R-CNN:Region-based convolutional networks for accurate object detection and segmentation阅读笔记
Region-based convolutionalnetworks for accurate object detection and segmentation(2016.PAMI)
Ross Girshick, Jeff Donahue, TrevorDarrell, Jitendra Malik
一、摘要
目标检测最近这几年在PASCAL VOC挑战赛上的表现达到相对稳定,表现最好的方法是那些将低层次的图像特征和高层次是上下文信息结合起来的复杂的集成系统。这篇论文提出了一种简单可扩展的算法,相对于先前在VOC 2012上表现最好的算法mAP提高了超过50%——mAP达到了62.4%。本文的方法组合了两个想法:(1)将高容量的CNN应用到为了定位和分割的自下而上的region proposals上;(2)当标记的数据不足时,用一个辅助的监督预训练,加上一个特定区域的finetuning,能很好地改善效果。作者将这种方法称为R-CNN。
二、论文的主要内容
1、Introduction
本文通过对两个问题的解决方法进行阐述,来表明CNN可以获得比HOG之类特征更好的效果。
(1)怎样用深度网络定位目标?
以前的方法中如果是单个目标,直接将检测构造回归问题;如果图像中有多个目标,则使用滑动窗口的方法;在碰到长宽比不一致的,可以通过像DPM这样变换长宽比的混合模型的方法来解决。
本文解决定位问题方法是引入proposal。具体操作思路就是:首先系统对图像产生大约2000个region proposals;然后用CNN给每个proposal提取一个固定长度的特征向量;最后再使用指定具体种类的SVM们(强调一下“们”,因为不是一个SVM,有多少个类就训练多少个SVM)来对每个region进行分类。图1就是R-CNN的网络框架。

图1.R-CNN网络结构
(2)怎样用只有少量标记的检测数据来训练一个大容量的模型?即如何解决训练过拟合的问题。
传统的方法是非监督的预训练和监督的fine-tuning相结合的方法。
本文方法是使用一个大的辅助的数据集进行监督预训练,然后再用一个小的数据集进行具体范围的fine-tuning。
2、相关工作:讨论了一些本文涉及到的一些要讨论的地方。
2.1 Deep CNNs for object detection.
2.2 可扩展性&速度. 可扩展性是指当分类的类目增加时,训练的detector是否还适用。举了一个基于DPM实现多分类的例子,但是检测精度大打折扣。那本文进行多分类时,图1中的前三部分都不需要变动,共享,只需要多训练一些SVM就行。
2.3 定位方法。上面说过。
2.4 Object proposal generation.
《What Makesfor Effective Detection Proposals》这篇论文主要探讨的就是这个问题。我之前有一篇关于这篇论文的阅读笔记。网址:http://blog.csdn.net/mw_mustwin/article/details/52877922
2.5 Transfer learning. 就是怎么样预训练怎么样fine-tuning的问题,论文要讨论的第二个问题,上面introduction里也有简单说明,后文中也会具体阐述。
2.6 R-CNN延伸。这个作者的R-CNN发了好几篇论文,所以有几个版本。14年就已经在CVPR上可以查到。所以这边16年在PAMI上有交代了后来关于这篇论文的改进,其中包括作者自己的fast R-CNN。
3、R-CNN进行目标检测
这一节第一部分将模型设计,第二部分讲detection的测试时间分析,第三部分讲训练过程,第四部分展示结果。
3.1 模块设计
3.1.1 region proposals.
有很多种产生proposals的方法,具体见《WhatMakes for Effective Detection Proposals》,效果差别很大。本文使用的是selective search。
3.1.2 特征提取
使用CNN给每个proposal算法提取一个固定长度的特征向量。论文中大多数的实验是使用的TorontoNet,后来也是用了16层的OxfordNet。
这两种CNN的输入都是经过mean-subtracted的S*S的RGB图像(所以每个proposal要进行预处理,后面第七章有讲到怎么处理)。取softmax层前面输出的经过前向传播产生的4096维的特征向量。随后拿去训练SVM。
3.2 运行时间分析
整个检测过程:首先对测试的图像用selective search产生大约2000个的proposal,然后转化proposal的size输入到CNN中,前向传播后产生特征向量。每一个SVM对应一个class,将产生的特征向量再输入到SVMs中,会产生每个class的得分。最后,对每一个class在图像中的所有得分区域使用非极大值抑制,去除那些重合且得分低的窗口。
论文在检测过程中两个地方很高效,导致其相对其他方法时间不会很长(但是还是挺长哈):(1)经过CNN的过程共享计算,即特征向量计算一遍就行。提取proposal和CNN提取特征在GPU上是10s每张图,CPU每张图53s。(2)提取的CNN特征向量是低维的,因此即使有很多个SVM,也不会产生太多的运行时间。
拿UVA系统进行对比分析,UVA运行时间是R-CNN的几百倍(两个量级),内存UVA要占据134GB,而R-CNN只要1.5GB。
3.3 训练过程
分为三块,预训练,fine-tuning以及SVM的训练。
3.3.1 监督预训练:使用一个大的辅助的数据集(ILSVRC2012)进行判别式地预训练。
3.3.2 具体范围的fine-tuning
为了适应新的任务和范围,我们接着只使用新的具体的数据集提取的proposal,以及随机低度下降方法来训练CNN参数。CNN的网络除了输出的类别数目由原来ILSVRC2012的1000类变为现在的N+1类,1表示背景。
那些和groundtruth重合IoU大于等于0.5的记为正样本,其余记为负样本。(这里我原先以为只要区分是目标还是背景就行了,一直很混淆,看了两遍才明白不是,每个正样本还要指定对应的是哪一类的正样本,所以其实上面的+1好像没啥意义,只要所有类别都为0不就表示是背景了吗?所以上面虽然说是N+1类,但是实际输出N维就可以了吧?)梯度下降算法的学习速率为0.001,使用批训练的方式,每批128个样本(正样本32,负样本96)。因为OxfordNet需要更多的内存,所以每批24个。
3.3.3 SVM进行具体类别分类
这边SVM训练时也考虑到IoU临界值设置问题,但是此时只把所有的groundtruth box
视为正样本,proposal与groundtruthbox的IoU小于等于0.3(0.3这个值是实验得出来的)就判为负样本。所以SVM训练过程中的proposal其实只是用来产生负样本的。另外,每个正样本还是要对应一个200维的标签,当训练A类时,把所有正样本中A类对应标签为1拿出来和负样本组合训练一个SVM,然后再训练B类……以此类推。
特征向量和标签设置好就开始训练,考虑到占内存的问题使用Hard negative mining方法来训练SVM。
3.3.4 这么费劲训练的原因
第一个问题,关于finetuning阶段使用的正样本和SVM阶段不一样的原因:如果fine-tuning使用和SVM阶段一样的正样本,结果会变很差,分析原因应该是:样本的数目会变少,训练发生过拟合。
第二个问题,为什么不直接用CNN的Softmax?因为相对于论文中的结果较差,3个percent的差距,分析原因可能是:fine-tuning使用的正样本不够精确定位,以及softmax使用的负样本是随机的,而SVM使用的是难例的子集。
3.4 结果

图2. VOC2010上各算法结果比较
并没有给VOC2012具体比较,只说了有相似的结果,两种CNN的mAP分别是53.3%,62.4%。
4、分析
4.1 可视化学习的特征
就不具体写了,附张图,大意就是学习到的特征能很好地反映图像内容。

图3. 可视化特征
4.2 Ablationstudy(不知道怎么翻译,大意是分析每个细节对结果的影响)
4.2.1 没有fine-tuning每一个全连接层的表现
Fc6的表现比fc7的表现好,所以没有必要加fc7。甚至移除fc6,pool5的输出效果相对fc6也没差太多。因此可以省去很多参数的训练。
4.2.2 带fine-tuning的每一个全连接层表现
Fc6和fc7相对于pool5的输出特征在最终的结果上有很大提高。
4.2.3 和最近的特征学习方法比较:R-CNN好太多。
附具体表现图:
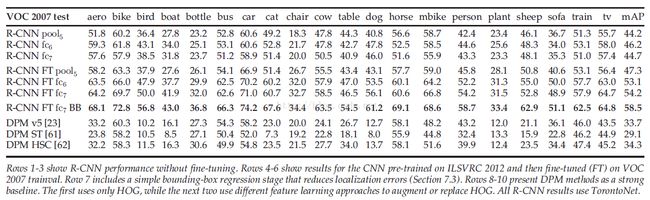
图4. VOC2007具体表现比较
4.3 网络结构
将TorontoNetand OxfordNet两种网络结构进行比较。OxfordNet的效果比TorontoNet好很多,但是前向传播时间长7倍。具体结果附图:

图5. TorontoNet and OxfordNet两种网络结构结果比较。
4.4 检测的误差分析
4.5 Bounding-Box 回归
用pool5层提取的特征训练一个线性回归模型预测新的检测窗口来提高定位表现。
将那些和最近的groundtruthbox有至少0.6的IoU的proposal作为训练样本,其余的proposal丢弃,形成N个训练对![]() 。这里P指proposal对应的特征向量,G指ground-truth box。具体训练过程没细看。
。这里P指proposal对应的特征向量,G指ground-truth box。具体训练过程没细看。
5 ILSVRC2013 检测数据集
5.1数据集介绍
包括训练集(395918),验证集(20121)以及测试集(40152)。应该是算法只能想系统提交两次。训练集标记不充分,所以策略是依赖验证集,辅助训练集。将验证集划分为val1和val2。
5.2 region proposal
和前面没差,主要是ILSVRC数据集尺寸不一致,所以在selective search之前对图像尺寸作调整。
5.3 训练数据
训练集包括:(1)val1中的groundtruth box;(2)selective search在val1上产生的proposal;(3)训练集上最多N个ground-truth box。(N论文中有三个选择:0,500,1000)。
训练集用于CNNfine-tuning,SVM的训练以及Bounding-Box回归。具体怎么用,见下图。其中测试集是test的两个是提交的。

图6.ILSVRC2013不同训练数据选择以及结果
第6章 关于分割,目前暂时不关注。
7、实现和设计细节
7.1 proposal的转换
Selective search产生的proposal是任意的矩形,但CNN的输入需要固定的size。两个方法:
(1)tightest square with/without context。意思就是proposal不变型,以长边为基准,短的一边要么加原图内容,要么加白色边来填充。
(2)warp。就是变形拉伸,就类似于我们平常不固定长宽比调图像大小图像会扭曲类似。Warp好像就有扭曲的意思。效果见图,一看就懂。

图7. 处理proposal方式。A为原proposal;B为填充原图内容;C填充灰边;D扭曲。
7.2 Positive versus negative examples and softmacx
见3.3.4
7.3 boundingbox regression
见4.5