【工大SCIR笔记】事实感知的生成式文本摘要
作者:哈工大SCIR 黄毅翀
序言
抽取式的文本摘要直接从原文中摘取完整的句子作为文章的摘要,如同按部就班的老实人,令人心安;生成式的文本摘要可以产生原文中没有的单词和短语,好比一位逍遥的江湖侠客,蛟龙终非池中物,目前,我们这位侠客虽然艳惊四座,但却容易野马脱缰,返回不符合事实的结果。
本文将简单介绍如何解决生成式文本摘要中事实性错误的相关研究。
1. 生成式文本摘要的困境:事实性错误
文本摘要(Text Summarization)是NLP中非常重要的一项任务,即给定一篇长文章作为原文,模型生成一段覆盖原文关键信息的文本作为该文章的摘要。
总的来说,文本摘要分为抽取式(Extractive)和生成式(Abstractive)。前者直接从原文中挑选出重要的句子拼接成一段摘要;后者模拟人进行摘要的过程,首先对原文进行理解,然后从头生成一段摘要,可能包含原文中未曾出现过的表达。
近些年来,基于神经网络的生成式文本摘要被广泛地关注与研究,并且取得了突破性的进展(Gehrmann et al., 2018; Nallapati et al., 2016)。生成式文本摘要能够产生原文中没有出现过的表达,相比于抽取式更加灵活,但是也因此更容易产生事实性错误。这些错误既包括与原文信息相违背的内容,又包括与人们的常识相违背的内容。
例如:原文中包含了这样一个事实:
“诺兰于2010年导演了《盗梦空间》,由莱昂纳多主演。”
但是生成式文本摘要可能会生成这样一个事实性的错误:
“莱昂纳多导演了《盗梦空间》”
有学者统计,在state-of-the-art的摘要模型中,大约有30%的摘要包含事实性错误!这一问题极大地限制了生成式文本摘要的实际使用。
接下来,本文将介绍针对这一问题的相关研究。其研究主要分为两条路线:
如何提升摘要的事实准确性。
如何评价摘要的事实准确性。
本文将事实相关的文本摘要研究发展整理如图1所示:
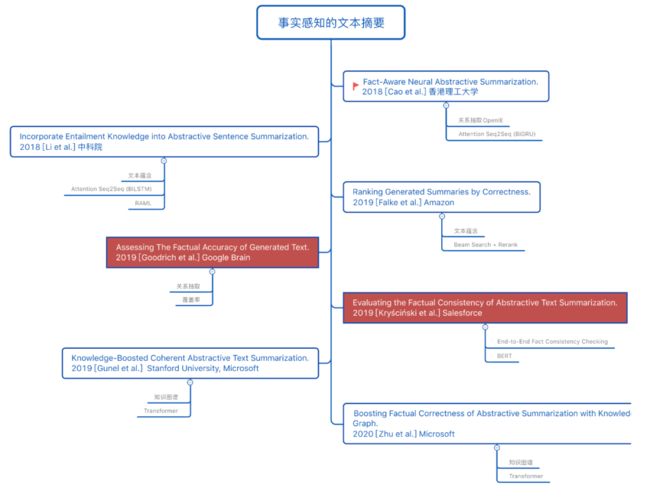
图1 事实相关的文本摘要相关研究发展脉络,白色背景表示关于“如何提升摘要的事实准确性”这一问题的研究;红色背景表示关于“如何评价摘要的事实准确性”这一问题的研究。
2. 如何提升摘要的事实准确性?
目前,提升摘要的事实准确性的方法可分为:
对事实进行“抽取+编码”,从而更好地建模事实的语义表示。我们将这一类方法简称为基于事实表示的摘要模型;
结合文本蕴含(Textual Entailment),识别出摘要中的事实性错误并对模型进行惩罚。我们将这一类方法称为基于文本蕴含的摘要模型。
本文将提升摘要的事实准确性的方法进一步归类如图2所示:
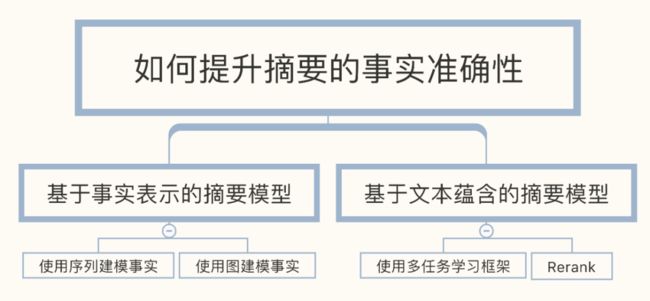
图2 如何提升摘要的事实准确性相关研究
说明一下,由于目前的研究主要集中于解决与原文相违背的事实性错误,所以在第2章中只有2.1.3小节是关于如何解决与常识相违背的事实性错误。
2.1 基于事实表示的摘要模型
直观上,解决事实性错误的理想方案,是对原文中的事实进行编码,更好地对事实进行建模,然后传入摘要系统中,从而使模型能够准确地表示事实。
在这一核心思想的指导下,我们首先要抽取出原文中的事实。目前比较常用的方法是使用Stanford的OpenIE,给定一段文本X,OpenIE能够抽取出其中的三元组集合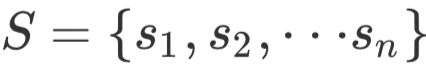 ,其中
,其中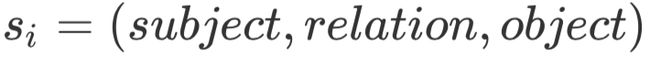 ,下表是一个OpenIE的使用例子:
,下表是一个OpenIE的使用例子:
表1 一个OpenIE的使用实例

在抽取出文本中的事实之后,我们该如何表示事实呢?接下来本文将为大家介绍两种采用不同的事实表示方法及其模型:
2.1.1 序列式编码 + Attention Seq2Seq
[Cao et al., 2018]在抽取出原文中的事实三元组之后,将三元组生成一段事实描述。具体做法为:
对于每个三元组(subject, relation, object),我们将其转换成文本"subject relation object",我们将这段文本称为该三元组的事实描述(Fact Description);
接下来,我们使用标识符" |||" ,对所有的Fact Description进行拼接,将最后结果作为该文本的事实描述。
以表1中OpenIE使用实例中抽取出的三元组为例子,我们将生成如下事实描述:
Barack Obama was born in Hawaii ||| Richard Manning wrote sentence
在完成对事实的抽取以及表示成一段文本序列(事实描述)之后,采用两个Encoder分别对原文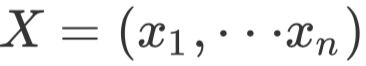 和事实描述
和事实描述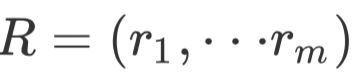 进行编码,然后将两段文本的hidden state传给Decoder解码,生成摘要。其模型称为FTSum,模型结构示意图如下:
进行编码,然后将两段文本的hidden state传给Decoder解码,生成摘要。其模型称为FTSum,模型结构示意图如下:
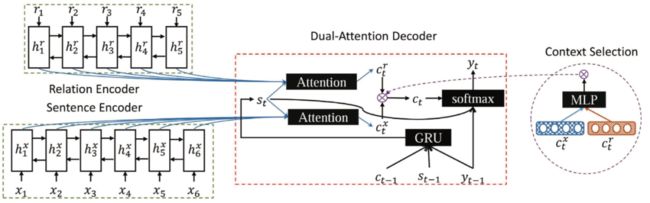
图3 FTSum模型结构示意图
具体而言,在Encoder层:
使用BiGRU对原文X进行编码得到
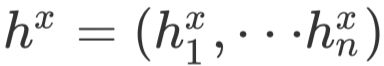 ,对事实描述R进行编码得到
,对事实描述R进行编码得到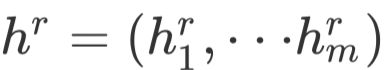 。
。
在Decoder层:
在第t步的解码过程中,首先使用t-1步的解码器隐藏层状态
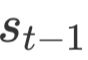 、上下文向量
、上下文向量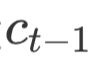 和预测输出
和预测输出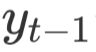 作为输入,生成第t步的解码器隐藏层状态
作为输入,生成第t步的解码器隐藏层状态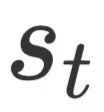 。然后以作为Query,对编码器输出
。然后以作为Query,对编码器输出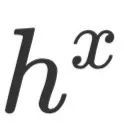 和
和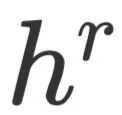 分别做attention,生成两个上下文向量
分别做attention,生成两个上下文向量 和
和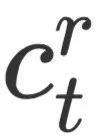 ,并且通过一个MLP层将两个上下文向量合并成最终的上下文向量
,并且通过一个MLP层将两个上下文向量合并成最终的上下文向量 。最终,根据、和上一时刻的输出
。最终,根据、和上一时刻的输出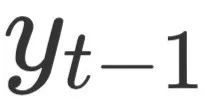 生成该时刻的预测输出
生成该时刻的预测输出 。
。
2.1.2 图编码 + Transformer
[Zhu et al., 2020]在抽取出原文中的事实三元组之后,构建了一个基于原文的知识图谱。
对于每个三元组(subject, relation, object),我们将subject,relation,object视为三个节点,然后得到两条无向边subject-relation和relation-object,这样一来,通过对所有三元组构建边,我们就能得到一个无向图,这就是该文章的知识图谱。
之后,我们在该知识图谱上使用图注意力神经网络提取每个结点的特征,并将这个特征作为该节点的表示。如此,我们就完成了事实的表示。
为了将事实融合进摘要模型中,这项工作在Transformer的基础上提出了自己的摘要模型FASUM,模型结构如下:
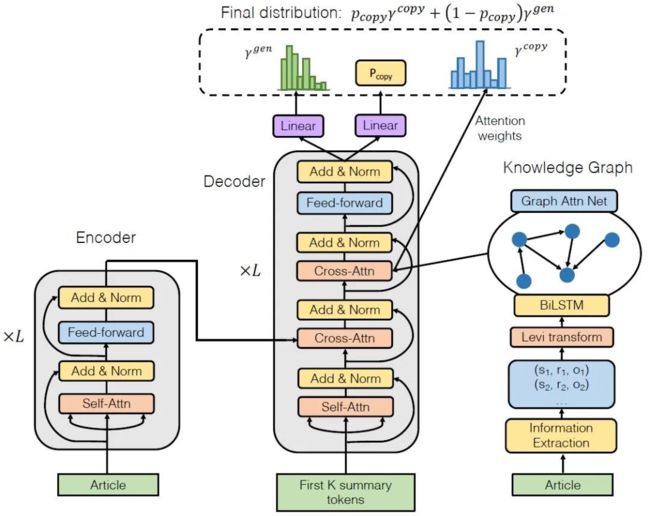
图4 FASUM模型结构示意图
模型可以分为三部分:编码器、解码器和事实提取器(知识图谱)。其中,左边部分和中间部分合起来可以视为是加入了copy机制的Transformer,与Transformer不同的是,FASUM在Decoder中的Decoder-Encoder子层之上添加了一个Decoder-Knowledge Grpah层,用于融合事实信息。具体的融合方式如下:
在第t步的解码过程中,设前t-1步中的解码器隐藏层状态为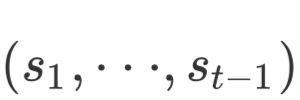 ,且
,且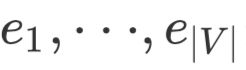 是知识图谱中的节点的嵌入表示,那么当前步骤的需要融入的事实信息就是:
是知识图谱中的节点的嵌入表示,那么当前步骤的需要融入的事实信息就是:
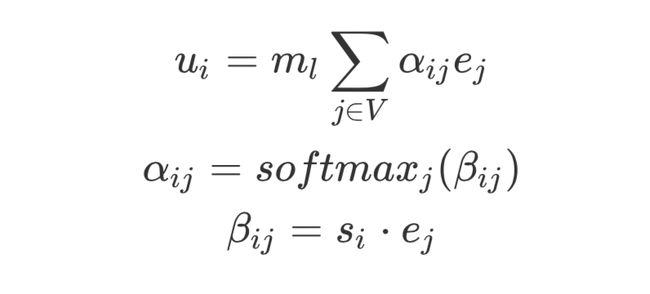
其中的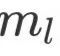 的引入是由于Token Embedding与Fact Embedding的数值大小存在偏差,所以引入这个可学习的参数进行调整,
的引入是由于Token Embedding与Fact Embedding的数值大小存在偏差,所以引入这个可学习的参数进行调整, 表示解码器的层数。
表示解码器的层数。
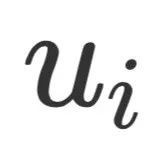 可以认为是第i步解码过程中所需要关注的事实信息,在得到之后,就可以通过常规的自注意力机制、层归一化和残差连接,和前馈层将Token Embedding和Fact Embedding融合在一起,如上图中间所示,得到该层最终的特征表示
可以认为是第i步解码过程中所需要关注的事实信息,在得到之后,就可以通过常规的自注意力机制、层归一化和残差连接,和前馈层将Token Embedding和Fact Embedding融合在一起,如上图中间所示,得到该层最终的特征表示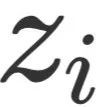 。
。
2.1.3 图编码(外部知识)+Transformer
在上述两项工作中,都是通过对原文中的事实进行抽取,并且编码进摘要系统中。但是摘要生成的事实性错误除了与原文中事实相违背的内容,还有与人们的常识相违背的内容,那我们能否将外部知识引入摘要系统中呢?
[Gunel et al., 2019]对Wikidata(一个开放的知识库)中的数据进行采样,构建知识图谱,然后使用TransE(一种知识表示的学习方法)学习实体的表示,并将学习的结果作为实体嵌入层,提供给摘要模型。模型也是基于Transformer,结构示意图如下:
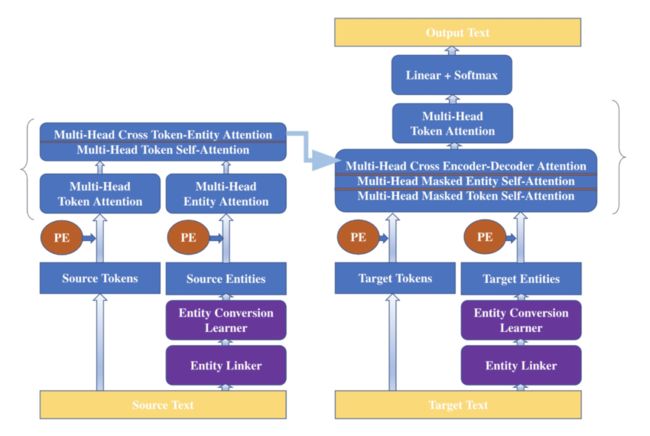
图5 引入Wikidata Knowledge Graph作为外部知识的摘要模型结构示意图。模型左边为Encoder,Source Text为源文本;右边为Decoder,Target Text为摘要。PE为Positional Encoding
其中:
Entity Linker是一个现成的实体抽取器,负责从原文和摘要中抽取实体,并且通过前文所介绍的在Wikidata Knowledge Graph预训练出来的实体嵌入层获取实体的表示,我们可以认为该步骤的目的是将原文中的事实与外部知识(Wikidata)进行链接(对应名称中的"Linker");
Entity Conversion Learner是一系列前馈全连接层+激活函数ReLU,用于将从Wikidata中学习到的实体表示转换(对应原文中的"Conversion")到与token embedding相同维度的语义空间(简而言之就是使Entity Embedding的维度与Token Embedding相同)。
在Encoder中,一方面用Transformer块对源文本中的Token编码成向量(我们称为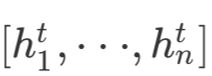 ,其中n为源文本长度);另一方面使用Entity Linker和Entity Conversion Learner对源文本中的实体编码成向量(我们称为
,其中n为源文本长度);另一方面使用Entity Linker和Entity Conversion Learner对源文本中的实体编码成向量(我们称为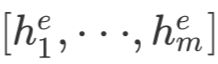 ,其中m为从源文本中抽取出的实体的数量)。然后以为多个query,对做attention,得到编码器最终的输出
,其中m为从源文本中抽取出的实体的数量)。然后以为多个query,对做attention,得到编码器最终的输出 。
。
在Decoder中也是一样的过程,假设当前为第t步解码,一方面用Transformer块对当前步已经生成的摘要进行编码得到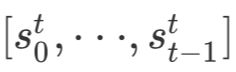 (其中
(其中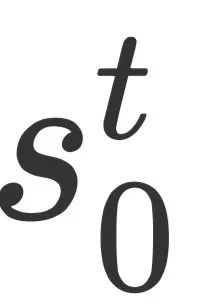 是特殊标志符
是特殊标志符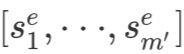 (其中 m' 为从当前步所生成的摘要中抽取出的实体的数量),之后也是摘要中的token向量与实体向量做attention,得到解码器隐藏层状态
(其中 m' 为从当前步所生成的摘要中抽取出的实体的数量),之后也是摘要中的token向量与实体向量做attention,得到解码器隐藏层状态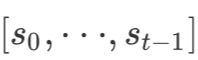 ,最后就是和Transformer Decoder一样的过程,将从摘要得到的向量与编码器得到的向量传入Encoder-Decoder子层,融合后预测输出。
,最后就是和Transformer Decoder一样的过程,将从摘要得到的向量与编码器得到的向量传入Encoder-Decoder子层,融合后预测输出。
2.2 基于文本蕴含的摘要模型
除了对文本中的事实进行编码从而提高摘要的事实准确率,还可以通过引入文本蕴含,来检测摘要中与原文中的事实是否是一致的。
我们首先给出文本蕴含的定义:
给定两段文本A和B,如果从A可以推理出B,那么我们认为A蕴含B(Entailment);如果从A能推翻B,那么我们认为A驳斥B(Contradiction);如果既不能推理出也不能反驳,那么我们认为A和B之间就是不明确的关系(Unclear)。目前,文本蕴含有基于相似度、逻辑演算和深度学习等方法来做的。
那么我们该如何将文本蕴含引入摘要当中呢?
首先,我们得明确这样一个观点:“如果一段摘要相对于原文是事实准确的,那么原文必定蕴含这段摘要”。在具体实现上,目前主要有采用多任务学习和Rerank机制两种方式来引入文本蕴含。
2.2.1 使用多任务学习引入文本蕴含
[Li et al., 2018]等人采用多任务学习的方式引入文本蕴含。具体来说,就是以attention Seq2Seq为基础架构,然后将Encoder共享给文本蕴含任务,也就是使用摘要模型中的Encoder与一个softmax层组成蕴含关系分类器,并且在NLI数据集上进行训练,这样做的目的就是使摘要模型的Encoder具有蕴含意识,论文作者在做实验时采取的多任务学习方式是每在摘要数据集上迭代100次,就在文本蕴含数据集上迭代10次;同时呢,在Decoder解码的时候,对损失函数进行修改,以生成摘要的被蕴含程度(Entailment)作为奖励(Reward),采用RAML(奖励增强的极大似然)机制进行训练,使Decoder也具有蕴含意识。模型结构示意图如下:
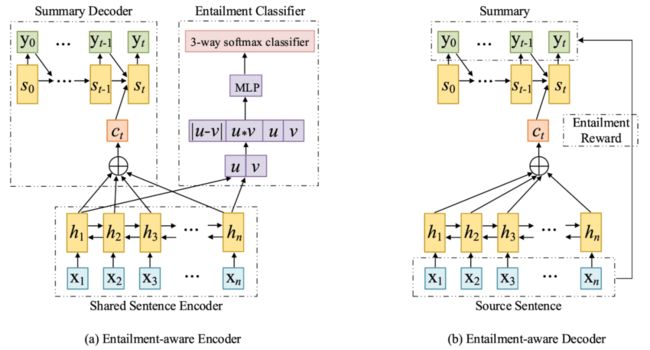
图6 使用多任务学习框架将文本蕴含引入摘要模型结构示意图。Entailment-aware Encoder被同时用于训练文本摘要生成(图(a)左半部分)和文本蕴含识别(图(a)右半部分)。Entailment-aware Decoder采用蕴含奖励增强极大似然(Entailment RAML)的方法进行训练,如果生成的摘要能被原文蕴含,模型将会得到奖励。
Entailment-aware Encoder使用BiLSTM(双向长短期记忆网络),在训练文本摘要时,采用seq2seq架构;在训练蕴含识别时,将文本蕴含数据集中的句子对(sentence pair)分别进行编码得到u和v,然后将u和v构成特征向量,传入MLP+softmax中进行蕴含预测。
Entailment-aware Decoder中,使用摘要被原文蕴含的程度作为奖励,并使用奖励增强的极大似然(Reward Augmented Maximum Likelihood, RAML)代替普通的极大似然损失函数(例如:交叉熵)进行训练,鼓励模型生成更能被原文蕴含的摘要。由于RAML解释起来篇幅较长,并且与本文主题关联不大,因此不再赘述,若读者感兴趣,可以阅读原论文Reward Augmented Maximum Likelihood for Neural Structured Prediction以及RAML在文本摘要中的应用(参考文献[6])。
2.2.2 使用Rerank引入文本蕴含
除了上述通过多任务学习的方式修改模型来引入文本蕴含,我们还可以通过在文本摘要做后处理,引入文本蕴含:
[Falke et al., 2019]使用现有的NLI工具,对文本摘要模型生成的所有候选摘要(比如:我们使用size为k的beam search,那么就有k个候选摘要)进行文本蕴含预测,选出被原文蕴含程度最高的候选摘要作为最终的输出。但是受限于目前现有的文本蕴含工具的效果,该项研究在实验上并没有取得很好的效果。
3. 如何评价摘要的事实准确性?
量化通常是人们衡量一个领域是否成熟的关键。为了衡量上述工作的效果,目前提出了两种自动衡量摘要事实准确性的方法:
与ROUGE、BLEU等根据源文本与目标文本的n-gram重叠率(overlap)来衡量文本生成质量这一思想类似,我们可以通过计算源文本与摘要中的事实三元组重叠率来衡量事实准确性。我们将这一类方法称为基于三元组重叠率的事实准确性评价;
根据“正确的摘要应该能够被原文所蕴含”这一思想,我们可以通过计算摘要被原文的蕴含程度来作为事实准确性。我们将这一类方法称为基于文本蕴含的事实准确性评价。
图7 如何评价摘要的事实准确性相关研究
3.1 基于三元组重叠率的事实准确性评价
通过比较源文本与摘要中的事实三元组重叠率来衡量事实准确性是比较简单可行的评价方法,其前提是能从源文本和摘要中准确地抽取事实三元组。
[Goodrich et al., 2019]等人首先尝试使用OpenIE抽取事实三元组,但是由于OpenIE抽取三元组没有固定的模式(Free Schema),导致三元组之间难以比较,比如我们分别从原文和摘要中抽出:
原文:Obama was born in Hawaii ⇒ (Obama, born in, Hawaii)
摘要:Hawaii is the birthplace of Obama ⇒ (Hawaii, is the birthplace of, Obama)
可见,其实两个三元组表达的是相同的内容,但是却由于字面不同而无法匹配,从而使准确率偏低。
为了解决这个问题,作者采用模型固定(Fixed Schema)的关系抽取方法,我们可以认为是预定义了一个Relation Set,只有是relation在该Set中的三元组才会被抽取出来。这样做的好处是:假设预定义的Relation Set中包含“Birthplace of”这一关系,那么上述例子中不论是从原文还是从摘要中抽取,其结果都是 (Hawaii, birthplace of, Obama),如此一来,三元组的可比较性得到了极大的提高。
3.2 基于文本蕴含的事实准确性评价
使用文本蕴含模型计算原文T蕴含摘要S的程度并打分,并将结果![]() 作为摘要的事实准确性,这是一种十分可行的方案,然而,正如2.2.2小节中介绍的[Falke et al., 2019]工作中所言,目前的文本蕴含模型并不能为文本摘要事实准确性评价任务上提供可靠的预测。
作为摘要的事实准确性,这是一种十分可行的方案,然而,正如2.2.2小节中介绍的[Falke et al., 2019]工作中所言,目前的文本蕴含模型并不能为文本摘要事实准确性评价任务上提供可靠的预测。
针对上述问题,[Kryściński et al., 2019]进行了进一步的分析。由于目前的文本蕴含模型预测的都是sentence-sentence级别的蕴含程度,而文本摘要的事实准确性预测是一个document-document级别的任务,所以并不适用。
因此,[Kryściński et al., 2019]采用基于规则的方法构建了一个document-sentence级别的文本蕴含数据集,然后训练document-sentence级别的文本蕴含识别模型。在测评时,分别将摘要的每句话与原文输入进该蕴含识别模型进行蕴含程度的打分,并将所有句子的蕴含度分数的均值作为摘要的事实准确性。最终通过将方法的结果与人工评价的结果进行相关度测量,证明了该方法的有效性。
4. 结论
在这篇文章中我们介绍了如何解决生成式文本摘要中的事实性错误,即如何使我们的文本摘要模型具备事实感知。该项研究主要分为两条线路:提升摘要模型的事实准确性,以及评价摘要的事实准确性。
目前主要的研究还是集中于提升摘要的事实准确性上,并且从最初的使用序列建模事实到使用图建模事实,从解决与原文相违背的事实性错误到解决与常识相违背的事实性错误,事实感知的文本摘要已经取得了一定的研究成果,但是在常识性错误这一问题上还有待提高。
在事实准确性的评价上,暂时没有像ROUGE一样具有普适性的、能在开放域上进行评测的工具和方法。
研究事实感知的文本摘要,能够避免原文语义的曲解,这不仅对于鉴别当前互联网上随处可见的假新闻有重要的意义,而且有利于加速文本摘要大规模落地的进程。
参考文献
[1] Gehrmann, Sebastian, Yuntian Deng, and Alexander M. Rush. "Bottom-up abstractive summarization." arXiv preprint. (2018).
[2] Nallapati, Ramesh, et al. "Abstractive text summarization using sequence-to-sequence rnns and beyond." arXiv preprint. (2016).
[3] Cao, Ziqiang, et al. "Faithful to the original: Fact aware neural abstractive summarization." AAAI. 2018.
[4] Zhu, Chenguang, et al. "Boosting Factual Correctness of Abstractive Summarization with Knowledge Graph." arXiv preprint. (2020).
[5] Gunel, Beliz, et al. "Mind The Facts: Knowledge-Boosted Coherent Abstractive Text Summarization."
[6] Li, Haoran, et al. "Ensure the correctness of the summary: Incorporate entailment knowledge into abstractive sentence summarization." COLING. 2018.
[7] Falke, Tobias, et al. "Ranking generated summaries by correctness: An interesting but challenging application for natural language inference." ACL. 2019.
[8] Goodrich, Ben, et al. "Assessing the factual accuracy of generated text." KDD. 2019.
[9] Kryscinski, Wojciech, et al. "Evaluating the factual consistency of abstractive text summarization." arXiv preprint. (2019).
本期责任编辑:李忠阳
本期编辑:顾宇轩
交流学习,进群备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。
广告商、博主勿入!

