Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering 论文精简翻译
摘要
自顶向下的视觉注意机制已广泛应用于image caption 和 VQA 中。我们提出了一个自底向上和自顶向下相结合的注意力机制,使注意力能够在物体和其他突出的图像区域的水平上进行计算。在我们的方法中,自底向上的机制(基于Faster R-CNN)提取图像区域,每个区域有一个对应的特征向量,而自顶向下的机制确定特征权重。用这个模型我们获得了2017年VQA挑战赛的第一名。
1.介绍
视觉注意机制被广泛应用于image caption和VQA。这一机制通过学习聚焦于图像的突出区域来提高性能。

图1所示。通常,注意力模型在CNN特征上操作,这些特征对应于大小相等的图像区域(左)的均匀网格。我们的方法可以在物体和其他突出的图像区域的水平上计算注意力(右图)。
传统的视觉注意力机制都是自顶向下的,这种机制很少考虑如何确定受注意的图像区域。如图1所示,无论图像的内容如何,最终的输入区域都对应于一个大小和形状都相同的神经接受域的统一网格。为了生成更多类似人类的字幕和问题答案,物体和其他突出的图像区域更应该被关注。
本文提出了一种自底向上与自顶向下相结合的视觉注意机制。自底向上机制提用于取图像区域,每个区域由一个集合的卷积特征向量表示。在实践中,我们使用Faster rcnn 实现了自下而上的注意机制。自顶向下机制使用特定任务的上下文来预测图像区域上的注意力分布。然后将参与的特征向量计算为所有区域的图像特征的加权平均值。
我们评估了自底向上和自顶向下相结合对两个任务的结果。我们首先实现了一个image caption模型,该模型在字幕生成过程中多次捕捉图像的显著区域。实证研究发现,自下而上注意力的包含对image captio有显著的积极作用。我们还使用了相同方法,实现了一个VQA模型。使用该模型,我们获得了2017年VQA挑战赛的第一名。代码,模型和预先计算的图像功能可从项目网站(http://www.panderson.me/up-down-attention) 下载。
3.方法
给定一个图像I,我们的image caption模型 和 我们的VQA模型都将大小可变的k个图像特征集作为输入, V = v 1 , . . . , v k , v i ∈ R V={v_1,...,v_k ,vi \in R} V=v1,...,vk,vi∈R,使得每个图像特征对图像的一个显著区域进行编码。空间图像特征V可以定义为我们自底向上注意力模型的输出,也可以按照标准做法定义为CNN的空间输出层。在3.1节中描述了实现自底向上注意力模型的方法。在第3.2节中,我们概述了图像字幕模型的架构。在第3.3节中,我们概述了VQA模型。
3.1 自底向上的注意模型
空间图像特征V的定义是通用的。然而,在这项工作中,我们根据边界框定义空间区域,并使用Faster R-CNN实现自下而上的注意力。Faster R-CNN是一个对象检测模型,用于识别对象的类别并且用边框定位对象在图片中的位置。其他 region proposal networks 也可以训练成一种注意力机制。
在这项工作中,我们将Faster R-CNN与ResNet-101 结合使用。为了生成用于image caption或 VQA 的图像特征的输出集 V,我们获取模型的最终输出,并使用IoU阈值对每个对象类别执行非最大抑制。然后,我们选择所有类别检测概率超过置信度阈值的所有区域。对于每个选定区域i,vi被定义为该区域的平均池化卷积特征,因此图像特征向量的维D为2048。
为了预训练 bottom-up attention 模型,我们首先使用ResNet-101在ImageNet上预训练用于分类的Faster R-CNN。然后我们使用 Visual Genome 数据进行训练。为了学习良好的特征表示,我们添加了一个额外的训练输出来预测属性类(除了对象类之外)。为了预测区域i的属性,我们将平均池化卷积特征 vi 与学习到的真值(ground-truth )对象类的嵌入连接起来,并将其输入到附加的输出层中,从而定义每个属性类和“无属性”类的softmax分布。
原始的Faster R-CNN多任务损失函数包含四个组件,分别定义了RPN和对象分类和边界框回归输出。我们保留了这些组件,并添加了一个额外的多类损失组件来训练属性预测器。在图2中,我们提供了一些模型输出的示例。

图2。模型输出的示例。每个边界框都用一个属性类和一个对象类来标记。但是请注意,在image caption 和 VQA中,我们只使用特征向量,而不是预测的标签。
3.2 Image Caption Model
给定一组图像特征V,我们的模型使用现有的部分输出序列作为上下文,使用“软”的自上而下的注意力机制在描述生成过程中对每个特征进行加权。这种方法与以前的模型大致相似。但是,下面概述的特定设计构成了一个相对简单而高性能的基线模型。即使没有自下而上的注意机制,我们的字幕模型仍可以在大多数评估指标上实现与最新技术相当的性能(请参阅表1)。
在较高的层次上,字幕模型使用标准的两个LSTM层组成。在以下各节中,我们将使用以下表示法在单个时间步上引用LSTM的操作:
h t = L S T M ( x t , h t − 1 ) h_t = LSTM(x_t,h_{t-1}) ht=LSTM(xt,ht−1) (1)
其中 x t x_t xt为LSTM输入向量, h t h_t ht为LSTM输出向量。在这里,我们忽略了记忆细胞的传播,以方便标记。现在我们来描述LSTM输入向量 x t x_t xt和输出向量 h t h_t ht的表达式。整个字幕模型如图3所示。
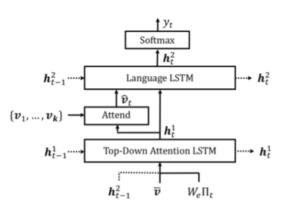
图3。概述Caption model。两个LSTM层用于选择性地关注空间图像特征{v1,…,vk}。这些特征可以定义为CNN的空间输出,或者按照我们的方法,使用自下而上的注意力生成。
3.2.1Top-Down Attention LSTM
在Caption model中,我们将第一个LSTM层描述为自顶向下的视觉注意力模型,而将第二个LSTM层描述为语言模型,并在接下来的等式中使用上标指示每个层。注意,自底向上的注意力模型在3.1节中进行了描述,在这一节中,它的输出被简单地认为是特征V。每个时间步的Attention LSTM的输入向量由LSTM语言模型的前一个输出组成,再加上平均池化的图像特征 $\bar v = \frac{1}{k} \sum_{i} v_i $,以及之前生成的单词的编码,具体如下:
x t 1 = [ h t − 1 2 , v ˉ , W e ∏ t ] x^1_t = [h^2_{t-1},\bar v,W_e \prod_t] xt1=[ht−12,vˉ,We∏t] (2)
其中 W e ∈ R E ∗ ∣ ∑ ∣ W_e \in R^{E*|\sum|} We∈RE∗∣∑∣ 是一个词词汇 ∑ \sum ∑嵌入矩阵,和 ∏ t \prod_t ∏t是一个在t时间的 独热编码输入单词。这些输入分别为LSTM提供有关LSTM语言模型的状态,图像的大概内容以及到目前为止生成的部分描述信息。嵌入单词是从随机初始化中学习而无需预先训练的。
给定Attention LSTM 的输出 h t 1 h^1_t ht1,在每个时间步 t 我们 为每个图像特征 v i v_i vi 生成一个规范化的attention 权重 α i , t \alpha_{i,t} αi,t 如下所示:
a i , t = w a T t a n h ( W v a v i + W h a h t 1 ) a_{i,t} = w^T_a tanh(W_{va}v_i + W_{ha}h^1_t) ai,t=waTtanh(Wvavi+Whaht1) (3)
α t = s o f t m a x ( a t ) \alpha_{t} = softmax(a_t) αt=softmax(at) (4)
其中 W v a ∈ R H ∗ V , W h a ∈ R H ∗ M , w a ∈ R H W_{va} \in R^{H*V} ,W_{ha} \in R^{H*M} , w_a \in R^{H} Wva∈RH∗V,Wha∈RH∗M,wa∈RH是学习到的参数。作为LSTM语言模型输入的图像特征被计算为所有输入特征的凸组合:
v ˉ = ∑ i = 1 k α i , t v i \bar v = \sum_{i=1}^k \alpha_{i,t} v_i vˉ=∑i=1kαi,tvi (5)
3.2.2 LSTM 语言模型
LSTM 语言模型的输入包括有图像特征,并与Attention LSTM的输出相连接,如下所示:
x t 2 = [ v ˉ t , h t 1 ] x^2_t = [\bar v_t,h^1_t] xt2=[vˉt,ht1] (6)
用符号 y 1 : T y_{1 : T} y1:T 表示一个词序列( y 1 , . . . . , y T y_1,....,y_T y1,....,yT),在每个时间步t上可能的输出字的条件分布表示为:
p ( y t ∣ y 1 : t − 1 ) = s o f t m a x ( W p h t 2 + b p ) p(y_t | y_{1:t-1}) = softmax (W_p h^2_t + b_p) p(yt∣y1:t−1)=softmax(Wpht2+bp) (7)
其中 W p ∈ R M ∗ ∣ ∑ ∣ W_p \in R^{M*|\sum|} Wp∈RM∗∣∑∣ , b p ∈ R ∣ ∑ ∣ b_p \in R^{|\sum|} bp∈R∣∑∣分别是学习到的权重和偏置。
完整输出序列上的分布计算为条件分布的乘积:
p ( y 1 : T ) = ∏ t = 1 T p ( y t ∣ y 1 : t − 1 ) p(y_{1:T}) = \prod_{t=1}^T p(y_t|y_{1:t-1}) p(y1:T)=∏t=1Tp(yt∣y1:t−1) (8)
3.2.3 目标
给定一个目标真值序列 y 1 : T ∗ y^*_{1:T} y1:T∗和Caption模型参数 θ \theta θ,我们最小化下面的交叉熵损失:
L X E ( θ ) = − ∑ t = 1 T l o g ( p θ ( y t ∗ ∣ y 1 : t − 1 ∗ ) ) L_{XE}(\theta) = - \sum_{t=1}^T log(p_{\theta}(y_t^* | y^*_{1:t-1})) LXE(θ)=−∑t=1Tlog(pθ(yt∗∣y1:t−1∗)) (9)
为了与最近的工作[33]进行公平的比较,我们还报告了针对苹果酒[42]优化的结果。从交叉熵训练模型初始化,我们寻求最小化负期望分数:
L R ( θ ) = − E y 1 : T ∼ p θ [ r ( y 1 : T ) ] L_R(\theta) = -E_{y_{1:T} \sim p_{\theta}}[r(y_{1:T})] LR(θ)=−Ey1:T∼pθ[r(y1:T)] (10)
其中r是评分函数(比如CIDEr)。按照自临界序列训练(SCST)方法,可以近似得到这种损失的梯度:
Δ θ L R ( θ ) ≈ − ( r ( y 1 : T s ) − r ( y ^ 1 : T ) ) Δ θ l o g p θ ( y 1 : T s ) \Delta_{\theta} L_R(\theta) \approx -(r(y_{1:T}^s) - r(\hat y_{1:T})) \Delta_{\theta} log p_{\theta}(y_{1:T}^s) ΔθLR(θ)≈−(r(y1:Ts)−r(y^1:T))Δθlogpθ(y1:Ts)
其中, y 1 : T s y_{1:T}^s y1:Ts是采样字幕, r ( y ^ 1 : T ) r(\hat y_{1:T}) r(y^1:T)定义了通过贪婪地解码当前模型而获得的基线分数。 SCST(与其他REINFORCE [43]算法一样)通过在训练过程中从策略中采样来探索字幕的空间。该梯度倾向于增加得分高于当前模型得分的采样字幕的可能性。
在我们的实验中,我们遵循SCST,但通过限制采样分布来加快训练过程。使用beam search decoding(波束搜索解码),我们仅从 decoded beam 中的字幕中进行采样。根据经验,我们在使用beam search进行解码时观察到,生成的 beam 通常至少包含一个评分非常高的Caption-尽管该Caption通常不是集合中对数概率最高的。使用这种方法,我们可以在 single epoch内完成CIDEr优化。
3.3 VQA Model
在给定一组空间图像特征V的情况下,我们的VQA模型还使用了一种“软的”自顶向下的注意力机制来对每个特征进行加权,使用问题作为上下文。如图4所示,所提出的模型实现了众所周知的问题与图像的联合多模态嵌入,然后对一组候选答案的得分进行回归预测。这种方法是许多模型的基础[16,20,38]。但是,与我们的Caption模型一样,这个模型具有高性能关键在于实现决策。

图4。VQA模型概述。深度神经网络实现了问题与图像特征{v1,…,vk}的联合。这些特征可以定义为CNN的空间输出,或者按照我们的方法,使用自下而上的注意力生成。输出是由一个多标签分类器在一组固定的候选答案上操作产生的。灰色数字表示层之间向量表示的维数。黄色元素是学习参数。
网络内学习到的非线性变换通过门控双曲正切激活来实现。这是Highway network的特例(Highway networks. arXiv preprint arXiv:1505.00387v1, 2015.) ,与传统的ReLU或tanh层相比,它们显示了强大的经验优势。每一个‘gated tanh’通过函数实现 f a : x ∈ R m → y ∈ R n f_a: x ∈ R_m → y ∈ R_n fa:x∈Rm→y∈Rn 参数是 a = {W,W′,b,b′} 如下所示:
y ^ = t a n h ( W x + b ) \hat y = tanh(W_x + b) y^=tanh(Wx+b) (12)
g = σ ( W ′ x + b ) g = \sigma(W^′x + b) g=σ(W′x+b) (13)
y = y ^ o g y = \hat y o g y=y^og (14)
其中 $ \sigma $是 sigmoid 激活函数 w, W ′ ∈ R n × m W^′∈R^{n×m} W′∈Rn×m是学习权重,b, $b′∈Rn 是 学 习 偏 置 , 是学习偏置, 是学习偏置, o 是 H a d a m a r d ( e l e m e n t − w i s e ) 乘 积 。 向 量 g 充 当 中 间 激 活 是Hadamard (element-wise)乘积。向量 g 充当中间激活 是Hadamard(element−wise)乘积。向量g充当中间激活\hat y$的门控
我们提出的方法首先将每个问题编码为一个门控递归单元5的隐藏状态q,每个输入字用一个学习字嵌入表示。与等式3相似,给定GRU的输出q,我们对k个图像特征 v i v_i vi分别生成一个未归一化的注意权重 a i a_i ai,如下所示:
a i = w a T f a ( [ v i , q ] ) a_i = w_a^T f_a([v_i,q]) ai=waTfa([vi,q]) (15)
其中 w a T w_a^T waT 是一个学到的参数向量。方程方程4和5(忽视下标t)用于计算归一化的attention 权重 和图像特性 v ^ \hat v v^。y的分布可以如下表示:
h = f a ( q ) o f v ( v ^ ) h = f_a(q) o f_v(\hat v) h=fa(q)ofv(v^) (16)
p ( y ) = σ ( W σ f o ( h ) ) p(y) = \sigma(W_{\sigma}f_o(h)) p(y)=σ(Wσfo(h)) (17)
其中h是问题和图像的联合表示, W o ∈ R ∣ ∑ ∣ ∗ M W_o \in R^{|\sum|*M} Wo∈R∣∑∣∗M 是学习到的权重。
由于篇幅所限,此处未详细介绍VQA方法的一些重要方面。有关VQA模型的完整说明,包括对体系结构和超参数的详细探讨,请参阅Teney等。
评估
4.1 Datasets
4.1.1 Visual Genome Dataset
我们使用Visual Genome [21]数据集来预训练bottom-up attention模型,并在训练VQA模型时进行数据增强。数据集包含108K张图像,其中密集地标注了包含对象,属性和关系的场景图以及170万个视觉问题。
为了预训练自下而上的注意力模型,我们仅使用对象和属性数据。我们保留5K图像用于验证,并保留5K图像用于将来的测试,将其余的98K图像视为训练数据。由于在MSCOCO字幕数据集中也发现了大约51K视觉基因组图像,因此我们要小心避免污染MSCOCO验证和测试集。我们确保在两个数据集中找到的所有图像都包含在两个数据集中的同一拆分中。
由于对象和属性注释是大量的字符串,因此我们对训练数据进行了广泛的清理和过滤。从2,000个对象类和500个属性类开始,我们手动删除在初始实验中表现出较差检测性能的抽象类。我们的最终训练集包含1600个对象类和400个属性类。请注意,我们不会合并或删除重叠的类(例如“ person”,“ man”,“ guy”),具有单数和复数版本的类(例如“ tree”,“ trees”)以及难以精确定位的类(例如“天空”,“草”,“建筑物”)。
在训练VQA模型时,如果模型的答案词汇表中存在正确的答案,我们会使用Visual Genome问题和答案对来扩充VQA v2.0训练数据。这代表了大约30%的可用数据或485K问题。
4.1.2 Microsoft COCO Dataset
为了评估我们提出的Caption模型,我们使用了MSCOCO 2014字幕数据集[23]。为了验证模型超参数和精细测试,我们使用了“ Karpathy”分割[19],该分割已广泛用于报告以前的工作结果。此拆分包含113287个训练图像,每个训练图像带有五个标题,分别包含5K图像用于验证和测试。我们的MSCOCO测试服务器提交内容在整个MSCOCO 2014培训和验证集(123K图像)上进行了培训。
我们遵循标准惯例,仅执行最少的文本预处理,将所有句子转换为小写字母,在空白处进行标记,并对至少五次没有出现的单词进行过滤,从而产生10,010个单词的模型词汇。要评估字幕质量,我们使用标准的自动评估指标,即SPICE [1],CIDEr [42],METEOR [8],ROUGE-L [22]和BLEU [29]。
4.1.3 VQA v2.0 Dataset
为了评估我们提出的VQA模型,我们使用了最近引入的VQA v2.0数据集[12],该数据集试图通过平衡每个问题的答案来最小化先验学习数据集的有效性。该数据集用作2017年VQA挑战2的基础,包含110万个问题以及与MSCOCO图像有关的1,110万个答案。
我们执行问题文本预处理和标记化。为了提高计算效率,问题被修整到最多14个单词。候选答案集仅限于训练集中出现超过8次的正确答案,因此输出词汇量为3,129。我们的VQA测试环节在训练集和验证集以及Visual Genome的其他问题和答案上训练。为了评估答案的质量,我们使用标准的VQA指标[2]报告了准确性,该指标考虑了注释者之间对于真值答案的分歧。
4.2 ResNet Baseline
为了量化bottom-up attention 模型的影响,在caption和VQA实验中,我们根据先前的工作以及消减后的基准评估了完整模型。在每种情况下,基线(ResNet)都使用在ImageNet上经过预训练的ResNet CNN来编码每个图像,以代替自下而上的注意力机制。
在Image Caption实验中,我们使用Resnet-101的最终卷积层对完整尺寸的输入图像进行编码,并使用双线性插值将输出尺寸调整为固定大小的10×10空间表示。这等于我们提出的模型中使用的最大空间区域数。在VQA实验中,我们使用ResNet-200 [14]对调整后的输入图像进行编码。在单独的实验中,我们使用评估将空间输出的大小从其原始大小14×14更改为7×7(使用双线性插值)和1×1(即不注意的平均池)的效果。
4.3 Image Captioning Results
在表1中,我们报告了我们的完整模型和ResNet基线的性能,并将其与目前最先进的自临界序列训练33方法进行了比较。为了公平的比较,报告了用标准交叉熵损失训练的模型和为苹果汁优化的模型的结果。注意,SCST方法使用ResNet-101编码的完整图像,类似于我们的ResNet基线。所有结果都报告了一个单独的模型,没有对输入ResNet / R-CNN模型进行微调。然而,SCST结果是四个随机初始化中的最佳结果,而我们的结果是单个初始化的结果。
与SCST模型相比,我们的ResNet基线在交叉熵损失下的性能稍好,而在CIDEr评分时的性能稍差。在合并自底向上的注意力之后,我们的整个Up-Down模型显示了所有指标的显著改进,而不管使用的是交叉熵损失还是CIDEr优化。仅使用一个单一的模型,我们获得了最好的卡氏病检测分离的报告结果。如表2所示,自底向上注意力的贡献是广泛的,通过在识别对象、对象属性以及对象之间的关系方面的改进性能来说明。
表3报告了在官方MSCOCO评估服务器上使用 CIDEr 优化训练的4个集成模型的性能,以及之前发布的最高排名结果。在提交时(2017年7月18日),我们在所有报告的评估指标上都优于所有其他测试服务器提交。
4.4. VQA Results
在表4中我们报告我们完整的Up-Down VQA 模型的单一模型的性能相对于几个ResNet基线VQA v2.0验证集。新增的自底向上的注意提供最好的ResNet基线显著提高所有问题类型,即使ResNet基线使用大约两倍的卷积层。表5报告了官方VQA 2.0测试标准评估服务器上30个集成模型的性能,以及之前发布的基线结果和其他排名最高的条目。在提交时(2017年8月8日),我们的表现优于所有其他测试服务器提交。我们的作品也获得了2017年VQA挑战赛的第一名。
4.5. Qualitative Analysis
为了帮助定性地评估我们的注意力方法,在图5中,我们将上下字幕模型生成的不同单词的参与图像区域可视化。正如这个例子所示,我们的方法同样能够聚焦于精细的细节或大的图像区域。之所以会出现这种能力,是因为我们的模型中的候选注意力区域由许多具有不同尺度和长宽比的重叠区域组成——每个区域与一个对象、几个相关对象或一个突出的图像块对齐。
与传统方法不同的是,当一个候选注意区域对应于一个对象或几个相关对象时,所有与这些对象相关的视觉概念似乎都在空间上处于同一位置,并一起处理。换句话说,我们的方法能够同时考虑与一个对象相关的所有信息。这也是注意力得以实现的一种自然方式。在人类视觉系统中,将物体的单独特征以正确的方式组合起来的问题被称为特征绑定问题,实验表明注意力在解决问题中起着核心作用[40,39]。我们在图6中包含了一个VQA注意的例子。
5. Conclusion
我们提出了一种新颖的自下而上和自上而下的视觉注意力结合的机制。我们的方法可以使注意力在对象和其他显着区域的层次上更自然地计算出来。将这种方法应用于图像字幕和视觉问题回答,我们可以在两个任务中都获得最先进的结果,同时提高了结果注意力权重的可解释性。从较高的层次上讲,我们的工作将涉及视觉和语言理解的任务与物体检测的最新进展更加紧密地统一在一起。尽管这为将来的研究提出了一些方向,但我们的方法的直接好处可能是通过简单地将预训练的CNN功能替换为预训练的自下而上的注意力特征来捕获的。致谢本研究得到澳大利亚政府研究培训计划(RTP)奖学金,澳大利亚研究理事会机器人视觉卓越中心(项目编号CE140100016),Google颁发的“自然语言理解重点计划”的部分资助,并获得了部分资助。澳大利亚研究委员会探索项目资助计划(项目编号DP160102156)。