YOLOV1论文详解
YOLOV1
1. Introduction

YOLO非常简单:对于一张完整的图像,通过一个单一的卷积网络可以同时预测多个bounding boxes的回归参数和这些boxes的类别概率,并直接优化检测性能。这种统一的模式相对于传统的目标检测有以下几个好处:
- 检测特别快。
- 与滑动窗口和基于
region proposal的技术不同,YOLO在训练和测试期间可以看到整个图像,因此它能隐式地编码类别以及它们的外观的上下文信息 - YOLO学习地是目标的通用表示法,具有高度的通用性
但是,在准确性上,YOLO仍然落后于最先进的探测系统。虽然它可以快速识别图像中的物体,但它很难精确定位某些物体,特别是小的物体。
2. Unified Detection

我们的网络将输入图像划分为 S × S S \times S S×S的网格,如果一个目标的中心落在这个网格中,那么这个网格就负责检测该目标
每个网格预测 B B B个bounding boxes和这些boxes的置信度。这些置信度反映模型对boxes包含目标的自信程度,以及它认为boxes预测准确的准确度。从形式上来说,我们将置信度定义为: P r ( O b j e c t ) ∗ I O U p r e d t r u t h Pr(Object)*IOU_{pred}^{truth} Pr(Object)∗IOUpredtruth。
每个bounding box不仅要预测 x , y , w , h x,y,w,h x,y,w,h和confidence共5个值
- x , y x,y x,y:表示预测
box的中心相对于网格单元的边界 - w , h w,h w,h:表示预测的宽度和高度相对于整个图像
confidence:置信度
还要 C C C个预测类别概率, P r ( C l a s s i ∣ O b j e c t ) Pr(Class_i|Object) Pr(Classi∣Object)。这些概率取决于包含目标的网格单元。对于每个网格单元,我们仅会预测一个类别概率,与box的数目无关。
总结: 每个输入图像被划分为 S × S S \times S S×S个网格单元,每个网格单元预测 B B B个bounding box,每个bounding box包含5个值: x , y , w , h x,y,w,h x,y,w,h和confidence,另外每个单元格要预测 C C C个类别概率,因此每个输入图像经过YOLO会被编码为一个 S × S × ( B ∗ 5 + C ) S \times S \times (B*5+C) S×S×(B∗5+C)的tensor
为了在PASCAL VOC测试YOLO,我们设置 S = 7 , B = 2 S=7,B=2 S=7,B=2。PASCAL VOC有20个类别,所以 C = 20 C=20 C=20。因此我们的最终输出为一个 7 × 7 × 30 7 \times 7 \times 30 7×7×30的tensor
2.1 Network Design

网络的初始卷积层从图像中提取特征,而全连接层预测输出概率和坐标信息
2.2 Training
我们首先在ImageNet训练集进行预训练,对于预训练,我们使用上图中前20个卷积层,然后是一个平均池化和一个完全连接层。
然后我们将模型转为去进行目标检测,我们在预先训练好的网络基础上添加了4个卷积层和2个全连接层,并将网络的输入分辨率从224x224提高到448x448
我们网络的最后一层预测了类别概率和bounding box坐标信息。我们通过图像的高度和宽度将bounding box的高度和宽度进行归一化,使其在0和1之间;bounding box的中心是相对于某一个网格单元的offset,其值也在0和1之间
我们使用leaky-ReLU作为激活函数
由于均方误差容易优化,故我们使用均方误差来优化我们的模型,但存在者一些问题:
- 它赋予同样的权重对于定位误差和分类误差,这是不合理的
- 在每个图像中,许多网格单元不包含任何目标,这使得这些网格单元的置信度趋向0,这会超过那些包含目标的网格单元的梯度
- 这些会导致模型不稳定,导致训练早期发散
我们通过数 λ c o o r d , λ n o o b j \lambda_{coord},\lambda_{noobj} λcoord,λnoobj这两个参为了解决上述问题,我们增加权重在bounding box坐标预测损失,减少权重在不包含目标的网格单元的置信度损失。我们设置 λ c o o r d = 5 , λ n o o b j = 0.5 \lambda_{coord}=5,\lambda_{noobj}=0.5 λcoord=5,λnoobj=0.5
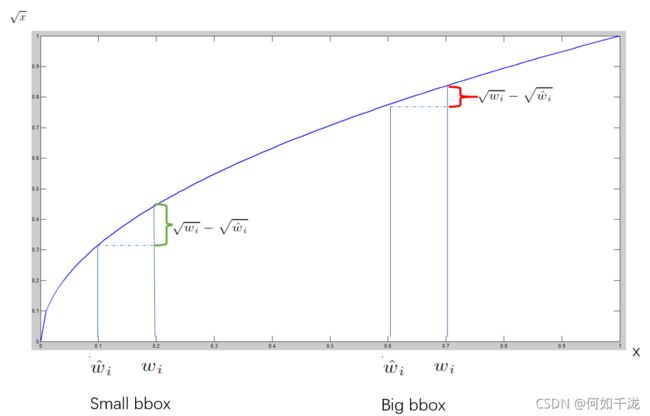
对不同大小的box预测中,相比于大box预测偏一点,小box预测偏一点是更不能被忍受的。而均方误差中对不同大小box同样的偏移loss是一样。 为了缓和这个问题,我们将box的宽高取平方根代替原本的宽高。如下图:
每一个网格单元会预测多个box,希望的是每个·box predictor·专门负责预测某个目标。具体做法就是看当前预测的box与ground truth box中哪个IoU大,就负责哪个。
在训练期间,我们会优化如下这个损失函数:
