从零开始的线性回归的代码实现
(注:我们将从零开始实现整个方法,包括流水线,模型,损失函数和小批量随机梯度下降优化器)
一:需要的包,并载入
random(juterbook好像是自带了) torch d2l 可通过镜像下载,快得多
1.打开Anaconda:

2.打开其中内置的cmd

3.输入以下命令(这里的命令我下载的是torch的CUDA 11.3版本,如果想要下载其他版本,可访问pytorch官网,附官网地址:PyTorch)
通过输入以下指令,先转到清华源:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --set show_channel_urls yes
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
像下面这样挨个输入加回车即可
![]()
输入完四条指令后
(1)开始下载torch:
输入指令
conda install pytorch torchvision torchaudio cudatoolkit=11.3
如图:
![]()
有y/n 选项,则输入y,再按回车即可
然后等待其下载结束
(2)下载d2l
输入以下指令: pip install d2l
![]()
等待其下载结束
4.载入包

二:自行构造一个数据集
为了简单起见,我们将根据带有噪声的线性模型构造一个人造数据集。 我们的任务是使用这个有限样本的数据集来恢复这个模型的参数。 我们将使用低维数据,这样可以很容易地将其可视化。 在下面的代码中,我们生成一个包含1000个样本的数据集, 每个样本包含从标准正态分布中采样的2个特征。 我们的合成数据集是一个矩阵X∈R^(1000×2)X∈R^(1000×2)。
我们使用线性模型参数w=[2,−3.4]^⊤、b=4.2 和噪声项ϵ生成数据集及其标签:
y=Xw+b+ϵ.
你可以将ϵ视为模型预测和标签时的潜在观测误差。 在这里我们认为标准假设成立,即ϵ服从均值为0的正态分布。 为了简化问题,我们将标准差设为0.01。 下面的代码生成合成数据集。
def synthetic_data(w, b, num_examples): #@save
"""生成y=Xw+b+噪声"""
X = torch.normal(0, 1, (num_examples, len(w))) #括号里的意思是有n个样本,其列数是w的长度,1代表的是标准差
y = torch.matmul(X, w) + b #加b用到了广播计算,所以得到的y是一个列向量
y += torch.normal(0, 0.01, y.shape) #均值为0,方差为0.01,形状和y的形状一样的一个噪音
return X, y.reshape((-1, 1)) #把X和y矩阵,变换为一个列向量返回,-1表示未指定
true_w = torch.tensor([2, -3.4]) #定义我们的真实的w
true_b = 4.2 #定义我们的真实的b
features, labels = synthetic_data(true_w, true_b, 1000) #通过真实的值,来生产我们的特征和标签norml函数:pytorch函数之torch.normal() - 深度学习1 - 博客园 (cnblogs.com)
Python错误笔记(2)之Pytorch的torch.normal()函数_日子就这么过来了的博客-CSDN博客
matmul函数:即mm,令两个矩阵相乘,(43条消息) PyTorch疑难杂症(1)——torch.matmul()函数用法总结_Wendy的博客-CSDN博客_torch.matmul
reshape函数:将矩阵变换为自己想要的维度
feature为特征,label为标签:(43条消息) 机器学习:基本概念-标签、特征、样本、模型、回归与分类_Vuko_Coding Zone-CSDN博客_机器学习 标签
在我们创建的数据集中,features中的每一行都包含一个二维数据样本, labels中的每一行都包含一维标签值(一个标量)
现在来看看我们数据集长什么样子:
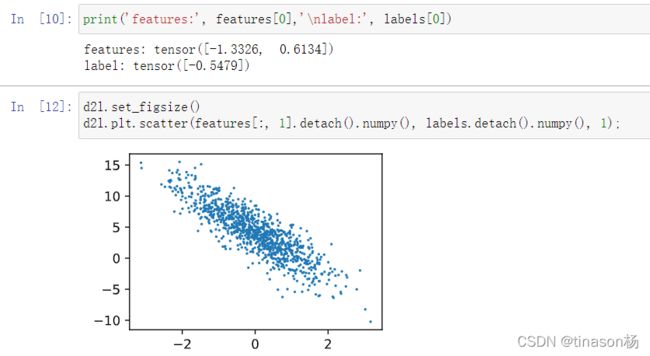
三:定义小批量
回想一下,训练模型时要对数据集进行遍历,每次抽取一小批量样本,并使用它们来更新我们的模型。 由于这个过程是训练机器学习算法的基础,所以有必要定义一个函数, 该函数能打乱数据集中的样本并以小批量方式获取数据。
在下面的代码中,我们定义一个data_iter函数, 该函数接收批量大小、特征矩阵和标签向量作为输入,生成大小为batch_size的小批量。 每个小批量包含一组特征和标签。
1.构造一个可以生成小批量的函数data_iter
def data_iter(batch_size, features, labels): #三个参数:小批量大小、特征、标签
num_examples = len(features) #有n个样本,features是1000*2的矩阵,len()是取其第一维度的长度
indices = list(range(num_examples)) #range是从0到n-1,然后把这些值转化为python中的list
# 这些样本是随机读取的,没有特定的顺序
random.shuffle(indices) #将indices中的值随机打乱
for i in range(0, num_examples, batch_size): #括号里面分别为,开始处,截至处,步长
batch_indices = torch.tensor(
indices[i: min(i + batch_size, num_examples)]) #用一个min,这样在截取时,就不会超出边界num_examples了
yield features[batch_indices], labels[batch_indices] #yield相当于return,返回一个值,并且记住这个值的位置,下次迭代时,就从这个位置开始。features[batch_indices]相当于返回了一个x的值 labels[batch_indices]相当于返回了一个y的值。python中的list:(43条消息) Python列表(list)的基本用法_小白_努力-CSDN博客_pythonlist函数用法
2.选取合适大小的小批量值
batch_size = 10
for X, y in data_iter(batch_size, features, labels):
print(X, '\n', y)
break四:定义初始化模型参数
在我们开始用小批量随机梯度下降优化我们的模型参数之前, 我们需要先有一些参数。 在下面的代码中,我们通过从均值为0、标准差为0.01的正态分布中采样随机数来初始化权重, 并将偏置初始化为0。
w = torch.normal(0, 0.01, size=(2,1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)对于w = torch.normal(0, 0.01, size=(2,1), requires_grad=True) :
因为我们已知输入维度是2,所以,用size(2,1)来保证w是一个长为2的向量。
前两个参数的意思是:随机初始化为均值为0,方差为0.01的正态分布,又因为我们需要计算梯度,故用requires_grad=True来保留梯度特征
对于b = torch.zeros(1, requires_grad=True):
参数只给了一个1,表示此数据为标量,而事实上,偏差确实是一个标量
注意:由于需要使用梯度下降的方法不断更新w和b的值,所以我们才要加上 requires_grad=True,因为是True的话,代表告诉系统,需要它去追踪这个量的变化,并不断更新它
五:定义模型
接下来,我们必须定义模型,将模型的输入和参数同模型的输出关联起来。 回想一下,要计算线性模型的输出, 我们只需计算输入特征X和模型权重w的矩阵通过向量乘法后再加上偏置b。 注意,上面的Xw是一个向量,而b是一个标量。 回想一下广播机制: 当我们用一个向量加一个标量时,标量会被加到向量的每个分量上。
def linreg(X, w, b):
"""线性回归模型"""
return torch.matmul(X, w) + b六:定义损失函数
因为需要计算损失函数的梯度,所以我们应该先定义损失函数。 这里我们使用均方损失函数。 在实现中,我们需要将真实值y的形状转换为和预测值y_hat的形状相同。
def squared_loss(y_hat, y):
"""均方损失"""
return (y_hat - y.reshape(y_hat.shape)) ** 2 / 2 #用y.reshape(y_hat.shape)把y变为和y_hat一样的形状在此时,我们还没有加起来,即公式中的 还没有体现出来,其实在后面体现了,在程序后面使用了sum,即累加求和
还没有体现出来,其实在后面体现了,在程序后面使用了sum,即累加求和
机器学习常用损失函数小结 - 知乎 (zhihu.com)
附:
 (均方损失函数)
(均方损失函数)
七:定义优化算法
这里我们介绍小批量随机梯度下降。
在每一步中,使用从数据集中随机抽取的一个小批量,然后根据参数计算损失的梯度。 接下来,朝着减少损失的方向更新我们的参数。 下面的函数实现小批量随机梯度下降更新。 该函数接受模型参数集合、学习速率和批量大小作为输入。每 一步更新的大小由学习速率lr决定。*/ 因为我们计算的损失是一个批量样本的总和,所以我们用批量大小(batch_size) 来规范化步长,这样步长大小就不会取决于我们对批量大小的选择。/*
def sgd(params, lr, batch_size):
"""小批量随机梯度下降"""
with torch.no_grad(): #不需要梯度,因为这里的梯度存起来了,这里只是读取值,并不需要更新梯度
for param in params:
param -= lr * param.grad / batch_size #求n-1处的下降幅度,并进行均值
param.grad.zero_() #因为pytorch会自动累计梯度,所以需要手动清零梯度,防止上一次计算的梯度累计到下一次八:训练
lr = 0.03 #超参数,自行设置的学习率
num_epochs = 3 #迭代次数,即梯度下降的次数
net = linreg #之前定义了linreg函数,这里给它起了另外一个别名,方便当我们想更换其他模型时,只用更改此处即可
loss = squared_loss #同上
for epoch in range(num_epochs): #循环三次
for X, y in data_iter(batch_size, features, labels): #从X,y的数据集中开始循环
l = loss(net(X, w, b), y) # X和y的小批量损失,net函数是求预测值
# 因为l形状是(batch_size,1),而不是一个标量。l中的所有元素被加到一起,
# 并以此计算关于[w,b]的梯度
l.sum().backward() #对l用sum求和,求和之后再用backward计算梯度
sgd([w, b], lr, batch_size) # 使用参数的梯度更新参数
with torch.no_grad():
train_l = loss(net(features, w, b), labels)
print(f'epoch {epoch + 1}, loss {float(train_l.mean()):f}')因为我们使用的是自己合成的数据集,所以我们知道真正的参数是什么。 因此,我们可以通过比较真实参数和通过训练学到的参数来评估训练的成功程度。 事实上,真实参数和通过训练学到的参数确实非常接近。
print(f'w的估计误差: {true_w - w.reshape(true_w.shape)}')
print(f'b的估计误差: {true_b - b}')结果:
总结:
1.我们学习了深度网络是如何实现和优化的。在这一过程中只使用张量和自动微分,不需要定义层或复杂的优化器。
2.这一节只触及到了表面知识。在下面的部分中,我们将基于刚刚介绍的概念描述其他模型,并学习如何更简洁地实现其他模型。
特别感谢:李沐老师
文中引用内容为他人原创,已表明其出处