用python构建线性回归和决策树模型实现房价预测
国家整体经济水平的不断提高和人们生活质量的提升,刺激着房屋价格也在不断的上涨,具体可查看国家统计局发布的数据。房价是由多个因素决定的,比如国家的宏观调控、居民人均可支配收入、房地产开发投资、住宅销售面积等,这些因素都影响着房价的走势。
- 研究目标:搜集相关数据,运用机器学习实现房价的预测
- 选取指标:
: --需求方面:X1地区生产总值(亿元);X2城镇居民家庭人均可支配收入(元);X3总人口数(万人)
: --供给方面:X4房地产开发投资额(万元);X5住宅房屋竣工面积(万平方米);X6商品房销售面积(万平方米)
: --目标变量:Y商品房平均销售价格(元/平方米) - 数据及其来源:2000年–2015年全国31个省份的指标数据,其中2000年–2015年作为模型训练和测试数据,2016年的数据作为预测数据。数据来自中国经济社会大数据研究平台。
- 研究方法及思路:分别构建线性回归和决策树模型实现对房价的预测,并进行对比分析。调用Python的sklearn、statsmodels包,运行环境为Python3.5.2、Anaconda4.2.0。


Step1:数据基本统计分析
首先,查看数据基本分布情况。
#-*- coding: utf-8 -*-
import pandas as pd
import numpy as np
##读取数据,查看数据基本分布
house=pd.read_csv('datasets/housing_2.csv',index_col=0,encoding='gb2312')
print (house.shape)
print (house.describe())
#index=house.index
#print (index)

查看各变量间的相关系数。
print ('相关系数:')
house.corr()

##绘制相关系数散点图
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib
sns.set(style="ticks", color_codes=True);
# Create a custom color palete
palette = sns.xkcd_palette(['dark blue', 'dark green', 'gold', 'orange'])
# Make the pair plot with a some aesthetic changes
sns.pairplot(house.drop([u'地区',u'时间'],axis = 1), diag_kind = 'kde', plot_kws=dict(alpha = 0.7))
plt.show()

根据相关系数表和散点图矩阵,X2城镇居民家庭人均可支配收入与Y商品房平均销售价格的线性相关性最大,相关系数超过了0.8,其次是X4房地产开发投资额,相关系数超过了0.5。但是,X3总人口数与X5住宅房屋竣工面积、X4房地产开发投资额与X6商品房销售面积的相关系数超过了0.8,即各因素间存在多重共线性,不满足相互独立的条件,不太适合直接进行线性回归。但是为了对比模型效果,后面还是构建了线性回归模型。
Step2:划分训练集和测试集
运用sklearn.model_selection的train_test_split进行数据集划分,也可以用k折交叉验证(KFold)。
##划分训练集和测试集
from sklearn.model_selection import train_test_split
#划分数据集
house_train,house_test=train_test_split(house,test_size=0.3, random_state=0)
print ('训练集描述性统计:')
print (house_train.describe().round(2))
print ('验证集描述性统计:')
print (house_test.describe().round(2))
#['X2','X3','X5','X6']
features=['X1','X2','X3','X4','X5','X6']
X_train=house_train.ix[:,features]
y_train=house_train.ix[:,'Y']
X_test=house_test.ix[:,features]
y_test=house_test.ix[:,'Y']

Step3:构建线性回归模型预测房价
为了更全面的评估模型效果,分别运用sklearn.linear_model和statsmodels.api.sm构建线性回归模型,综合两个模型的结果更好的解释模型。其中 sklearn(https://scikit-learn.org/stable/index.html)是机器学习中一个常用的python第三方模块,里面对一些常用的机器学习方法进行了封装,比如SVM、KNN、贝叶斯、线性回归、逻辑回归、决策树、随机森林、xgboost、GBDT、boosting、神经网络NN;statsmodels(http://www.statsmodels.org)用于拟合多种统计模型,比如方差分析、ARIMA、线性回归等,执行统计测试以及数据探索和可视化。
#线性回归模型训练、评估,为了更全面的评估模型的效果,此处使用了sklearn.linear_model和statsmodels.api.sm建模,综合两个模型的结果更好的解释模型
from sklearn import linear_model
from sklearn.metrics import mean_squared_error,explained_variance_score,mean_absolute_error,r2_score
reg = linear_model.LinearRegression()
reg.fit (X_train,y_train)
print ('coef:',reg.coef_)
#print (reg.predict(X_test))
print ("线性回归评估--训练集:")
print ('训练r^2:',reg.score(X_train,y_train))
print ('均方差',mean_squared_error(y_train,reg.predict(X_train)))
print ('绝对差',mean_absolute_error(y_train,reg.predict(X_train)))
print ('解释度',explained_variance_score(y_train,reg.predict(X_train)))
print ("线性回归评估--验证集:")
print ('验证r^2:',reg.score(X_test,y_test))
print ('均方差',mean_squared_error(y_test,reg.predict(X_test)))
print ('绝对差',mean_absolute_error(y_test,reg.predict(X_test)))
print ('解释度',explained_variance_score(y_test,reg.predict(X_test)))
import statsmodels.api as sm
X_train=sm.add_constant(X_train)
est=sm.OLS(y_train,X_train).fit()
print (est.summary())
#print (reg.predict(house.ix[:,0:6]))

用6个影响因素建立线性回归模型,发现虽然模型的拟合优度 R 2 R^2 R2和调整的 R 2 R^2 R2超过了0.8,即拟合效果很好,但是X1和X4没通过显著性检验((P>|t|)<0.05为通过检验),模型不可用。剔除X1和X4,重新构建模型,整个模型和各个因素均通过了显著性检验,可用该模型对Y商品房平均销售价格进行预测。
Step4:构建决策树回归模型预测房价
##决策树,划分训练集和测试集,可使用K折交叉验证(KFold)或者train_test_split
from sklearn.model_selection import KFold
from sklearn.model_selection import train_test_split
features_tree=['X1','X2','X3','X4','X5','X6']
house_train,house_test=train_test_split(house,test_size=0.3, random_state=0)
print ('训练集描述性统计:')
print (house_train.describe().round(2))
print ('验证集描述性统计:')
print (house_test.describe().round(2))
X_train=house_train.ix[:,features_tree]
y_train=house_train.ix[:,'Y']
X_test=house_test.ix[:,features_tree]
y_test=house_test.ix[:,'Y']
##决策树模型训练、评估
from sklearn.tree import DecisionTreeRegressor
#tree = DecisionTreeRegressor(criterion='mse' ,max_depth=4,max_features='sqrt',min_samples_split=2,min_samples_leaf=1,random_state=0).fit(X_train,y_train)
tree = DecisionTreeRegressor(criterion='mse' ,max_depth=None,max_features='sqrt',min_samples_split=2,min_samples_leaf=1,random_state=0).fit(X_train,y_train)
y_tree=tree.predict(X_train)
##特征重要性
print(features_tree)
print ("指标重要性:",tree.feature_importances_)
plt.barh(range(len(tree.feature_importances_)), tree.feature_importances_,tick_label = features_tree)
plt.show()
from sklearn.metrics import mean_squared_error,explained_variance_score,mean_absolute_error,r2_score
print ("决策树模型评估--训练集:")
print ('训练r^2:',tree.score(X_train,y_train))
print ('均方差',mean_squared_error(y_train,tree.predict(X_train)))
print ('绝对差',mean_absolute_error(y_train,tree.predict(X_train)))
print ('解释度',explained_variance_score(y_train,tree.predict(X_train)))
print ("决策树模型评估--验证集:")
print ('验证r^2:',tree.score(X_test,y_test))
print ('均方差',mean_squared_error(y_test,tree.predict(X_test)))
print ('绝对差',mean_absolute_error(y_test,tree.predict(X_test)))
print ('解释度',explained_variance_score(y_test,tree.predict(X_test)))
#print ('R',r2_score(y_test,tree.predict(X_test)))

通过决策树回归得到,X2城镇居民家庭人均可支配收入对Y商品房平均销售价格影响最大,其重要性系数为0.7588,远高于其他因素,与相关系数分析结果一致。
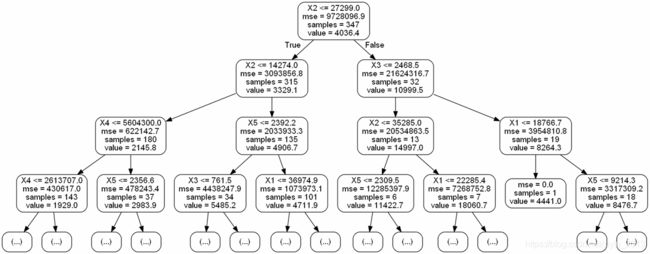
为了解决策树的构建过程,生成可视化决策树。
- 首先运用export_graphviz生成dot文件;
- 然后打开命令提示框,转到graphviz\bin目录,比如D:\Programe Files\graphviz\bin目录;
- 执行dot.exe -Tpng E:\python\Mytest\sklearn\house_tree.dot -o E:\python\Mytest\sklearn\house_tree_20201204.png。
生成可视化决策树,无法显示问题可参见https://blog.csdn.net/weixin_38490102/article/details/79045798。
###生成可视化决策树
# Import tools needed for visualization
from sklearn.tree import export_graphviz
import pydot #pip install pydot
from IPython.display import Image
from sklearn import tree
import sys
import os
tree = DecisionTreeRegressor(criterion='mse' ,max_depth=4,max_features='sqrt',min_samples_split=2,min_samples_leaf=1,random_state=0)
tree=tree.fit(X_train, y_train)
# Export the image to a dot file
export_graphviz(tree, out_file = 'house_tree.dot',max_depth=None,feature_names = features_tree,rounded = True, precision = 1)
print (features_tree)
Step5:对比分析构建的线性回归和决策树回归模型
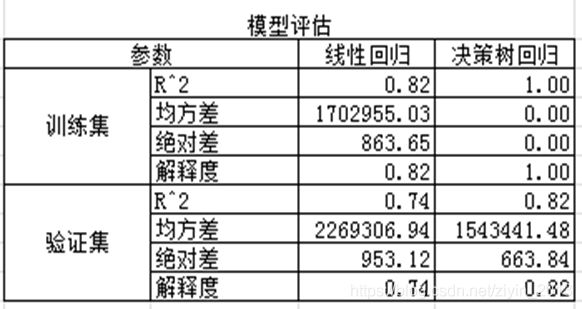
(1)模型评估
根据模型评估参数以及折线图,可以看出决策树回归的效果比线性回归效果好。
##将真实值和预测值画图,便于直观查看模型效果
import matplotlib.pyplot as plt
import matplotlib
#解决画图中中文乱码问题
zh_font = matplotlib.font_manager.FontProperties(fname='C:/Windows/Fonts/simhei.ttf')
###线性回归结果折线图
x=range(len(index))
plt.figure(figsize=(20,10))
plt.plot(house.ix[:,-1].values, label=u'真实值')
#print (reg.predict(house.ix[:,['X1','X2','X3','X4','X5','X6']]))
plt.plot(reg.predict(house.ix[:,['X2','X3','X5','X6']]), label=u'预测值')
#plt.xticks(x,index,fontproperties=zh_font)
plt.legend(prop=zh_font)
plt.title('线性回归',fontproperties=zh_font)
plt.show()
###决策树回归结果折线图
x=range(len(index))
plt.figure(figsize=(20,10))
plt.plot(house.ix[:,-1].values, label=u'真实值')
#print (tree.predict(house.ix[:,['X1','X2','X3','X4','X5','X6']]))
plt.plot(tree.predict(house.ix[:,['X1','X2','X3','X4','X5','X6']]), label=u'预测值')
#plt.xticks(x,index,fontproperties=zh_font)
plt.legend(prop=zh_font)
plt.title('决策树回归',fontproperties=zh_font)
plt.show()


(2)模型预测
用构建的线性回归模型和决策树回归模型分别预测2016年全国各省商品房平均销售价格。
#预测并保存
data_pre=pd.read_csv('datasets\housing_pre.csv',index_col=0,encoding='gb2312')
#print (data_pre)
areas=data_pre[u'地区']
print(areas.values)
y_pre=reg.predict(data_pre.ix[:,features])
print (y_pre)
house_result_reg=pd.DataFrame(areas)
house_result_reg[u'线性回归预测']=y_pre
#print (house_result_reg)
tree_pre=tree.predict(data_pre.ix[:,features_tree])
#print (tree_pre)
house_result_reg[u'决策树回归预测']=tree_pre
house_result_reg[u'真实值']=data_pre['Y']
print (house_result_reg.head())
house_result_reg.to_csv('datasets\house_pred_result.txt',encoding='gb2312')

结合地图直观展示两种模型的预测结果。
#-*- coding: utf-8 -*-
from pyecharts import Map,Grid
import pandas as pd
df=pd.read_csv('datasets/house_pred_result.txt',index_col=0,encoding='gb2312')
print(df.head())
##线性回归预测结果
areas=df.ix[:,0]
values=df.ix[:,1].round(0)
map = Map("全国各省2016年商品房平均销售价格——线性回归", width=1200, height=600)
'''
##决策树预测结果
areas=df.ix[:,0]
values=df.ix[:,2].round(0)
map = Map("全国各省2016年商品房平均销售价格——决策树", width=1200, height=600)
##真实值
areas=df.ix[:,0]
values=df.ix[:,3].round(0)
map = Map("全国各省2016年商品房平均销售价格——真实值", width=1200, height=600)
'''
map.add(
"",
areas,
values,
maptype="china",
is_visualmap=True,
visual_text_color="#000",
is_label_show=True,
is_piecewise=True,
visual_range_text=["", ""],
visual_range=[0, 25000],
#visual_split_number=6,
pieces=[{"max": 30000, "min": 20000, "label": "20000-30000"},
{"max": 20000, "min": 15000, "label": "15000-20000"},
{"max": 15000, "min": 10000, "label": "10000-15000"},
{"max": 10000, "min": 5000, "label": "5000-10000"},
{"max": 5000, "min": 0, "label": "0-5000"},
]
)
map

通过分别构建线性回归模型和决策树回归模型,发现X2城镇居民家庭人均可支配收入对Y商品房平均销售价格影响最大;决策树回归模型效果更好,但是线性回归结果更容易解释,所以在解决实际问题时,往往会对同一份数据构建不同模型,进行综合探索与分析。
ps:初衷是通过撰写博文记录自己所学所用,实现知识的梳理与积累;将其分享,希望能够帮到面临同样困惑的小伙伴儿。如发现博文中存在问题,欢迎随时交流~~