技术 | 图像动作驱动-First Order Motion Model 解读
first-order 这篇文章做的是image animation,不知道怎么翻译比较合适,就是以一段driving video 去驱动source image 运动。first-order 和 之前的monkey-net 都是可以驱动任意类型的运动,不需要先验地知道目标的一些信息,比如骨架等。能够通过自监督的方式学习到图像中的关键点。下图中是人脸、全身运动,动画运动的驱动效果。可以看出,first-order 的效果还是很不错的,且该方法基于运动模型推导而出,在形式上也具有良好的可解释性。

基本框架
first-order 的算法框架如下图所示,主要包括三个部分的网络,keyporint detector 检测图像中的关键点,以及每个关键点对应的jaccobian矩阵;dense motion network 基于前面的结果生成最终的transform map 以及occulation map;使用transform map 和 occulation map 对编码后的source feature 做变换和mask处理,再decoder 生成出最终的结果。
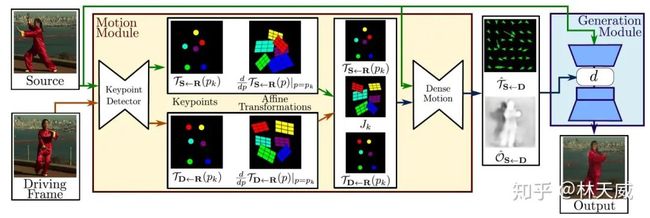
具体方法
问题定义
image animation 任务的目标是基于driving frame
![]()
去驱动一张 source image (这里需要两者包含相似的物体)。我们需要一个迁移函数来映射 到 的变换, 来记录坐标变换(可以看作是一种flow)。
步骤1: keypoint estimator
为了获得$$
![]()
, 作者提出引入一个抽象的参考帧$R$,使网络能够独立同时估计 以及 。那么问题就是如何在不显式表示参考帧的情况下,由后两者获得 。可以进行一个简单的推导:

这里先直接给出最终的推导结果:
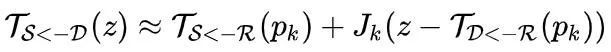
此处,
![]()
是 参考帧 上的关键点位置,而 则是该关键点在 上的对应位置。此处 是 该关键点对应的jaccobian矩阵:

上述的映射形式的优点很明显,它对于
![]()
和 是采用同样的方式进行处理的,有助于提高效率。
因此,第一步,对于k个关键点中的每个关键点,网络获得了一组仿射变换的参数,
![]()
可以看作 中的b, 可以看作 。那么下一步的问题就在于,如何将这k个仿射变换结合为我们所需要的dense optical map。
步骤2: motion estimator
这一步的目的是将上一步获得的k 个仿射变换结合为一个dense optical flow

,并生成一张occlusion map 来评估图中每个点的置信度,用来指导最后一步图片重建时网络需要inpainting 哪些地方。
这一步采用了一个motion estimator 网络,其输入包括两个部分:
-
heatmap 形式的 driving kp 和 source kp
-
用k个仿射变换参数,分别对原图做仿射变换,并将结果concat在一起(这里实际上是用了(kp+1)组参数,额外的一组是identity的,可以看作是背景类吧)
将以上结果输入到网络里面后,输出两者:
-
基于softmax激活输出 k+1 channel的mask,表明每个位置上应当选取哪个仿射变换的参数
-
基于sigmoid激活的单通道occlusion map
基于mask进行加权,我们就可以获得一个两通道的dense optical flow
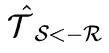
。
步骤3: image generation
激动人心的最后一步,encoder 将  进行特征编码,得到中间特征。采用上一步得到的dense optical flow 对中间特征进行warp,并乘上occlusion map,得到变换后的中间特征,最终通过一个decoder 重建出图像。通过看训练中间结果,可以看出实际上中间warp后的结果距离理想的效果相差是很远的,所以最后一步的decoder很重要,起到了一个重建以及inpainting的作用。看到有人在讨论中提到文章中对于inpainting介绍很少,因为实际上first-order里面并没有告诉网络去做inpainting,inpainting 这个功能实际上是图片重建/GAN loss 的梯度指导网络去学习的。
进行特征编码,得到中间特征。采用上一步得到的dense optical flow 对中间特征进行warp,并乘上occlusion map,得到变换后的中间特征,最终通过一个decoder 重建出图像。通过看训练中间结果,可以看出实际上中间warp后的结果距离理想的效果相差是很远的,所以最后一步的decoder很重要,起到了一个重建以及inpainting的作用。看到有人在讨论中提到文章中对于inpainting介绍很少,因为实际上first-order里面并没有告诉网络去做inpainting,inpainting 这个功能实际上是图片重建/GAN loss 的梯度指导网络去学习的。
训练
first-order 中间的若干步骤,比如关键点估计都是没有直接监督的,监督的是最终输出的结果。first-order 的损失函数包括几个部分
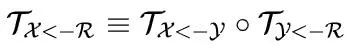
重建损失
first-order采用视频序列进行自监督训练的,source 和driving 是同一个视频中的随机两帧,所以重建loss就是约束生成图像和真实图像的vgg19特征之间的L1距离。类似于style transfer 中用作content loss的 perceptual loss。
GAN loss
虽然论文中没提,但在代码实现中作者采用了GAN loss,即添加了一个判别器去判断生成的结果是否真实。
Equivariance Constraint
这是对于无监督关键点估计非常重要的一种一致性约束,主要的目的是增加关键点估计的稳定性。基本的思路为原图和扰动后图片上的关键点应该能够对齐。其标准形式可以写为:
![]()
即,扰动后图片的关键点,做反向扰动后应该与原始图片的关键点相同。在本文中,作者具体采用了tps 作为这里的扰动方式。
实验部分
abalation study

实验部分主要看一下几个ablation study。这里 Pyr 指的是pyramid 的 content loss;第四行是指添加了occulsuion map;第五行是尝试去掉了equivariance constraint。
可以看出:
-
equivariance constraint 如果去除的话,关键点会变的很飞;
-
occlusion 对图片质量的提升是比较显著的,因为能够识别出需要修改的位置;
-
最后一行full 为 第四行加上前面的运动迁移的一套东西,可以看出质量提高了很多。
但也可以看出存在的一些问题:
-
比较显著的就是网络对于前后关系搞不清楚,前后脚经常是错误的
-
重叠的四肢建模效果很不理想
SOTA comparison
下面三行分别是 x2face、monkey-net 和 first-order。可以看出效果比前面两个好了很多,但是距离理想显然还有比较大的距离。

讨论
-
由于是自监督,且网络中的机制能比较好的handle 背景,所以在背景稳定的情况下完全不需要扣除背景,因为扣除背景这一步本身也引入了不少的噪声。
-
first-order这类方法存在的一个问题是,将3d空间中的物体运动简化为2d平面上的运动进行处理了,这导致很多复杂的pose、遮挡等情况网络是没法handle的。
-
另外,first-order 这篇论文的代码实现的很好,阅读代码能够有效地帮助理解论文。
改进点讨论
-
Generation Module
-
Encoder 可以替换为StyleGANEncoder
-
Decoder 可以替换为StyleGANENcoder
-
Decoder 在本质上可以看作一个inpainting 网络,该模块的输入其实是一个warp 的很差的中间结果,最终的结果其实非常非常依赖于decoder的效果。因此这里可以引入inpainting 的一些策略或网络结果来做,比如attention 之类的,对最终重建结果应该是会有比较明显的帮助的。
-
-
多帧source
-
比较直接的思路,分别对多帧S 和 D 计算迁移,然后在generation module 的中间部分对多帧结果进行融合,比如concat之类的;
-
-
改进transofrm形式
-
将基于点的affine 改为基于边的affine。
-
作者:林天威
|关于深延科技|
深延科技成立于2018年1月,中关村高新技术企业,是拥有全球领先人工智能技术的企业AI服务专家。以计算机视觉、自然语言处理和数据挖掘核心技术为基础,公司推出四款平台产品——深延智能数据标注平台、深延AI开发平台、深延自动化机器学习平台、深延AI开放平台,为企业提供数据处理、模型构建和训练、隐私计算、行业算法和解决方案等一站式AI平台服务。