2022五月组队学习——吃瓜教程:task01
目录
第一章 绪论
1.1 引言
1.2 基本术语
1.3 假设空间
1.4 归纳偏好
第二章 模型评估与选择
2.1 经验误差与过拟合
2.2 评估方法
2.2.1 留出法
2.2.2 交叉验证法
2.2.3 自助法
2.2.4 调参与最终模型
2.3 性能度量
2.3.1错误率与精度
2.3.2 查准率、查全率与Fl
2.3.3 ROC与AUC
第一章 绪论
西瓜书的开源自取(大家可以在这个里面自己看喔 这也是我喜欢dw的理由之一喔)
1.1 引言
机器学习理论主要是设计和分析一些让计算机可以自动“学习”的算法。机器学习算法是一类从从数据中产生"模型" (model) 的算法,即"学习算法" (learning algorithm),并利用规律对未知数据进行预测的算法。(总结中和书中"模型"泛指从数据中学得的结果)
1.2 基本术语
基本术语概念大家就看看表吧,讲真整理表还是挺累的。
| 术语 | 英文 | 自我总结的概念 |
| 数据集 |
data set
|
样本集合或数据的集合 |
| 样本(示例) | simple(instance) |
数据集中对一个事件或对象的描述
|
| 属性(特征) |
attribute (feature)
|
反映事件或对象在某方面的表现或性质的事项
|
|
属性值
|
attribute value | 属性上的取值(个人理解为属性的具体化) |
| 属性空间 |
attribute space
|
属性张成的空间(个人理解为属性的坐标化或空间化) |
| 特征向量 |
feature vector
|
一个样本在属性空间对应的坐标向量(个人理解浅浅为属性值和属性空间的结合) |
| 维数 |
dimensionality
|
样本的属性描述个数(属性个数) |
| 学习器 | learner | 可以理解为模型(本文也会用学习器代表模型) |
| 标记 | label |
样本的"结果"信息
|
| 样例 | example |
拥有了标记信息的示例(样本+label)
|
| 标记空间 (输出空间) |
label space
|
所有标记的集合 |
| 分类 |
classification
|
学习任务为预测离散值 |
| 回归 |
regression
|
学习任务为预测连续值 |
| 训练样本 |
training sample
|
从数据中学得模型的过程称为"学习" 或"训练" ,训练过程中使用的数据中的每一个样本
|
| 测试样本 | testing sample |
学得模型后,使用其进行预测 ,被预测的样本称为测试样本,
|
| 聚类 |
clustering
|
即将训练集中的样本分成若干组,并这些组不进行标记。(不拥有标记信息的分类 )
|
| 簇 |
cluster
|
聚类分成的每一个组 |
| 泛化能力 |
generalization ability
|
.学得模型适用于新样本的能力
|
部分术语的表达式:
| 术语 | 表达式 |
|
表示包含m 个示例的数据集
|
D= |
| 第i个示例 | |
 在第j个属性上的取值 在第j个属性上的取值 |
 |
| 测试的例子x的预测标记 | f(x) |
其中监督学习和无监督学习的分类,是根据训练数据是否拥有标记信息。
监督学习的代表是回归和分类,而无监督学习的代表是聚类。
1.3 假设空间
在了解假设空间的时候我们先了解一波两大科学推理的基本手段:归纳和演绎。
归纳是从特殊到一般的"泛化" (generalization) 过程,即从具体的事实归结出一般性规律;而对于演绎则是从一般到特殊的"特化" (specialization)的过程,即从基础原理推演出具体状况。
而机器学习正是用的归纳学习的方法,"从样例中学习"。
而假设空间可以理解为所有假设(hypothesis) 组成的空间,而学习的过程可以看作在这个空间进行搜索的过程。搜索目标是找到与训练样本集"匹配" 的假设,即能够将训练集中的样例判断正确的假设.假设的表示一旦确定,假设空间及其规模大小就确定了。
可以有许多策略对这个假设空间进行搜索,例如自顶向下、从一般到特殊,或是自底向上、从特殊到一般,搜索过程中可以不断删除与正例不一致的假设、和(或)与反例一致的假设.最终将会获得与训练集一致(即对所有训练样本能够进行正确判断)的假设,这就是我们学得的结果。
而我们学的结果和目标(即机器学习的目标)以样本中的模型具有适用于新样本的高"泛化"能力.
1.4 归纳偏好
由于才疏学浅,这个部分就暂时不给大家归纳了。(主要看不懂啊呜呜,等我后面学飘了我在回来写写 希望那个时候我还记得。)
后面的啥发展历程、应用现状和阅读材料我就暂时不写了,互联网看看文献,机器学习现在的火热大家懂的都懂。
第二章 模型评估与选择
终于到第二章了讲真前面做表格是最累的,那我们也终于开始往机器学习的门那边走了。当然这一章后面也有省略不写的,原因我也就不说了,还是一句话,等我学飘了,我再回来写。
2.1 经验误差与过拟合
先讲两个概念
错误率:
/**表示在m个样本中有a个样本分类错误**/
精度:
2.2 评估方法
2.2.1 留出法
我们希望评估的是用D训练出的模型的性能,但留出法需划分训练/测试集,这个划分过大过小都会出问题,这个问题没有完美的解决方案 常见做法是将大约2/3~4/5 样本用于训练,剩余样本用于测试。
2.2.2 交叉验证法
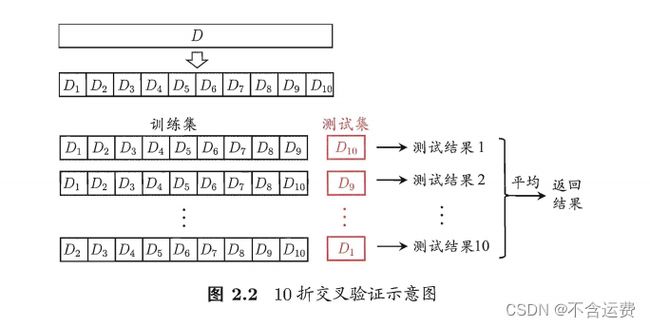
2.2.3 自助法
“自助法”(bootstrapping)以自助采样法(bootstrap sampling)为基础. 给定包含m个样本的数据集D,我们对它进行采样产生数据集D,每次随机从D中挑选一个样本,将其拷贝放入D’,然后再将该样本放回初始数据集D中,使得该样本下次采样时仍有可能被采到;这个过程重复执行m次后,我们就得到了包含m个样本的数据集D’,这就是自助采样的结果。
自助法在数据集较小、难以有效划分训练/测试集时很有用。
2.2.4 调参与最终模型
大多数学习算法都有些参数(parameter)需要设定,参数配置不同,学得模型的性能往往有显著差别,因此,在进行模型评估与选择时,除了要对适用学习算法进行选择,还需对算法参数进行设定,这就是通常所说的“参数调节”或简称“调参”(parameter tuning)。
调参主要还是得靠经验,能否有效就得看是调参侠的独到经验了。
2.3 性能度量
衡量模型泛化能力的评价标准,就是性能度量。
回归任务最常用的是"均方误差":
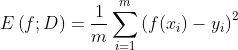 (2.2)
(2.2)
更一般的,对于概率分布和概率密度p(.),均方误差可描述为:
![]() (2.3)
(2.3)
下面主要讲的是分类任务的常用的性能度量
2.3.1错误率与精度
参考2.1所讲的概念

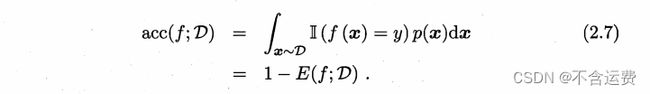
2.3.2 查准率、查全率与Fl

查准率P和查全率R是一对矛盾的度量,一般来说,查准率高时,查全率往往 偏低;而查全率高时,查准率往往偏低。但如何使得两者都实现相对"双高"的值不太容易估算,故我们需要**“平衡点”(Break- Even Point, 简称BEP)**,它是“查准率P=查全率R”时的取值。
但平衡点BEP还是过于简化了些,更常用的是F1度量:
而在一些应用中,对查准率和查全率的重视程度有所不同.F1度量的一般形式 ——![]() , 能让我们表达出对查准率/查全率的不同偏
, 能让我们表达出对查准率/查全率的不同偏
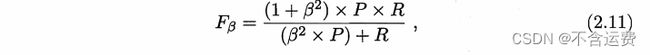
2.3.3 ROC与AUC
后面还有比较方差啥的好多但是我还没吃透
另附我这两章的小笔记虽然字有点丑
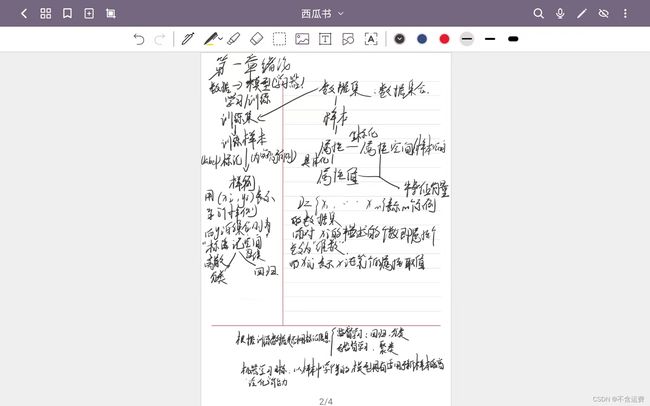
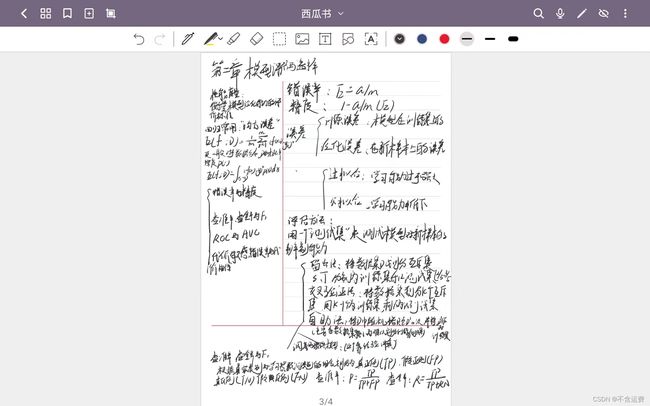
这后面的暂时就不总结的,还是那句话,等我学飘了回来补这个