NLP 论文领读|合成数据的妙用:低成本构建高质量的大规模平行语料
欢迎来到「澜舟论文领读」专栏!快乐研究,当然从研读 paper 开始——澜舟科技团队注重欢乐的前沿技术探索,希望通过全新专栏和大家共同探索人工智能奥秘、交流 NLP「黑科技」,踩在「巨人」肩上触碰星辰!
关注「澜舟科技」公众号,加入交流群和大家一起探索 NLP 前沿技术!官方网站:https://langboat.com
本期分享者 :陈圆梦,澜舟科技研究实习生,北京交通大学博士二年级,研究方向为多语言神经机器翻译,邮箱:[email protected]。生活中只有一种英雄主义,那就是在认清生活真相之后依然热爱生活。
写在前面
数据作为目前人工智能的核心之一,其数量和质量对于一个模型最终的性能有着近乎决定性的作用。对机器翻译任务来说,这一点一样成立。但人工构建高质量平行数据是一件成本巨大的事情,且几乎不可能满足目前神经机器翻译对数据量的需求。因此人们退而求其次,尝试通过自动构建平行数据的技术,低成本地构建大规模平行数据。目前常用的方法主要包括数据挖掘技术[1]和数据增强技术[2],其中数据挖掘技术主要通过语义表示相似度(如句向量的余弦距离),从各自的单语语料中挖掘潜在的平行数据;数据增强技术通常使用已有翻译模型对单语语料进行生成,得到合成平行数据。
今天我们要介绍的工作来自于马里兰大学的Eleftheria Briakou和Marine Carpuat发表于 ACL2022 的一篇文章《Can Synthetic Translations Improve Bitext Quality?》,该论文利用合成数据,对挖掘得到的平行数据中不完全对齐的数据进行替换,从而得到高质量的平行语料。
论文链接:https://aclanthology.org/2022.acl-long.326/
一、数据挖掘的噪声问题
正如 Kreutzer 等人 [3] 所发现的,近期发布的通过数据挖掘得到的语料库中存在大量错误翻译的数据。以最近较为常用的多语言翻译语料库 WikiMatrix[4] 为例,该论文对希腊语到英语进行随机抽样人工评估,在抽样的100对正向和反向样本中,发现约12%的样本存在较大语义差异,仅在主题或结构等方面具有一定的相似性,而存在细粒度差异的样本占到 56% 之多。能够完全匹配的平行样本仅占 32%。(需要强调的是,该论文已经预先使用 bicleaner[5] 工具对数据集进行了过滤,去除了明显的噪声数据)。

二、通过翻译合成数据优化大规模平行语料
2.1 合成数据与原始数据语义等价性对比
与原始平行数据相比,使用翻译模型对一端数据进行翻译得到的合成平行数据,在语义等价性上具有明显优势。为了避免引入额外信息,该论文通过原始平行语料库训练翻译,以此进行合成数据的生成。在随机采样人工评估中,有 60%的合成样本在语义等价性上优于原始平行样本。进一步的,该论文使用 divergent-mBERT[6] 对合成样本和原始平行样本的语义等价性得分进行比较,根据差值 d d d 分别进行了统计。
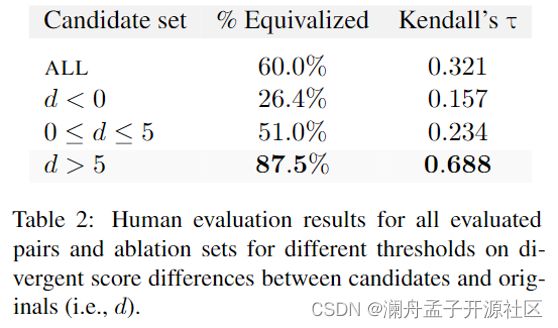
其中,当 d > 5 d > 5 d>5 时,合成样本中有 87.5%在人工评价中优于原始平行样本,并且多人的标注结果具有更高的一致性(依据肯德尔相关系数)。
2.2 数据替换算法
因此该论文在 d > 5 d > 5 d>5 时,将两个方向的合成数据中语义等价性得分最高的一对替换语料库中的原始平行数据,以此获得具有更高语义等价性的双语语料库。完整的算法如下:

其中 D D D 表示原始平行语料, S i S_i Si 和 T i T_i Ti 表示其中的一对源端和目标端数据。 M S → T M_{S→T} MS→T 和 M T → S M_{T→S} MT→S 分别表示正向和反向的翻译模型, T i ^ \hat{T_i} Ti^ 和 S i ^ \hat{S_i} Si^ 分别表示对应翻译模型生成的目标端和源端合成数据。 D ~ \tilde{D} D~ 表示替换后的新语料。此论文通过这样简单的“生成-对比-替换”的流程,对 WikiMatrix 语料库中的希腊语到英语(EL↔EN, with 750,585 pairs)和罗马尼亚语到英语(RO↔EN, with 582,134 pairs)进行了优化。
三、下游任务评测比较
为了证明得到的新语料库具有更高的质量,该论文利用两个下游任务对原始平行语料库和利用合成数据优化的语料库进行对比:这两个任务分别是双语词典归纳(BLI)[7] 和机器翻译(MT)。
3.1 双语词典归纳(BLI)质量对比
BLI 任务旨在归纳一个由两种语言的单词翻译组成的双语词典。该论文使用 Shi 等人 [7] 提出方法进行无监督 BLI,并用 MUSE[8] 进行评估。
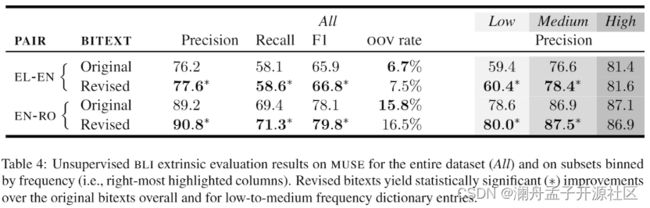
从结果可以看出,使用合成数据替换后的语料库提取得到的词典在准确率、召回率、F1 值均有明显优势,表明新语料库在降低误翻噪声和提高词汇对齐率上有明显的优势。并且在对 MUSE 源端条目的频率进行划分的对比上,新语料库在低频和中频词上表现出明显的优势。
3.2 机器翻译(MT)模型质量对比
MT 任务通过两种方式构建模型:1、使用语料库从头开始训练一个 MT 模型;2、对mT5[9] 模型进行继续训练(continued training)。该论文使用 TED 的官方开发和测试集对 MT 模型进行评估。

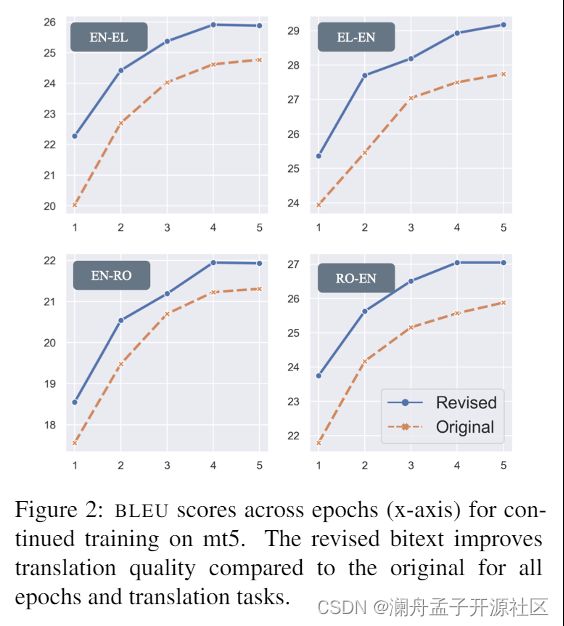
结果表明新语料库构建的 MT 模型在两种语言的四个方向上均具有明显的优势。而相较于从头开始训练,mT5 的继续训练表现出更大的改进。这表明数据中的噪声会明显影响翻译模型的质量,而该论文所提方法能够有效改善这一问题。
在此基础上,该论文为了判断数据生成方式和数据替换标准对语料库质量的影响,在 NMT 任务上进行了消融实验。其中数据生成方法分别对比了仅用正向(FT),反向(BT)合成数据和各自与原始平行数据融合的方法;数据替换标准对比了 Rejuvenation[10](用 NMT 概率分数测量出 10% 最不活跃的数据,使用正向翻译合成数据替换原始平行数据)、Ranking( d > 0 d>0 d>0 )、Thresholding( 基础上要求合成数据的语义等价性得分高于一定阈值)。对比结果如下:
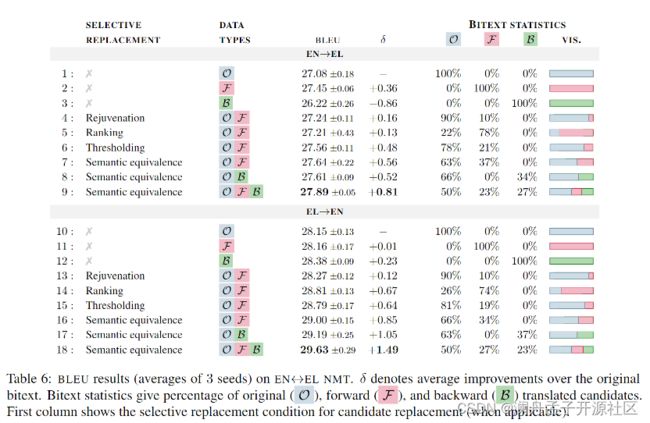
其中 Rejuvenation 表现较差,这表明该方法可能更容易受到 NMT 模型质量的影响,因而在低资源语言上难以有效发挥作用。而使用语义等价性差值替换标准和同时利用双向合成数据毫无意外地取得了最多的 BLEU 值改进。值得注意的是,FT 和 BT 数据在替换的数据量上基本一致,且具有较明显的互补性。
四、合成数据的特点分析与启示
该论文对原始与修改后的 WikiMatrix 希腊语到英语语料库的统计数据进行了对比:
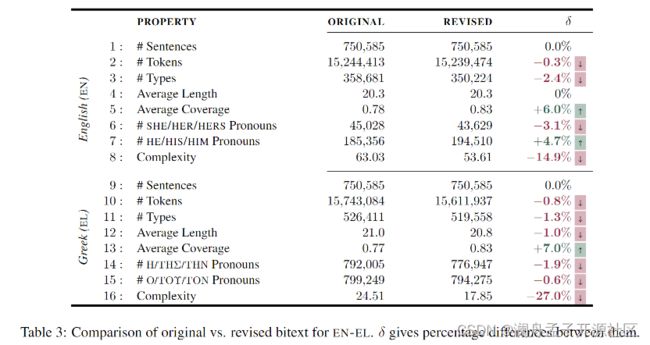
其中值得注意的是,除了先前工作已经发现的复杂度和多样性更低 [11] 之外,生成数据还表现出了较为明显的性别偏见 [12]。除此之外,针对 MT 的消融实验还表明了 FT 和 BT 数据可能在降低数据噪声方面存在一定的互补性,这一发现一方面或许能够解释 FT 和 BT 对翻译模型相互独立的增强能力,同时也暗示从两个方向使用合成翻译可能有益于其他场景,例如知识蒸馏。
最近针对数据分析的工作越来越多,帮助更多的研究者认识到在构建机器学习模型过程中数据的特点和处理方法。该论文相较于先前工作关注的合成数据的特点 [11,13] 和利用合成数据进行增强 [14,15] 的方法,从降低原始语料噪声的角度对合成数据的作用进行了分析和解释,丰富了我们对双语平行数据集构建和利用方面的理解。这些工作从不同角度分析解释了合成数据能在众多下游任务中发挥作用的原因,为我们在处理数据集时提供了重要的指导方向。
五、总结
总而言之,该论文探讨了如何使用翻译合成的数据来增强数据挖掘得到的语料库,从而在没有额外的双语数据或监督的情况下,提高原始双语语料库的质量。该论文着重分析了现有基于数据挖掘技术得到的大规模语料库广泛存在的不匹配的情况,并表明通过翻译模型得到的合成数据能够有效缓解这一问题。
参考文献
[1] Schwenk H, Chaudhary V, Sun S, et al. Wikimatrix: Mining 135m parallel sentences in 1620 language pairs from wikipedia[J]. arXiv preprint arXiv:1907.05791, 2019.
[2] Nguyen X P, Joty S, Wu K, et al. Data diversification: A simple strategy for neural machine translation[J]. Advances in Neural Information Processing Systems, 2020, 33: 10018-10029.
[3] Kreutzer J, Caswell I, Wang L, et al. Quality at a glance: An audit of web-crawled multilingual datasets[J]. arXiv preprint arXiv:2103.12028, 2021.
[4] Schwenk H, Chaudhary V, Sun S, et al. WikiMatrix: Mining 135M Parallel Sentences in 1620 Language Pairs from Wikipedia[C]//Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume. 2021: 1351-1361.
[5] Ramírez‐Sánchez G, Zaragoza-Bernabeu J, Bañón M, et al. Bifixer and bicleaner: two open-source tools to clean your parallel data[C]//Proceedings of the 22nd Annual Conference of the European Association for Machine Translation. 2020: 291-298.
[6] Briakou E, Carpuat M. Detecting Fine-Grained Cross-Lingual Semantic Divergences without Supervision by Learning to Rank[C]//Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020: 1563-1580.
[7] Shi H, Zettlemoyer L, Wang S I. Bilingual Lexicon Induction via Unsupervised Bitext Construction and Word Alignment[C]//Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2021: 813-826.
[8] Conneau A, Lample G, Ranzato M A, et al. Word translation without parallel data[J]. arXiv preprint arXiv:1710.04087, 2017.
[9] Xue L, Constant N, Roberts A, et al. mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer[C]//Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2021: 483-498.
[10] Jiao W, Wang X, He S, et al. Data Rejuvenation: Exploiting Inactive Training Examples for Neural Machine Translation[C]//Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020: 2255-2266.
[11] Zhou C, Neubig G, Gu J. Understanding knowledge distillation in non-autoregressive machine translation[J]. arXiv preprint arXiv:1911.02727, 2019.
[12] Stanovsky G, Smith N A, Zettlemoyer L. Evaluating Gender Bias in Machine Translation[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019: 1679-1684.
[13] Xu W, Ma S, Zhang D, et al. How Does Distilled Data Complexity Impact the Quality and Confidence of Non-Autoregressive Machine Translation?[J]. arXiv preprint arXiv:2105.12900, 2021.
[14] Poncelas A , Shterionov D , Way A , et al. Investigating Backtranslation in Neural Machine Translation[J]. 2018.
[15] Nguyen X P, Joty S, Wu K, et al. Data diversification: A simple strategy for neural machine translation[J]. Advances in Neural Information Processing Systems, 2020, 33: 10018-10029.