YOLOV2论文详解
本文主要介绍了YOLOV2的
Better和Faster部分
1. Better
YOLOV1存在如下两个缺点:
- 定位误差大
- 与基于
region proposal的方法相比,召回率低
因此,我们集中提高定位准确性和召回率,同时保证分类的准确性
1.1 Batch Normalization
BN可以显著改善模型的收敛性,通过在每个卷积层的后面增加BN层,模型提高了**2%**的mAP。通过BN,我们可以在保证模型不会过拟合的情况下,丢弃dropout层
1.2 High Resolution Classifier
所有先进的检测算法都会在ImageNet预先训练好分类器,原来的YOLOV1在进行预训练时使用的是224x224的输入,然后再检测时将输入的分辨率调448x448,这意味着模型还要适应图像分辨率的改变。而对于YOLOV2,我们会在检测之前在ImageNet以分辨率为448x448训练10个epoch,这使得模型有时间再更高的分辨率输入的情况去调整参数,实验表明这样可以提高4%的mAP
1.3 Convolutional With Anchor Boxes
原来的YOLOV1直接利用全连接层来预测bounding box的坐标信息,而YOLOV2采用了Faster R-CNN的方法,引入了anchor。我们将原来网络的全连接层和最后一个pooling层去掉,使得最后的卷积层能输出更高分辨率的特征图。我们还缩减了网络,用416x416分辨率大小作为输入,而不是448x448。这样做的原因是希望得到的特征图有着奇数的宽和高,这样特征图的中心就只有一个,因为大的目标一般会占据图像的中心,所以最好在中心有一个单一的位置来预测这些目标。
网络会经过32倍下采样,最后输入13x13大小的特征图
使用anchor,模型的mAP值从69.5降到了69.2,下降了一丢丢,而召回率却从81%提高到了88%
1.4 Dimension Clusters
我们发现anchor的大小和比例都是手工按经验挑选的,然后网络会去调整这些anchor,如果我们最初就能选择合适大小的anchor,这样网络就更容易去学会预测。
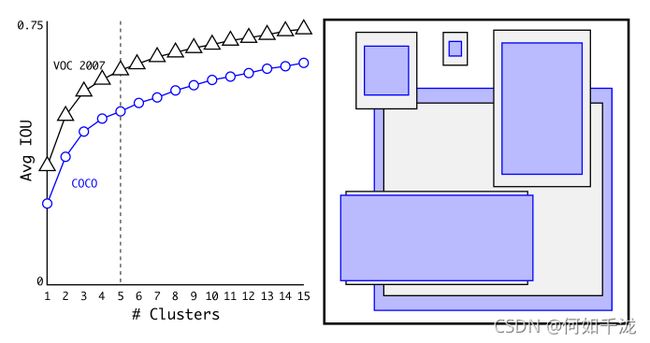
我们采用K-means对训练集的boxes进行聚类,寻找合适的anchor。但是如果我们采用欧式距离来度量,这会导致尺寸大的box其误差也会更大**,然而我们真正想要的是与box大小无关,因此我们重新定义距离度量:
d ( b o x , c e n t r o i d ) = 1 − I O U ( b o x , c e n t o r i d ) d(box, centroid)=1-IOU(box, centorid) d(box,centroid)=1−IOU(box,centorid)
聚类结果显示大多数box都是高瘦,而矮胖的box较少。我们平衡了模型的复杂度和召回率,选择了 k = 5 k=5 k=5
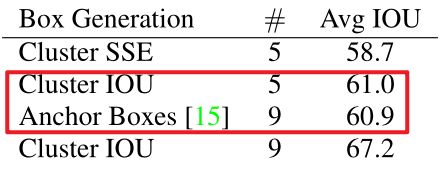
上表表示我们选择的5种anchor与Faster R-CNN的9种anchor效果差不多
1.5 Direct location prediction
引入anchor的第二个问题:模型不稳定,特别是在早期训练时。大部分的不稳定性来自于预测box的 ( x , y ) (x,y) (x,y)值。预测时计算公式如下:
x = ( t x ∗ w a ) + x a y = ( t y ∗ h a ) + y a x=(t_x * w_a)+x_a \\ y=(t_y*h_a)+y_a x=(tx∗wa)+xay=(ty∗ha)+ya
这里是按照Faster R-CNN里面的公式写的,与原文不一样
比如当 t x = { 1 , − 1 } t_x=\{1,-1\} tx={1,−1},预测box的横坐标可以出现在图像的任意位置,但我们更希望每个anchor仅能预测附近的GT box,因为其他位置的GT box也应该由其附近的anchor来预测而不是远离当前GT box的anchor来预测
我们采用了原来YOLOV1的方法预测相对于grid cell的坐标位置,而不是直接预测offset偏移量
网络在输出特征图的每个网格单元预测5个bounding box,对于每个bounding box预测5个坐标: t x , t y , t w , t h , t o t_x, t_y, t_w, t_h, t_o tx,ty,tw,th,to。如果这个网格单元相对于图像的左上角的偏移量为 c x , c y c_x, c_y cx,cy并且anchor的宽高为 p w , p h p_w,p_h pw,ph,那么预测对应于:
b x = σ ( t x ) + c x b y = σ ( t y ) + c y b w = p w e t w b h = p h e t h P r ( o b j e c t ) ∗ I O U ( b , o b j e c t ) = σ ( t o ) b_x = \sigma(t_x) + c_x \\ b_y = \sigma(t_y) +c_y \\ b_w = p_we^{t_w} \\ b_h = p_he^{t_h} \\ Pr(object)*IOU(b, object)=\sigma(t_o) bx=σ(tx)+cxby=σ(ty)+cybw=pwetwbh=phethPr(object)∗IOU(b,object)=σ(to)
1.6 Fine-Grained Features
这里主要是添加了一个层:passthrough layer。这个层的作用就是将前面一层的26*26的feature map和本层的13*13的feature map进行连接,有点像ResNet。这样做的原因在于虽然13*13的feature map对于预测大的object以及足够了,但是对于预测小的object就不一定有效。也容易理解,越小的object,经过层层卷积和pooling,可能到最后都不见了,所以通过合并前一层的size大一点的feature map,可以有效检测小的object
1.7 Multi-Scale Training
由于我们的模型只有卷积和池化,我们可以动态的调整输入图像的大小,于是我们引入了多尺度训练,我们每隔10次迭代随机选择一个新的图像大小进行输入。由于我们的模型的下采样是32倍,因此我们从 { 320 , 352 , . . . , 608 } \{320,352, ..., 608\} {320,352,...,608}去选择。
这种方式会强迫模型学会在各种输入维度上做出准确的预测,网络在小尺寸运行较快,所以YOLOV2在速度和准确性做了个简单的权衡

2. Faster
2.1 Darknet-19
这个网络在ImageNet上取得了top-5的91.2%的准确率

2.2 Training for classification
我们首先在ImageNet数据集上训练160个epochs,其中在训练期间使用的数据增强方式有:随机裁剪、旋转以及色度,饱和度和对比度的调整。
然后我们在对网络初步训练后,微调了我们的网络,采用了448x448作为输入,训练10个epochs
2.3 Training for detection
将网络转换为进行检测,我们删除最后一个卷积层,然后添加3个3x3的卷积层,每个卷积层有1024个filter,而且每个后面跟着一个1x1卷积层,其filter的个数由需要检测的类别数来确定
参考:
- https://www.codetd.com/article/13131414
- https://blog.csdn.net/u014380165/article/details/77961414