3D目标检测(一)
【用心写文章分享尤其是经验之谈不容易,引用和转载请说明出处以尊重原创作者的劳动,前面发现有几个人居然偷本人文章上传到百度文库赚钱!再有这样的贼我必追究!】
加入自动驾驶行业有一段时间了,对积累的知识做记录也供日后备查同时也是做知识分享。
做3D目标检测,首先要了解雷达坐标系和相机坐标系这两个坐标系和数据标注等方面的基础,下面结合kitti3D数据集来讲解。kitti数据集在3D目标检测领域有点类似PASCAL VOC和COCO在2D目标检测和分割领域的经典地位,数据量不算很大,各类别数量很不均衡,但是很多模型要刷榜和发论文都用这个数据集,它里面同时提供了2d和3d目标标注,还有分割和跟踪等数据挺全的,所以用于模型实验和验证以及准备发论文还是挺不错的。kitti官网The KITTI Vision Benchmark Suite提供了雷达和相机以及GPS/IMU等传感器的详细位置和角度等参数,看了下面这两张图后才有了对其标注数据理解的基础:
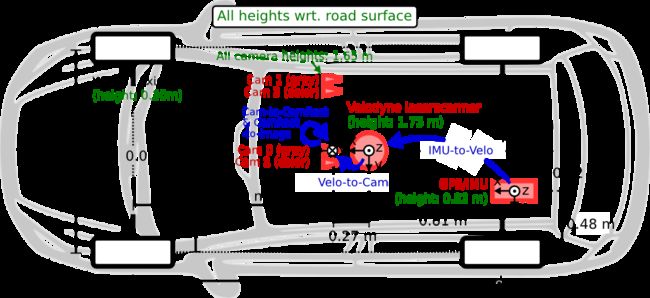

两张图里都将相机坐标系和激光雷达坐标系粗略地画了一下,没了解过两种坐标系的可能还是不大明白,《Vision meets Robotics: The KITTI Dataset》这篇论文里也大概地提了一下雷达坐标系和此坐标系下目标的宽和长以及旋转角rz(有的也把它叫偏航叫yaw,这里只是借用偏航这个概念而已,这里是绕z轴旋转,和笛卡尔右手坐标系下的绕y轴旋转的yaw角不一样,即使相机坐标系下的旋转角/偏航角是绕y轴旋转的,但相机坐标系下的y轴的正向是向下的,和笛卡尔右手坐标系下的y轴正向是向上的相反)
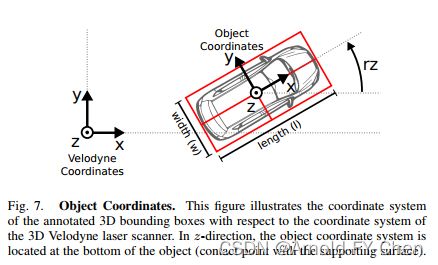

上面这些可能看完后对两个坐标系和目标的宽、长、和高等定义还是很迷糊,所以我参考网上资料理解透彻后画了一下图便于理解和记忆:
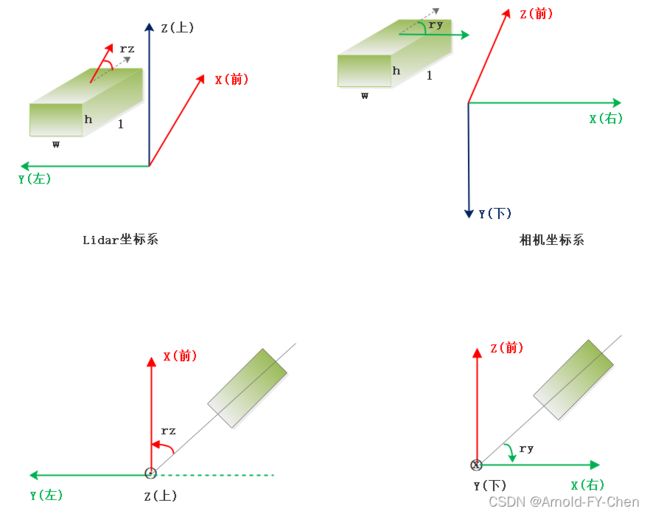
长、宽、高在不同的坐标系下的值是一样的,单位是米,长宽高在激光雷达坐标系下对应的是x轴、y轴和z轴方向的长度值,而在相机坐标系下对应的是z轴、x轴和y轴方向的长度值,记住这点很重要,对根据目标的中心点(x,y,z)计算其8个角点时是需要用到这些的。rz是激光雷达坐标系下目标的前进方向和x轴的夹角,逆时针方向为正,弧度值范围是[-pi, pi];ry是相机坐标系统下目标的前进方向和x轴的夹角,顺时针方向为正,弧度值范围是[-pi, pi]。有人喜欢列出rz和ry之间的换算公式,其实我觉得那公式是错误的!只适用于一种象限,旋转角落在不同象限时是不同的!需要换算时画个图然后看是需要从哪种坐标系下的旋转角换算成哪种坐标系下的旋转角分开写一下换算等式就好,根本不用去死记也记不住的!另外,kitti数据采集还涉及到了GPS/IMU坐标系统,方向和lidar坐标系是一样的,只是传感器的安装位置差异而已,三种坐标系之间的任意两种坐标系之间需要进行转换时采用对应的calibration文件里的参数进行坐标转换。
另外顺带多说一句,相机坐标系和右手笛卡尔坐标系很像,x轴是完全一致的,只是y轴和z轴和右手笛卡尔坐标系下相比都是反过来的,因此相机坐标系下ry是绕y轴旋转,说成是yaw角当然可以(右手笛卡尔坐标系下,绕x轴旋转的俯仰角叫pitch(以飞机为例,战斗机俯冲和拉起时的俯仰角),绕y轴旋转的偏航角叫yaw(战斗机转向加桶滚动作快速脱离原来航线时的偏航角),绕z轴旋转的滚转角叫roll(战斗机做桶滚动作时的滚转角))。
下载object development kit,![]() 可以看里面的readme.txt里说明了kitti数据集的标注文件里每列的定义:
可以看里面的readme.txt里说明了kitti数据集的标注文件里每列的定义:
#Values Name Description
----------------------------------------------------------------------------
1 type Describes the type of object: 'Car', 'Van', 'Truck',
'Pedestrian', 'Person_sitting', 'Cyclist', 'Tram',
'Misc' or 'DontCare'
1 truncated Float from 0 (non-truncated) to 1 (truncated), where
truncated refers to the object leaving image boundaries
1 occluded Integer (0,1,2,3) indicating occlusion state:
0 = fully visible, 1 = partly occluded
2 = largely occluded, 3 = unknown
1 alpha Observation angle of object, ranging [-pi..pi]
4 bbox 2D bounding box of object in the image (0-based index):
contains left, top, right, bottom pixel coordinates
3 dimensions 3D object dimensions: height, width, length (in meters)
3 location 3D object location x,y,z in camera coordinates (in meters)
1 rotation_y Rotation ry around Y-axis in camera coordinates [-pi..pi]
1 score Only for results: Float, indicating confidence in
detection, needed for p/r curves, higher is better.kitti用于训练的标注文件里的数据是前15列,score这种得分很显然只有推理测试时才有:
type truncated occluded alpha left top right bottom height width length x y z rotation_y
类似下面这样:
Car 0.60 3 -2.42 0.00 185.93 214.05 348.86 1.56 1.57 4.37 -6.96 1.73 7.83 -3.13
Car 0.00 1 -2.73 57.68 178.66 341.72 285.91 1.65 1.68 3.88 -6.88 1.77 12.36 3.05
Car 0.00 2 0.40 133.20 154.23 386.37 263.44 2.08 1.80 4.37 -7.14 1.75 14.97 -0.04
Cyclist 0.00 0 1.66 501.01 178.40 523.53 228.03 1.59 0.58 1.69 -3.29 1.78 24.09 1.53
Car 0.84 0 -0.75 1094.88 190.09 1241.00 374.00 1.54 1.75 3.36 6.04 1.68 5.65 0.04
Car 0.19 3 -0.57 934.82 184.38 1241.00 326.25 1.48 1.52 3.33 5.79 1.63 8.47 0.01
Car 0.00 2 -0.56 882.79 183.25 1122.39 291.95 1.50 1.58 2.81 5.88 1.68 11.09 -0.08
Car 0.00 2 2.68 800.16 181.42 1050.12 273.59 1.57 1.68 3.97 5.77 1.75 13.60 3.08如果不按truncated和occluded挑选难易数据和不计算2d boxes的AP值,type后的7列就没什么用(对于alpha角,平时根本用不着,它叫观察角度, 弧度取值范围为:-pi -- pi,它表示在相机坐标系下,以相机原点为中心,相机原点到物体中心的连线为半径,将物体绕y轴旋转至z轴后物体前进方向与x轴的夹角),所以一般如果是自己制作基于lidar坐标系下的数据的数据集的话,可以仿照上面的数据顺序摆放,但是type后的7列全是0,当然(x,y,z,yaw)是lidar坐标系下的值,而不是像kitti这样是相机坐标系下的值,另外,对于长宽高的值,特别需要注意的是,3D目标检测模型输入输出数据中的顺序可能是w,l,h这样顺序摆放的,如果本身数据是基于lidar坐标系的,只是按kitti数据集的规则按h,w,l顺序摆放的,那么在读取数据后需要借助numpy array或者torch tensor的通过索引调整数据顺序功能来把顺序调整过来,对于直接使用kitti3D数据来训练模型,则是在读取相机坐标系下的数据后通过相机坐标系到雷达坐标系的转换函数来统一转换成雷达坐标系下的数据后送入模型预处理部分。对于旋转角也是这样,如果是雷达坐标系下的数据,直接读取数据不用做任何转换,如果是相机坐标系下的旋转角数据,需要转换成雷达坐标系下的旋转角数据后再同其他location和dimension数据一起送入模型预处理部分。
如果是直接使用kitti3D数据集训练3D目标检测模型,只需从这里下载下列left color images、Velodyne point clounds、camera calibration matrics和training labels四个文件压缩包后并按指定层次结构解压后按training和testing分开合并后即可:
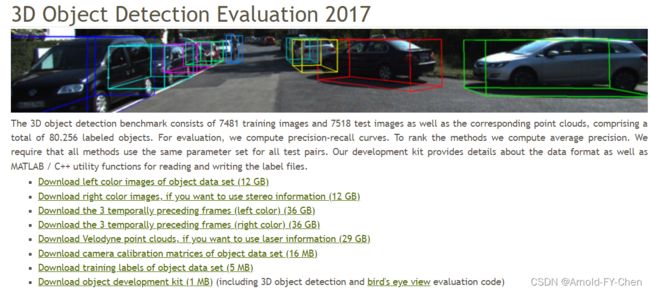
The data for training and testing can be found in the corresponding folders.
The sub-folders are structured as follows:
- image_02/ contains the left color camera images (png)
- label_02/ contains the left color camera label files (plain text files)
- calib/ contains the calibration for all four cameras (plain text file)
类似使用PASCAL VOC那样,和training同一层再加个ImageSets目录,里面存放train.txt、val.txt和trainval.txt以及test.txt即可,这些数据划分文件里存放的都是文件的名字列表: 000000、000001、....,那么image文件、点云bin文件、calibration文件和标注txt文件的名字都是这样的数字,四种文件之间用靠用同一名字(不同后缀)来保持一一对应的关系。

数据进模型前的预处理部分也许还需要进行一些简单预处理,例如按照pc_range参数(例如kitti3D提供的默认pc_range参数是[0,-39.68,-3,69.12,39.68,1])进行范围过滤去掉范围之外的点云数据(也叫去掉背景),再就是将数据存入文件数据库,如果是模型推理可能还要求将点云文件按照指定的维度reshape(例如拍扁成1维)后存放到对应的文件里。
如果自己的模型里的结果评估需要自己实现,可以 下载object development kit参考里面的实现,:
![]()
它这个代码实现当然时基于相机坐标系的,所以识别结果被从雷达坐标系下的数据转换成了相机坐标系下的数据,然后和kitti的标注数据做2d和3d 和bev下的bbox的IOU计算并统计P/R和计算AP和mAP,也就是说,如果使用kitti3D数据做点云目标检测模型训练,数据输入模型前需要由相机坐标系转换成lidar坐标系,模型输出的结果数据要由lidar坐标系转换成相机坐标系,然后才能和kitti3D的标注数据去做IOU计算(如果时推理,这部分一般放在后处理中,如果是训练,一般是模型输出数据和加载在内存中的已转换坐标的数据做计算),如果时自始至终都是使用雷达坐标系,显然不用转换了,模型输出数据直接和标注数据去做IOU计算即可,可见省事多了。另外要注意的是,kitti3D的标注中物体的location (x,y,z)是指的物体的3d box的底面的中心,不是物体的几何中心哦!如果是我们自己标注和制作数据集,一般这个值都是直接指物体的3d box的几何中心,有的标注工具甚至指的是物体的3d box的某个角点!所以在使用这个中心点加上dimension数据计算物体的3d box的8个角点时要注意这个差别,不然可能得出错误的结果,通过可视化可能可以看到画出的3d box总是没有正确套到物体上,这个原因多是因为没有注意所用的数据集里标注的物体中心点到底指的哪里造成的!
如果做自动驾驶行业,自己上路采集和标注制作基于相机坐标系的数据集,那么类似calibration这样的参数也是需要记录和定期校验的,如果是基于雷达坐标系采集和标注制作数据集,则不用这么麻烦,这些参数都可以不要,一般常用的3D目标检测模型使用基于雷达坐标系的数据的多,因此自数据采集和标注到模型训练和预测自始至终采用雷达坐标系,就不用转来转去的那么麻烦,节省了大量时间。