2$residuals,lag=12,type = "Ljung-Box")
(2)输出结果
Box-Ljung test
data: m2$residuals
X-squared = 2.2381, df = 12, p-value = 0.9989
p-value=0.9989>0.05,说明残差为白噪声序列,通过白噪声检验。
Box-Ljung test
data: m1$residuals
X-squared = 19.677, df = 12, p-value = 0.07346
p-value=0.073>0.05,说明残差为白噪声序列,通过白噪声检验。
通过比较发现,针对本文所研究的数据,m1和m2模型均拟合良好,但模型m2更可靠,更具有说服力。
4.2.4模型的预测
(1)编程
> forecast(m)
(2)输出结果
Point Forecast Lo 80 Hi 80 Lo 95 Hi 95
38 1.533869 1.532674 1.535063 1.532042 1.535696
39 1.533869 1.532560 1.535178 1.531867 1.535871
40 1.533869 1.532455 1.535283 1.531706 1.536032
41 1.533869 1.532357 1.535381 1.531556 1.536182
42 1.533869 1.532265 1.535473 1.531415 1.536323
43 1.533869 1.532178 1.535560 1.531282 1.536456
44 1.533869 1.532095 1.535643 1.531156 1.536582
45 1.533869 1.532016 1.535722 1.531035 1.536703
46 1.533869 1.531940 1.535798 1.530919 1.536819
47 1.533869 1.531867 1.535871 1.530807 1.536931
从预测结果可以看出未来五年cpizz指数将处于上升趋势,但cpi受外汇储备量、人民币汇率、金融机构贷款额等诸多因素影响,为使cpi未来五年保持平稳趋势,需积极稳妥推进价格改革.
4.2.5模型总结
基于时间序列建立的ARIMA模型的预测在本质上是利用时间推动下经济现象的发展变化,来延伸出社会经济发展的一般规律性,并预测经济现象的未来趋势。本文整个的分析过程是在原有数据基础上,对其进行转换,进行平稳性检验,消除非平稳性,找到合适的ARIMA模型拟合数据,在将不确定因素控制在合理范围内的前提下,建立一个时间序列的ARIMA模型,然后计算出序列的短期区间预测与点预测。
模型优缺点
优点:ARIMA模型在对许多时间序列都适用,并且在建模过程中有多种方法可以选择,并且在模型的诊断中能过对模型的好坏进行评价,对预测起到很好的作用。
缺点:ARIMA模型对数据进行预测时,对短期预测效果还是比较好的,但随着时间的延长,其预测误差就比较大了。