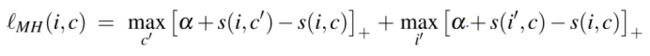文献阅读-VSE++:使用困难负样本来改经视觉语义嵌入
Title:《VSE++: Improving Visual-Semantic Embeddings with Hard Negatives》
| Authors:Fartash FaghriDavid FleetJ. KirosS. Fidler |
| Journal:ArXiv (2017) |
| Date:2017 |
code:GitHub - fartashf/vsepp: PyTorch Code for the paper "VSE++: Improving Visual-Semantic Embeddings with Hard Negatives"
 这篇文章主要针对困难负样本提出一种新的损失函数,并再次基础上做出实验。
这篇文章主要针对困难负样本提出一种新的损失函数,并再次基础上做出实验。
Abstract: 我们提出了一种学习视觉语义嵌入以进行跨模态检索的新技术。 受 hard negative mining、hard negatives 在结构化预测中的使用以及对损失函数进行排序的启发,我们对用于多模态嵌入的常见损失函数进行了简单的更改。 结合微调和增强数据的使用,可以显着提高检索性能。 我们在 MS-COCO 和 Flickr30K 数据集上展示了我们的方法 VSE++,使用消融研究和与现有方法的比较。 在 MS-COCO 上,我们的方法在字幕检索方面比最先进的方法高出 8.8%,在图像检索方面高出 11.3%(在 R@1)。
 hard negative:是指loss比较大,容易将负样本看成正样本的那些样本
hard negative:是指loss比较大,容易将负样本看成正样本的那些样本
创新点:本文侧重于学习视觉语义嵌入仪进行跨模态图像字幕检索,提出一种新的损失:MH损失,基于相对的困难负样本引起的违规。此改进的损失可以更好地指导更强大的图像编码器ResNet152,并且在微调图像编码器时也能更好的指导。
1. 引言
联合嵌入支持图像、视频和语言理解方面的广泛任务。 示例包括用于形状推理的形状图像嵌入、双语词嵌入、用于 3D 姿势推理的人体姿势图像嵌入、细粒度识别、零 -shot 学习 ,以及通过合成进行模态转换 。 这种嵌入需要从两个(或更多)域映射到一个公共向量空间,在该空间中语义相关的输入(例如,文本和图像)被映射到相似的位置。 因此,嵌入空间表示底层域结构,其中位置和方向通常具有语义意义。
视觉语义嵌入一直是图像标题检索和生成以及视觉问答的核心。
例如,视觉问答的一种方法是首先通过一组说明描述图像,然后找到最近的说明来回答问题。
对于文本的图像合成,可以从文本映射到联合嵌入空间,然后再映射回图像空间 。
跨模态检索的视觉语义嵌入:
- 检索给定标题的图像
- 查询图像的标题
性能指标:R@K,是指在k出的召回率,更具体的来说就是,在与嵌入空间中查询最近k点中检索到正确项的查询比例。
排序: 正确的目标应该比语料库中的其他项目更接近查询,这与学习排序问题和 maxmargin 结构化预测 不同。 本文中的公式和模型架构与中的公式和模型架构最密切相关,通过三元组排序损失学习。 与这项工作相比,提倡一种新的损失、增强数据的使用和微调,它们共同产生了字幕检索性能的显着提高,超过了众所周知的基准数据上的基线排名损失。 我们比 MS-COCO 上报告的最佳结果高出近 9%。 同时表明,使用本文更强的损失函数可以放大具有微调功能的更强大图像编码器的优势。 本文的模型称为 VSE++。
在损失函数中加入了 hard negatives,使用 hard negative mining 最小化损失函数等同于使用均匀采样最小化修改后的非透明损失函数。 我们通过在多模态嵌入的损失中显式引入 hard negatives 来扩展这个想法,而无需任何额外的挖掘成本。
2. 学习视觉语义嵌入
跨模态检索中:
- 查询标题,任务是从数据库中检索最相关的图像
- 查询图像:任务是检索相关标题
- 目标是最大化 K (R@K) 的召回率,即最相关项目在返回的前 K 个项目中排名的查询分数。
图像字幕对训练集![]()
其中正样本对为![]()
负样本对为![]()
意思是图像![]() 与字幕
与字幕 是最相关的。
是最相关的。
定义相似度函数为 ,给正样本对比负样本对给出更高的相似度分数。
,给正样本对比负样本对给出更高的相似度分数。
2.1 视觉语义嵌入
从图像 计算的基于特征表示
计算的基于特征表示![]()
例如VGG19或ResNet152
字幕嵌入中字幕 的基于特征表示
的基于特征表示![]()
例如基于 GRU 的文本编码器
这里,θφ 和 θψ 表示到这些初始图像和字幕表示的相应映射的模型参数。
联合嵌入空间的映射由线性投影定义 :
其中![]() 和
和![]()
我们进一步规范化![]()
使其位于单位超球面(unit hypersphere)上,因为当类被很好的聚集在一起时,他是线性可分离的。
最后,我们将联合嵌入空间中的相似度函数定义为通常的内积:
其中 为参数模型,如果我们也微调图像编码器,那么我们也会在 θ 中包含 θφ 。
为参数模型,如果我们也微调图像编码器,那么我们也会在 θ 中包含 θφ 。
训练需要最小化关于 θ 的经验损失,即训练数据 的累积损失:
的累积损失:
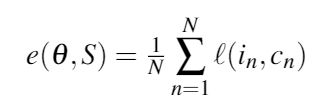
其中 是适合单个训练样本的损失函数,受使用三元组损失进行图像检索的启发,最近联合视觉语义嵌入的方法使用了基于铰链的三元组排序损失(本文基于此损失函数) :
是适合单个训练样本的损失函数,受使用三元组损失进行图像检索的启发,最近联合视觉语义嵌入的方法使用了基于铰链的三元组排序损失(本文基于此损失函数) :
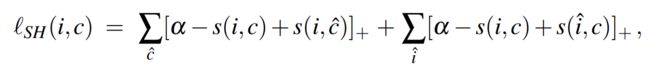
其中 ![]() 作为边距参数,
作为边距参数,![]() 。
。
该铰链损失包括两个对称项。
- 给定查询图像i,第一个总和用于所有的负样本标题
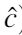
- 给定标题c,第二个总和用于所有样本图像

每一项都与负样本集的预期损失(或违规)成比例
如果和在联合嵌入空间中彼此之间得到距离比任何负值都更接近,则在边缘 ![]()
处,铰链损失为0.
为了计算效率,只对小批量随机梯度下降中的负数求和(或者随机抽样) 。
当然还有其他的损失函数可以考虑。
- 一种是成对铰链损失,其中鼓励正对的元素位于联合嵌入空间中半径为 ρ1 的超球体内,而负对的元素不应小于 ρ2 > ρ1。 这是有问题的,因为它比排名损失更多地限制了潜在空间的结构,并且它需要使用两个很难设置的超参数。
- 另一种可能的方法是使用典型相关分析来学习 Wf 和 Wg,从而尝试在联合嵌入中保持文本和图像之间的相关性。 相比之下,当用 R@K 衡量性能时,对于小 K,基于相关性的损失不会对负项在正对局部附近的嵌入产生足够的影响,这对 R@K 至关重要。
2.2 对于困难负样本的强调
受结构化预测中使用的常见损失函数的启发,我们专注于训练的困难负样本,即最接近每个训练查询的负样本。 这与检索特别相关,因为根据 R@1 衡量,它是决定成功或失败的最难负样本。
给定正样本对![]() ,最困难负样本
,最困难负样本![]()
和![]()
为了强调 hard negatives,我们将损失定义为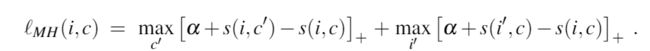
- 与SH损失函数一样,这种损失包括两项,一项以 i 和一项以 c 作为查询。
- 与SH损失函数不同的是。 这种损失是根据最难的负数 c' 和 i' 指定的。
从 SH 损失到 MH 损失有一系列损失函数。 在 MH 损失中,获胜者采用所有梯度,而我们使用所有三元组的重新加权梯度。 我们只讨论 MH 损失,因为根据经验发现它表现最好。
MH 损失优于 SH 的一种情况是,多个负数和小违规联合起来支配 SH 损失。
 图 1:典型正对和最近的负样本的图示。 这里假设相似度得分是负距离。 实心圆圈表示正对 (i, c),而空心圆圈表示查询 i 的负样本。 两侧的虚线圆圈以相同的半径绘制。 请注意,最难的负样本 c' 在 (a) 中更接近 i。 假设边缘为零,与 (a) 相比,(b) 的 SH 损失更高。 MH 损失为 (a) 分配了更高的损失。
图 1:典型正对和最近的负样本的图示。 这里假设相似度得分是负距离。 实心圆圈表示正对 (i, c),而空心圆圈表示查询 i 的负样本。 两侧的虚线圆圈以相同的半径绘制。 请注意,最难的负样本 c' 在 (a) 中更接近 i。 假设边缘为零,与 (a) 相比,(b) 的 SH 损失更高。 MH 损失为 (a) 分配了更高的损失。
- SH:Sum of Hinges loss 铰链总和损失
- MH:Max of Hinges loss 最大铰链损失
例如,图 1 描绘了正对和两组负数。 在图 1(a) 中,单个负样本太靠近查询,这可能需要对映射进行重大更改。 然而,任何将 hard negative 推开的训练步骤都可能会导致一些小的违规 negatives,如图 1(b) 所示。 使用 SH 损失,这些“新”负值可能会主导损失,因此模型被推回到图 1(a) 中的第一个示例。 这可能会在 SH 损失中产生局部最小值,这对于 MH 损失来说可能没有那么大的问题,而 MH 损失侧重于最难的负值。
为了提高计算效率,我们不是在整个训练集中寻找最难的负样本,而是在每个小批量中找到它们。 这与 SH 损失的复杂度具有相同的二次复杂度。 通过对小批量进行随机抽样,这种近似产生了其他优势。 一是很可能得到比整个训练集至少 90% 更难的 hard negatives。 此外,损失对训练数据中的标签错误具有潜在的鲁棒性,因为在整个训练集中对最难的负样本进行采样的概率有点低。
2.3 采样最难的负样本的概率
图像文本对训练集 ,其中字幕集为
,其中字幕集为![]()
假设我们在小批量中抽取 M 个样本,![]() 在训练集S中。
在训练集S中。
令 C 上的排列 ![]() 指的是根据相似度函数
指的是根据相似度函数![]() 对字幕的排名,其中
对字幕的排名,其中![]() 。 我们可以假设排列 πm 是不相关的。
。 我们可以假设排列 πm 是不相关的。
给定一个查询图像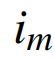 ,感兴趣的是在小批量中从 πm的第90个百分位中得到没有字幕的概率。
,感兴趣的是在小批量中从 πm的第90个百分位中得到没有字幕的概率。
假设 IID 样本,这个概率只是![]() ,即小批量中没有样本来自第 90 个百分位数的概率。 该概率趋于呈指数快速趋于零,当 M ≥ 44 时下降到 1% 以下。
,即小批量中没有样本来自第 90 个百分位数的概率。 该概率趋于呈指数快速趋于零,当 M ≥ 44 时下降到 1% 以下。
IID独立同分布。即假设训练数据和测试数据是满足相同分布的,它是通过训练数据获得的模型能够在测试集获得好的效果的一个基本保障。
因此,对于足够大的小批量,我们很有可能采样比整个训练集的 90% 都难的负样本字幕。 πm 第 99.9 个百分位数的概率趋于零的速度更慢; 对于 M ≥ 6905,它低于 1%,这是一个相对较大的 mini-batch。
虽然我们通过在小批量中随机抽取负样本来获得强信号,但这种抽样也为异常值提供了一些鲁棒性,例如与ground-truth字幕相比,负样本字幕可以更好地描述图像。 小至 128 的小批量可以提供足够强的训练信号和对标签错误的鲁棒性。 当然,通过增加 mini-batch 的大小,我们会得到更难的反例,并可能获得更强的训练信号。 然而,通过增加小批量大小,我们失去了 SGD 在寻找最佳最优值和利用梯度噪声方面的优势。 这可能导致陷入局部最优或如所观察到的那样,训练时间极长。
3. 实验
下面我们使用我们的方法 VSE++ 进行实验,将其与具有 SH 损失的基线公式(表示为 VSE0)和其他最先进的方法进行比较。 本质上,基线公式 VSE0 类似于 [15] 中的公式,表示为 UVS。
[15]Ryan Kiros, Ruslan Salakhutdinov, and Richard S Zemel. Unifying visual-semantic embeddings with multimodal neural language models. 2014.
Unifying visual-semantic embeddings with multimodal neural language models (2014)
我们用两个图像编码器进行实验:[28] 的 VGG19 和 [10] 的 ResNet152。 在下文中,除非另有说明,否则我们使用 VGG19。 与之前的工作一样,我们直接从倒数第二个全连接层 FC7 中提取图像特征。 图像嵌入的维数 Dφ 对于 VGG19 为 4096,对于 ResNet152 为 2048。
[10]Deep residual learning for image recognition
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2016)
Kaiming HeXiangyu ZhangShaoqing RenJian Sun
[28]Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large- scale image recognition. 2015.
Very deep convolutional networks for largescale image recognition (2015)
更详细地说,我们首先将图像大小调整为 256 × 256,然后使用大小为 224 × 224 的单个裁剪或具有相似大小的多个裁剪的特征向量的平均值。 我们将使用 1 个中心 crop 进行训练称为 1C,将在固定位置使用 10 个 crop 进行训练称为 10C。 这些图像特征可以预先计算一次并重复使用。 我们还尝试使用单个随机crop,用 RC 表示。 对于 RC,图像特征是动态计算的。 最近的作品大多使用RC/10C。 在我们的初步实验中,我们没有观察到 RC/10C 之间的显着差异。 因此,我们使用 RC 执行大多数实验。
对于字幕编码器,我们使用类似于 [15] 中使用的 GRU。 我们将 GRU 的维数 Dψ 和联合嵌入空间 D 设置为 1024。输入到 GRU 的词嵌入的维数设置为 300。
[15]Ryan Kiros, Ruslan Salakhutdinov, and Richard S Zemel. Unifying visual-semantic embeddings with multimodal neural language models. 2014.
Unifying visual-semantic embeddings with multimodal neural language models (2014)
我们进一步注意到,在 [15] 中,字幕嵌入是标准化的,而图像嵌入不是。 两个向量的归一化意味着相似度函数是余弦相似度。 在 VSE++ 中,我们对两个向量进行归一化。 不规范化图像嵌入会改变样本的重要性。 在我们的实验中,不规范化图像嵌入有助于基线 VSE0 找到更好的解决方案。 但是,VSE++ 不受此规范化的显着影响。
3.1 数据集
我们在 Microsoft COCO 数据集 ([21]) 和 Flickr30K 数据集 ([34]) 上评估我们的方法。 Flickr30K 有标准的 30, 000 张图像用于训练。 在 [13] 之后,我们使用 1000 张图像进行验证,使用 1000 张图像进行测试。 我们还对 MSCOCO 使用 [13] 的拆分。 在此拆分中,训练集包含 82、783 张图像、5000 张验证图像和 5000 张测试图像。 但是,也有 30, 504 张图像原本在 MS-COCO 的验证集中,但在这次拆分中被排除在外。 我们将这个集合称为 rV。 一些论文使用 rV 进行训练(总共 113、287 个训练图像)以进一步提高准确性。 我们使用两个训练集报告结果。 每张图片都附有 5 个说明文字。 通过平均超过 5 倍的 1K 测试图像或对完整的 5K 测试图像进行测试来报告结果。
[21]Microsoft coco: Common objects in context
European Conference on Computer Vision (ECCV) (2014)
Tsung-Yi LinMichael MaireSerge BelongieJames HaysPietro PeronaDeva RamananPiotr DollárC Lawrence Zitnick
[34]Peter Young, Alice Lai, Micah Hodosh, and Julia Hockenmaier. From image descrip- tions to visual denotations: New similarity metrics for semantic inference over event descriptions. 2:67-78, 2014.
From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions (2014)
3.2 训练细节
我们使用 Adam 优化器 [14]。 模型最多训练 30 个时期。 除了微调模型,我们开始以 0.0002 的学习率训练 15 个 epoch,然后将学习率降低到 0.00002 再训练 15 个 epoch。 通过使用固定图像编码器训练 30 个 epoch 的模型来训练微调模型,然后以 0.00002 的学习率对其进行 15 个 epoch 的训练。 对于大多数实验,我们将边距设置为 0.2。 我们在所有实验中使用 128 的小批量大小。 请注意,由于不同模型的训练集大小不同,因此每个时期的实际迭代次数可能会有所不同。 对于测试集的评估,我们通过选择在验证集上表现最佳的模型快照来解决过度拟合问题。 根据验证集上的召回总和选择最佳快照。
[14]Diederik Kingma and Jimmy Ba. Adam: A method for stochastic optimization. 2015.
Adam: A method for stochastic optimization (2015)
3.3 MS-COCO上的结果
MS-COCO 数据集的结果如表 1 所示。为了了解训练和算法变化的影响,我们报告了基线 VSE0 的消融研究(见表 2)。 我们使用 VSE++ 的最佳结果是通过使用 ResNet152 和微调图像编码器(第 1.11 行)实现的,我们看到 R@1 的字幕检索提高了 21.2%,与 UVS 相比,用于图像检索的 R@1 提高了 21%(第 1.1 和 1.11 行)。 请注意,使用 ResNet152 和微调使用 VSE0 公式(第 2.6 和 1.1 行)只能带来 12.6% 的改进,而我们的 MH 损失函数带来了 8.6% 的显着增益(第 1.11 和 2.6 行)。
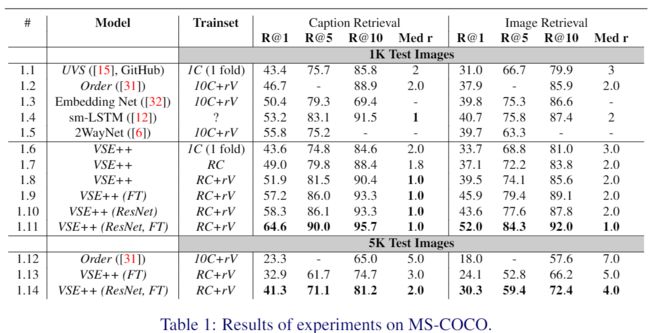
 表 2:数据扩充和微调的效果。 我们从表 1 中复制了 VSE++ 的相关结果,以便于进行比较。 请注意,应用所有修改后,R@1 的 VSE0 模型达到 56.0%,而 VSE++ 达到 64.6%。
表 2:数据扩充和微调的效果。 我们从表 1 中复制了 VSE++ 的相关结果,以便于进行比较。 请注意,应用所有修改后,R@1 的 VSE0 模型达到 56.0%,而 VSE++ 达到 64.6%。
将 VSE++(ResNet、FT)与 MS-COCO、2WayNet(第 1.11 行和第 1.5 行)上的当前最先进技术进行比较,我们看到 R@1 在字幕检索方面有 8.8% 的改进,并且与 sm-LSTM( 行 1.11 和行 1.4),图像检索提高了 11.3%。 我们还在第 1.13 和 1.14 行报告了 MS-COCO 完整 5K 测试集的结果。
训练集的效果。 我们通过逐步改进训练数据来比较 VSE0 和 VSE++。 比较在 1C 上训练的模型(第 1.1 和 1.6 行),我们仅看到 R@1 在图像检索方面有 2.7% 的改进,但在字幕检索性能方面没有改进。 然而,当我们使用 RC(第 1.7 和 2.2 行)或 RC+rV(第 1.8 和 2.3 行)进行训练时,我们看到与 VSE0 相比,VSE++ 在用于字幕检索的 R@1 中分别提高了 5.9% 和 5.1% . 这表明 VSE++ 可以更好地利用附加数据。
更好的图像编码效果。 我们还研究了更好的图像编码器对模型的影响。 第 1.9 行和第 2.4 行显示微调 VGG19 图像编码器的效果。 我们看到 VSE0 和 VSE++ 之间的差距增加到 6.1%。 如果我们使用 ResNet152 而不是 VGG19(第 1.10 行和第 2.5 行),则差距为 5.6%。 至于我们的最佳结果,如果我们使用 ResNet152 并微调图像编码器(第 1.11 行和第 2.6 行),差距变为 8.6%。 性能差距的增加表明,当使用更强大的图像编码器时,改进的 VSE++ 损失可以更好地指导优化。
3.4 Flickr30K上的结果
表 3 总结了 Flickr30K 上的性能。 我们在标题检索的 R@1 中获得了 23.1% 的改进,在图像检索中的 R@1 获得了 17.6% 的改进(第 3.1 和 3.17 行)。 我们观察到 VSE++ 在使用 1C 的预计算特征进行训练时会过度拟合。 原因可能是 Flickr30K 训练集的大小有限。 正如第二节中所解释的那样。 3.2,我们根据验证集的性能,在过拟合发生之前选择模型的快照。 使用 RC 训练数据训练模型时不会出现过拟合。 我们的结果表明,我们的 MH 损失带来的改进在数据集和模型中持续存在。
3.5 提升顺序嵌入
鉴于我们方法的简单性,我们提出的损失函数可以补充最近使用更复杂的模型架构或相似性函数的方法。 在这里,我们通过将 MH 损失应用于另一种称为顺序嵌入的联合嵌入方法来证明 MH 损失的好处 [31]。
[31]Ivan Vendrov, Ryan Kiros, Sanja Fidler, and Raquel Urtasun. Order-embeddings of images and language. 2016.
Order-embeddings of images and language (2016)
与上述公式的主要区别在于使用了非对称相似函数,即 ![]() . 同样,我们只是用我们的 MH 损失替换他们对 SH 损失的使用。
. 同样,我们只是用我们的 MH 损失替换他们对 SH 损失的使用。
和他们的实验设置一样,我们使用训练集 10C+rV。 对于我们的 Order++,我们使用与其他实验相同的学习计划和边际。 但是,我们使用他们的训练设置来训练 Order0。 我们以 0.001 的学习率开始训练 15 个时期,然后将学习率降低到 0.0001 再过 15 个时期。 与 [31] 一样,我们使用 0.05 的边距。 此外,[31] 在计算我们仅为 Order0 复制的相似性函数之前采用嵌入的绝对值。
表 4 报告了将 SH 损失替换为 MH 损失时的结果。 我们使用我们的 Order0 公式复制他们的结果并获得稍微更好的结果(第 4.1 行和第 4.3 行)。 我们观察到在 R@1 中从 Order0 到 Order++ 的标题检索有 4.5% 的改进(第 4.3 行和第 4.5 行)。 与从 VSE0 到 VSE++ 的改进相比,10C+rV 训练集的改进为 1.8%,我们在这里获得了更高的改进。 这表明 MH 损失可以潜在地改进用于检索和排序任务的许多类似损失函数。

3.6 损失函数的行为
我们观察到 MH 损失可能需要几个时期才能在训练期间“预热”。 图 2 使用 RC 描述了 Flickr30K 数据集上的这种行为。 请注意,SH 损失开始得更快,但在大约 5 个 epoch 后,MH 损失超过了 SH 损失。 为了解释这一点,与 SH 损失相比,MH 损失取决于一组较小的三元组。 在训练早期,MH 损失的梯度受一组相对较小的三元组的影响。 因此,可能需要更多的迭代来训练具有 MH 损失的模型。 我们探索了一种简单的课程学习形式 ([2]) 来加速训练。 我们开始使用 SH 损失进行几个 epoch 的训练,然后在剩余的训练中切换到 MH 损失。 然而,它的表现并不比仅使用 MH 损失进行训练好多少。 图 2:使用 RC 对 Flickr30K 数据集训练的 MH 损失行为进行分析。 该图比较了 SH 损失与 MH 损失(表 3,第 3.9 行和第 3.11 行)。 请注意,在前 5 个 epoch 中,SH 损失获得了更好的性能,然而,从那里开始,MH 损失导致更高的召回率。
图 2:使用 RC 对 Flickr30K 数据集训练的 MH 损失行为进行分析。 该图比较了 SH 损失与 MH 损失(表 3,第 3.9 行和第 3.11 行)。 请注意,在前 5 个 epoch 中,SH 损失获得了更好的性能,然而,从那里开始,MH 损失导致更高的召回率。
在 [27] 中,据报道,对于 1800 的小批量,训练非常慢。 我们在高达 512 的大型小批量中遇到了类似的行为。但是,大小为 128 或 256 的小批量在相同的训练时间内超过了 SH 损失的性能。
[27]Facenet: A unified embedding for face recognition and clustering
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2015)
Florian SchroffDmitry KalenichenkoJames Philbin

 图 3:根据经过训练的 VSE++ 模型的损失,来自 Flickr30K 训练集的示例及其在随机小批量中的硬否定。 括号中的值是 hard negative 的成本,在我们的实现中处于 [0, 2] 范围内。 HN 是大小为 128 的随机样本中最难的负样本。GT 是用于计算 NG 成本的正样本。
图 3:根据经过训练的 VSE++ 模型的损失,来自 Flickr30K 训练集的示例及其在随机小批量中的硬否定。 括号中的值是 hard negative 的成本,在我们的实现中处于 [0, 2] 范围内。 HN 是大小为 128 的随机样本中最难的负样本。GT 是用于计算 NG 成本的正样本。
总结:
VSE++是基于排序的经典方法。基于排序的是主要利用排序损失使得公共空间中配对的样本距离小,不成对样本距离大。该类方法通常以三元组
sum hinge loss:
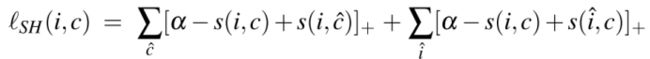
Max hinge loss: