图像超分辨率:任意尺度超分: Learning A Single Network for Scale-Arbitrary Super-Resolution(2021)
文章目录
- Learning A Single Network for Scale-Arbitrary Super-Resolution
-
- 1 与Meta-SR 比较
- 2 整体结构
-
- 2.1 scale-aware feature adaption
- 2.2 scale-aware unsampling layer
- 3 实验结果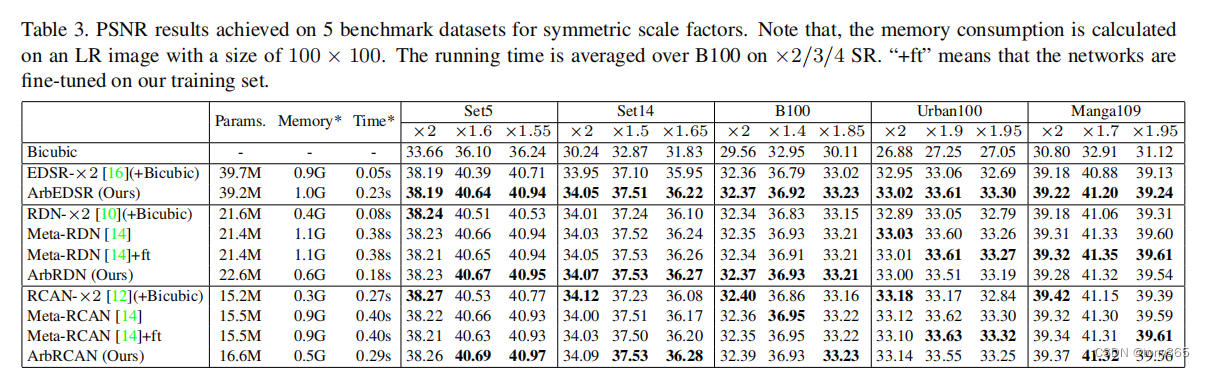
Learning A Single Network for Scale-Arbitrary Super-Resolution
本文通过两个模块来实现 scale-arbitrary sr
分别是 scale-aware feature adaption block和scale-aware unsampling layer
1 与Meta-SR 比较
meta-sr 也是任意尺寸超分,但是
- meta-sr 的scale信息只是用于上采样滤波,没有用到特征提取模块里面
- meta-sr 是height, width同样的缩放,而本文可以 对 height ,width不同的缩放尺寸(meta-sr调整后也可以)
关于1 为什么scale信息需要添加到特征提取模块,作者进行了实验:
edsr x2, x3, x4的网络,输入相同图像,
计算feature map的相似度。如果不是完全相似,就证明了不同的缩放尺度会影响特征提取,因此缩放尺度信息需要输入到 特征提取模块。

2 整体结构
注意其中两个模块:scale-aware feature adaption block和scale-aware unsampling layer
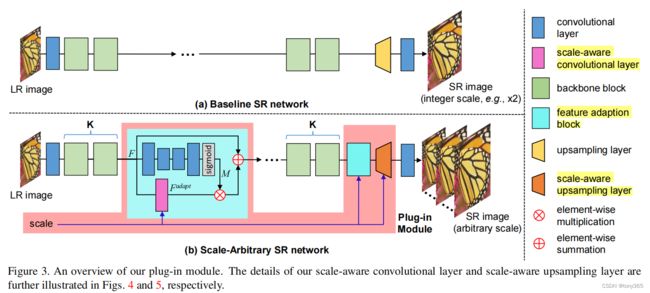
主要包括
2 个 {K个backbone 模块 + 1个 sa-adapt} 特征提取
加上
1个 sa_unsampling
def forward(self, x):
# head
x = self.sub_mean(x)
x = self.head(x)
# body
res = x
for i in range(self.n_resgroups):
res = self.body[i](res)
# scale-aware feature adaption
if (i+1) % self.K == 0:
res = self.sa_adapt[i](res, self.scale, self.scale2)
res = self.body[-1](res)
res += x
# scale-aware upsampling
res = self.sa_upsample(res, self.scale, self.scale2)
# tail
x = self.tail[1](res)
x = self.add_mean(x)
return x
2.1 scale-aware feature adaption

其中紫红色的内部结构为下面的结构,
实际是设计了 4个expert (weight +bias), scale信息通过全连接层,生成weight , 进行加权合成一个expert(weight , bias),再进行卷积
也就是说这个模块的卷积 weight,bias 是可以通过 scale调节的。
输出再与上图的M相乘后 与 F相加, M是4层卷积后的单通道guide map. 其实相当于 图像特征信息 和 scale特征信息相融合,再融合。
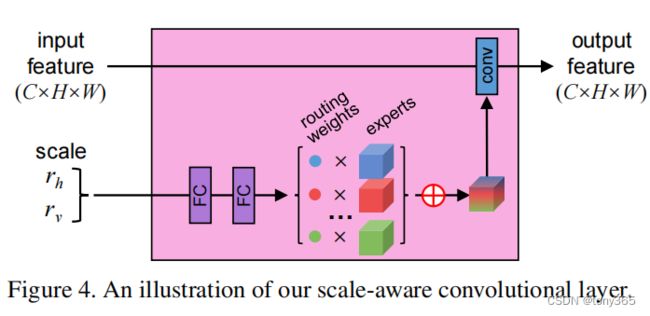
class SA_adapt(nn.Module):
def __init__(self, channels):
super(SA_adapt, self).__init__()
self.mask = nn.Sequential(
nn.Conv2d(channels, 16, 3, 1, 1),
nn.BatchNorm2d(16),
nn.ReLU(True),
nn.AvgPool2d(2),
nn.Conv2d(16, 16, 3, 1, 1),
nn.BatchNorm2d(16),
nn.ReLU(True),
nn.Conv2d(16, 16, 3, 1, 1),
nn.BatchNorm2d(16),
nn.ReLU(True),
nn.Upsample(scale_factor=2, mode='bilinear', align_corners=False),
nn.Conv2d(16, 1, 3, 1, 1),
nn.BatchNorm2d(1),
nn.Sigmoid()
)
self.adapt = SA_conv(channels, channels, 3, 1, 1)
def forward(self, x, scale, scale2):
mask = self.mask(x)
adapted = self.adapt(x, scale, scale2)
return x + adapted * mask
class SA_conv(nn.Module):
def __init__(self, channels_in, channels_out, kernel_size=3, stride=1, padding=1, bias=False, num_experts=4):
super(SA_conv, self).__init__()
self.channels_out = channels_out
self.channels_in = channels_in
self.kernel_size = kernel_size
self.stride = stride
self.padding = padding
self.num_experts = num_experts
self.bias = bias
# FC layers to generate routing weights
self.routing = nn.Sequential(
nn.Linear(2, 64),
nn.ReLU(True),
nn.Linear(64, num_experts),
nn.Softmax(1)
)
# initialize experts
weight_pool = []
for i in range(num_experts):
weight_pool.append(nn.Parameter(torch.Tensor(channels_out, channels_in, kernel_size, kernel_size)))
nn.init.kaiming_uniform_(weight_pool[i], a=math.sqrt(5))
self.weight_pool = nn.Parameter(torch.stack(weight_pool, 0))
if bias:
self.bias_pool = nn.Parameter(torch.Tensor(num_experts, channels_out))
fan_in, _ = nn.init._calculate_fan_in_and_fan_out(self.weight_pool)
bound = 1 / math.sqrt(fan_in)
nn.init.uniform_(self.bias_pool, -bound, bound)
def forward(self, x, scale, scale2):
# generate routing weights
scale = torch.ones(1, 1).to(x.device) / scale
scale2 = torch.ones(1, 1).to(x.device) / scale2
routing_weights = self.routing(torch.cat((scale, scale2), 1)).view(self.num_experts, 1, 1)
# fuse experts
fused_weight = (self.weight_pool.view(self.num_experts, -1, 1) * routing_weights).sum(0)
fused_weight = fused_weight.view(-1, self.channels_in, self.kernel_size, self.kernel_size)
if self.bias:
fused_bias = torch.mm(routing_weights, self.bias_pool).view(-1)
else:
fused_bias = None
# convolution
out = F.conv2d(x, fused_weight, fused_bias, stride=self.stride, padding=self.padding)
# 和卷积之后再按通道乘上系数 是否一样。
return out
2.2 scale-aware unsampling layer
- 求出每个HR像素再 LR 中的位置偏移量

## coordinates in HR space
coor_hr = [torch.arange(0, round(h * scale), 1).unsqueeze(0).float().to(x.device),
torch.arange(0, round(w * scale2), 1).unsqueeze(0).float().to(x.device)]
## coordinates in LR space
coor_h = ((coor_hr[0] + 0.5) / scale) - (torch.floor((coor_hr[0] + 0.5) / scale + 1e-3)) - 0.5
coor_h = coor_h.permute(1, 0)
coor_w = ((coor_hr[1] + 0.5) / scale2) - (torch.floor((coor_hr[1] + 0.5) / scale2 + 1e-3)) - 0.5
input = torch.cat((
torch.ones_like(coor_h).expand([-1, round(scale2 * w)]).unsqueeze(0) / scale2,
torch.ones_like(coor_h).expand([-1, round(scale2 * w)]).unsqueeze(0) / scale,
coor_h.expand([-1, round(scale2 * w)]).unsqueeze(0),
coor_w.expand([round(scale * h), -1]).unsqueeze(0)
), 0).unsqueeze(0)
- 预测filters 和 offset
上面的偏移信息与scale信息一起输入到 全连接网络,每个HR的像素位置,其实是一个 4元素的向量(2 个 scale, 2个 偏移信息)
输出是 2个expert(weight + bias) 和 2 个offset 信息

# (2) predict filters and offsets
# two FC layers
self.body = nn.Sequential(
nn.Conv2d(4, 64, 1, 1, 0, bias=True),
nn.ReLU(True),
nn.Conv2d(64, 64, 1, 1, 0, bias=True),
nn.ReLU(True),
)
embedding = self.body(input)
## offsets
offset = self.offset(embedding)
## filters
routing_weights = self.routing(embedding)
routing_weights = routing_weights.view(self.num_experts, round(scale*h) * round(scale2*w)).transpose(0, 1) # (h*w) * n
weight_compress = self.weight_compress.view(self.num_experts, -1)
weight_compress = torch.matmul(routing_weights, weight_compress)
weight_compress = weight_compress.view(1, round(scale*h), round(scale2*w), self.channels//8, self.channels)
weight_expand = self.weight_expand.view(self.num_experts, -1)
weight_expand = torch.matmul(routing_weights, weight_expand)
weight_expand = weight_expand.view(1, round(scale*h), round(scale2*w), self.channels, self.channels//8)
- sample 和 interpolate
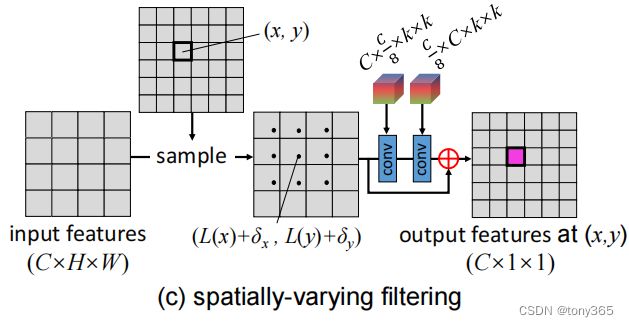
offset是每个位置的 x,y方向偏移信息,与meshgrid 相加后得到 HR映射到LR的信息,然后在 通过学习到的filter(就是两个expert) 加权得到 HR pixel value.
第一步是 计算 HR映射到的LR的中心位置,然后计算warp后的图像(类似光流)
第二步是 HR 的每个像素都有一个filter, 作用于warp后的图像,每个像素的filter得到了HR该位置的pixel value.
# (3) grid sample & spatially varying filtering
## grid sample
fea0 = grid_sample(x, offset, scale, scale2) ## b * h * w * c * 1
fea = fea0.unsqueeze(-1).permute(0, 2, 3, 1, 4) ## b * h * w * c * 1
## spatially varying filtering
out = torch.matmul(weight_compress.expand([b, -1, -1, -1, -1]), fea)
out = torch.matmul(weight_expand.expand([b, -1, -1, -1, -1]), out).squeeze(-1)
return out.permute(0, 3, 1, 2) + fea0
3 实验结果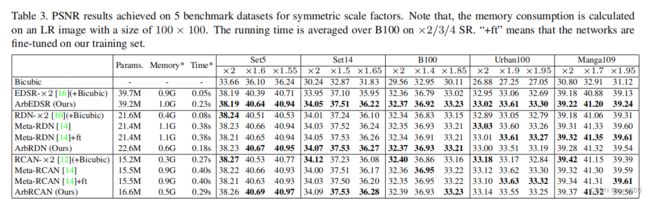
可以在作者提供的网站上做实验: demo