【李宏毅机器学习2021】Task04 深度学习介绍和反向传播机制
【李宏毅机器学习2021】本系列是针对datawhale《李宏毅机器学习-2022 10月》的学习笔记。本次是对深度学习介绍和反向传播机制的学习总结。本节针对上节课内容,对batch、梯度下降方法进行讲解。通过本次学习加深了对optimization方法的理解,同时明白对深度学习的优化方向和解决办法。
= =原本17年的视频将bp来着,到21年视频里么有找到bp的。把之前将loss的过完了,和题目出入较大。后面把bp的视频和笔记补上,其实第二次笔记已经写了BP相关的逻辑。
深度学习介绍和反向传播机制
Batch 和 Moentum
batch

之前的学习中也提到在训练中,对数据进行划分,每一个batch进行一次梯度下降算一次loss。这次将对数据进行划分成块的方法进行讲解,了解batch如何分,分多了有什么好处,有什么坏处。
这里举两个极端的例子,比如将所有数据分成一个batch。或者对每个单独的数据作为一个batch。


直觉上看:
对于分成一个batch ,需要很久时间梯度下降,每次优化后效果很显著。
对于分成N个batch(数据量为N) ,需要很短时间就可以更新一次loss,但是优化会有噪声。

事实上相对大一点的batch训练时间也很快。因为存在并行计算,通过GPU进行加速。速度其实差不多。
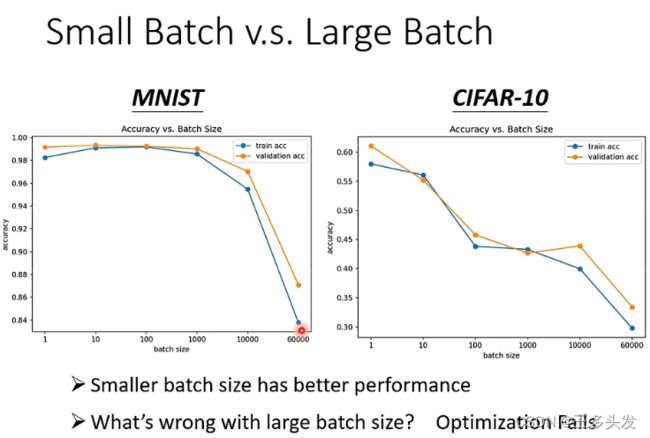
在两个常用数据集上,其实batch更小反而对模型的准确度提升更小。上图时在train中的效果。
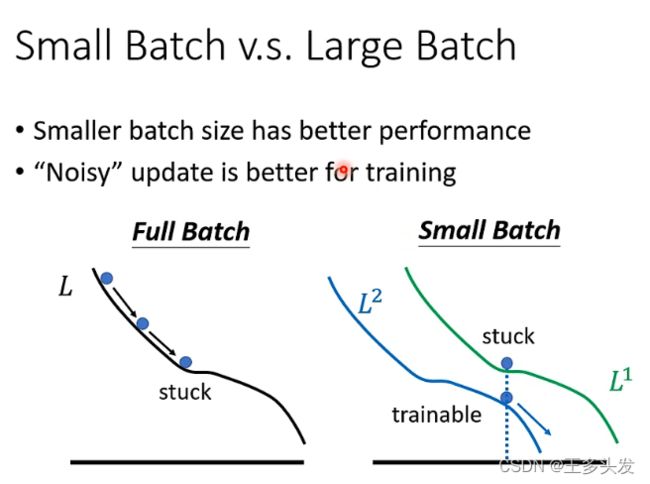

当在训练集上达到一定效果后,在测试集上其实用小的batch效果也会更好。
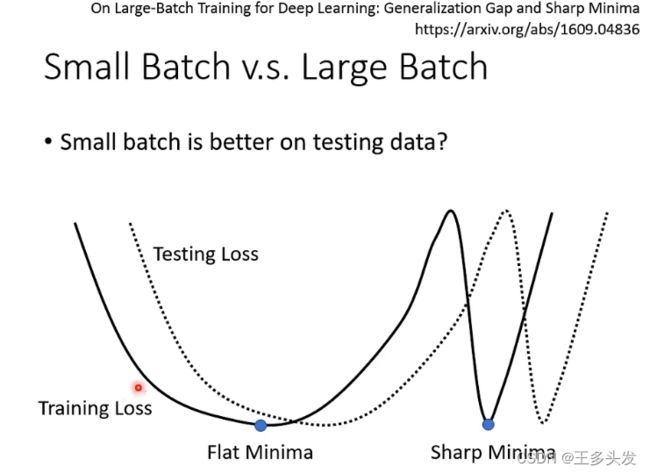
这里解释一下原因:
因为数据在梯度下降中,采用大的batch,对所有训练的数据进行平均后因为噪音被弱化,容易计算出的loss都掉到一个区域,在噪音loss影响的情况下求出来的局部最优点可能落在更陡峭的谷里。在验证时数据的情况在概率上讲落在相对平缓的谷中比陡峭的谷中概率更大,所以用更小的batch表现更好。
最终的对比情况:

训练速度性能兼顾的方法:

Momentum
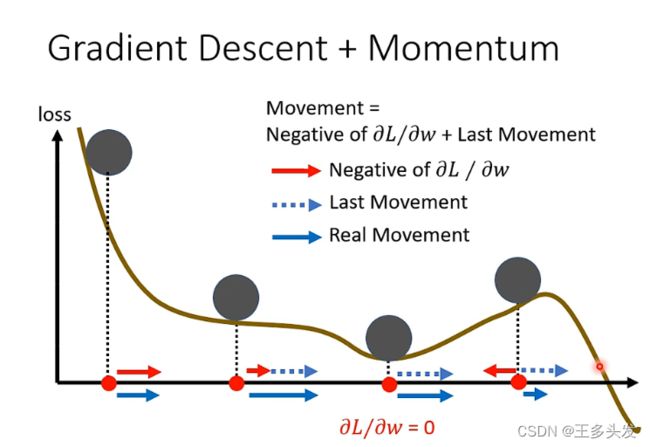
由于训练时采用梯度下降方法会掉到鞍点里或者localmax点,如何摆脱这样的问题呢?这里把目光放到真实的物理世界,如果一个小球在滚动,如果有个小坑由于惯性很容易越过。可以把惯性加到梯度下降里吗?这就是Momentum。
这里是梯度下降方法,主要是对每次梯度下降的方向进行优化。

这里是加了惯性思路的方法,针对上一次的运动和梯度下降方向做了综合。

LearningRate
loss很低梯度真的会变成0吗?
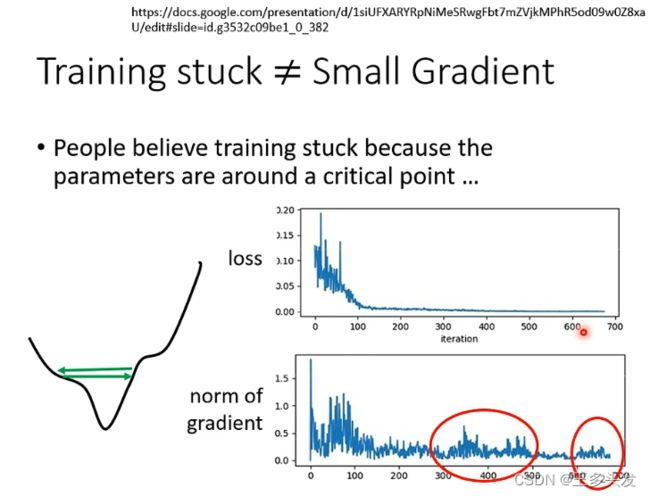
有的时候loss不在下降,但是实际上梯度并不会变成0。甚至会反而反弹。这是为什么呢?
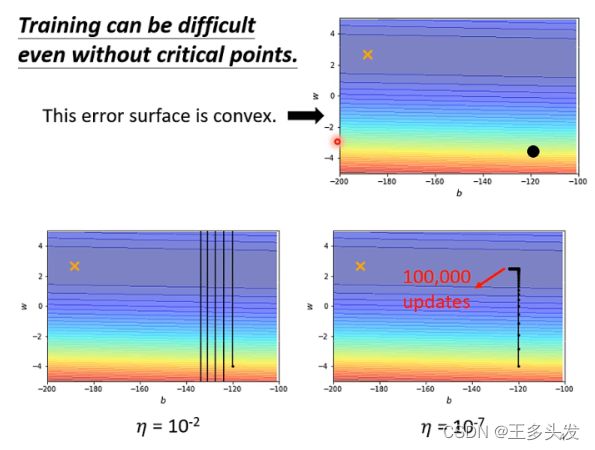
因为学习率设置太高的问题,训练到一定程度找不到梯度下降的位置。比如最简单的convex问题,采用正常的梯度下降方式也找不到局部最优解。
为了更合理安排学习率,让每个参数的学习率对于训练的参数都找到一个合适的值,应该对每个参数的学习率进行单独更新。同时对每次梯度下降更新时,让lr受先前梯度下降的控制,在梯度梯度变化后期(梯度下降的次数越多影响越明显)控制梯度下降更缓慢,采用更小的lr。同时对于更陡峭的变量,会因为梯度下降趋势越大,后续的更新就比较小,会更容易找到局部最优。
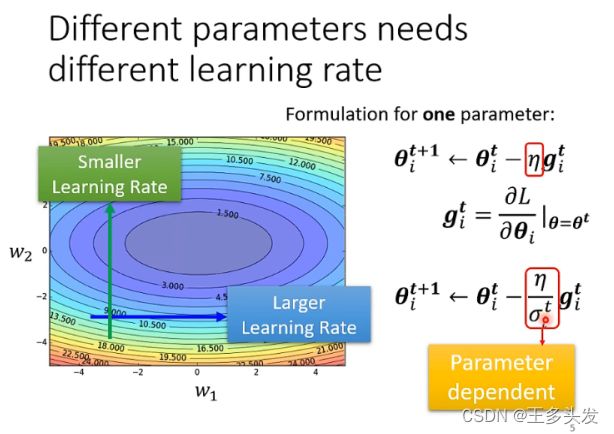

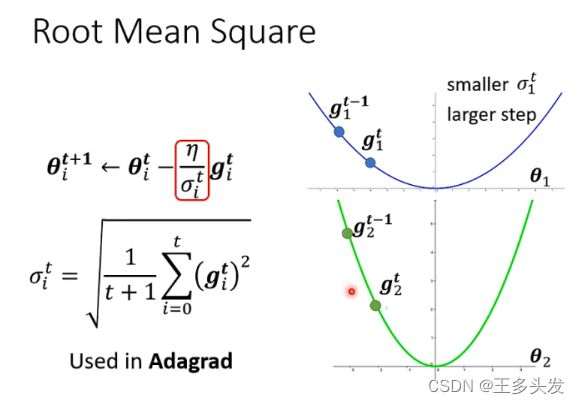
RMSProp &adam
但是当上述调整lr的方式遇到需要从大lr调小再调大这样的情况比较困难,所以对调整方法进行更新。这里将更新中采用先前梯度情况和目前梯度进行平衡化调整。通过这样的调整,改变学习率,让学习率更灵活的变化。这就是RMSProp方法。

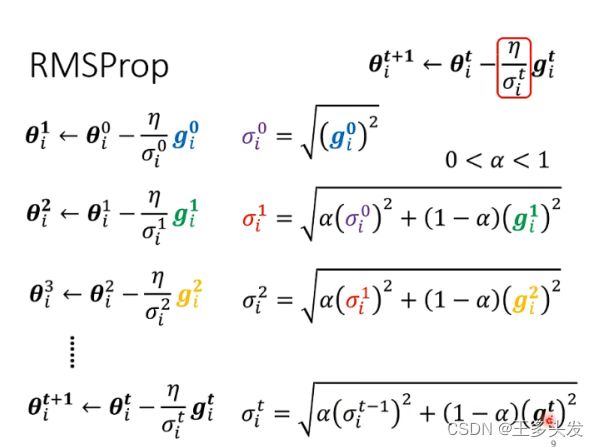


通过RMSProp和Momentum组合就是adam
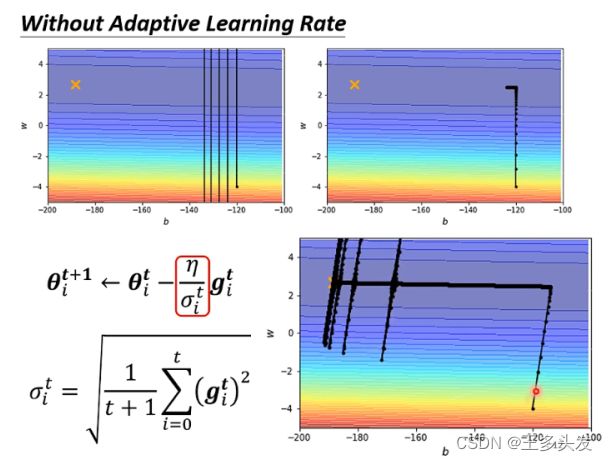
可以看到找到最终的梯度最低的点,但是会出现梯度爆炸的问题。这里也需要对opt方法进行优化。
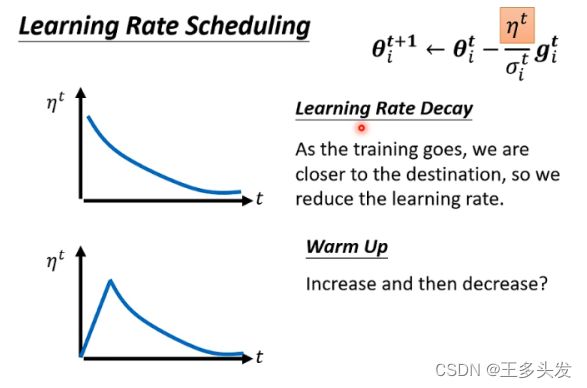
这里将学习率和时间做了负相关,当训练时间越久,学习率应该控制的更小。在这里也引入了一个方法是warm up 。这个方法和学习率有关,但是也和之前的认知有些出入。就是对刚开始的学习率应该逐渐上升,到一定值应该让学习率随时间降低。(黑科技~)

OPT总结:

采用Momentum和RMSProp组合的方法,同时增加wormup方法调整学习率。这里有同学可能会问,σ和m一个在分子一个在分母有没有互相抵消的意思。因为σ是一个标量,代表的是学习率的大小控制。而m是矢量,有方向同时会受先前g的方向控制。通过以上方法对opt进行优化,越过鞍点,学习率变化稳定而且可以又快有好的找到局部最优解。
分类
这里是对分类任务的一个简单概述,讲讲分类中的one-hot,分类中的损失函数如何选择。
one-hot
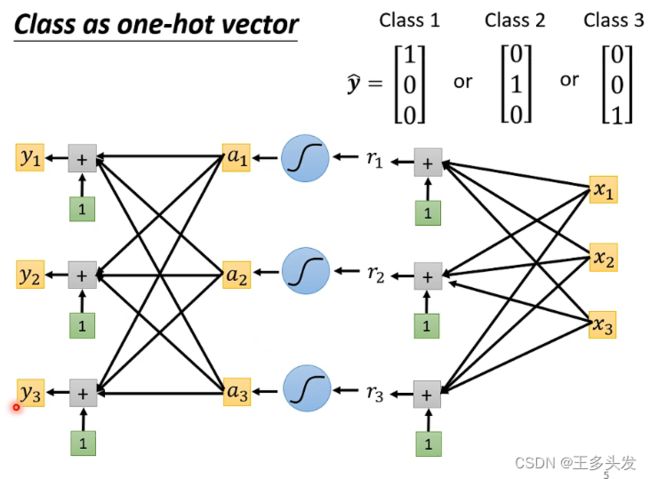
one-hot编码是什么?就是对数据分类的标签再进行调整,将某个类表示成一个列向量。
为什么要用one-hot编码?因为机器学习的输出结果如果采用数字大小去表示的话非常不合理,每个类别并不是按照从小到大的顺序去表示。而采用向量的更新,更容易将训练得到的数据分类。
Softmax
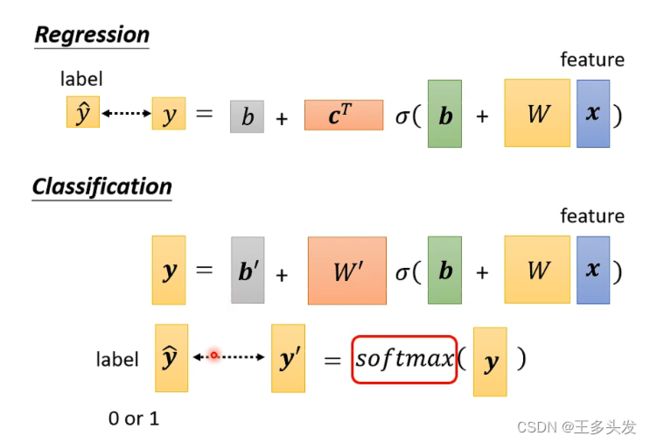
这里还有一个要注意的点,对模型的输出要进行一次softmax。
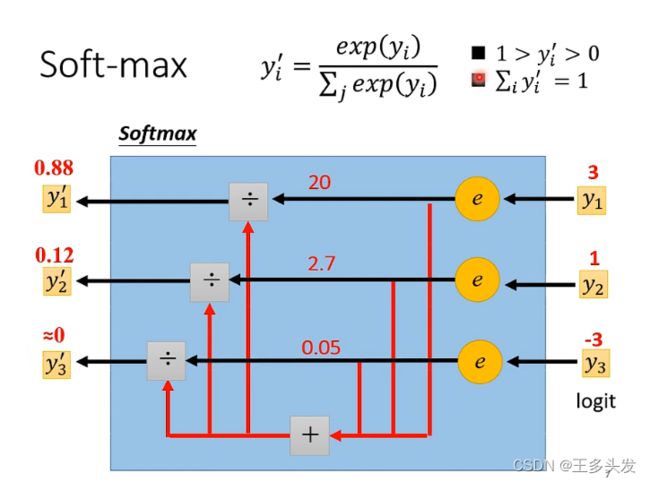
softmax是对模型输出的数据进行归一化,控制输出数据范围在0-1。保证符号同时将数据控制在0-1便于计算。
Cross-entropy
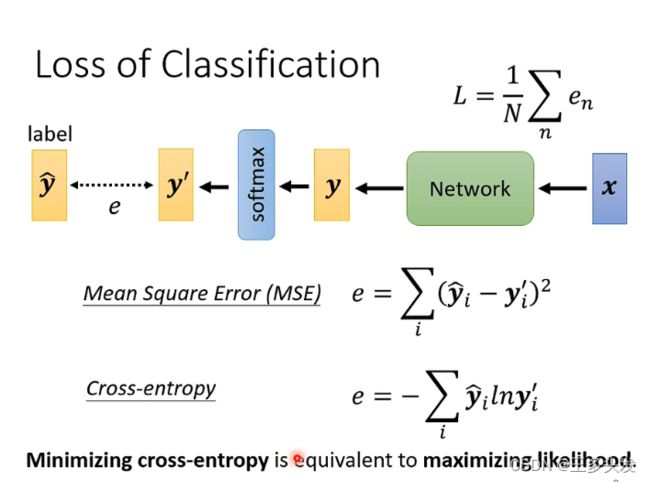
交叉熵损失函数,相比于MSE的评估方法再多分类问题上更加平滑。

【学习总结】完成了第四次打卡咯。已经跨过一半的学习时间啦~~继续坚持吧~