全网独家遗传算法优化BP神经网络的3种策略
【GA优化BP】全网独家遗传算法优化BP神经网络的3种策略
- 课程简介
-
- 视频课程
- 3种优化策略
-
- (1)初级形态——初始值优化
- (2)进化形态——超参数优化
- (3)究极形态——模型结构优化
- 资料获取
课程简介
目前本账号正式开启了【优化类问题系列教程】,以智能优化算法为牵引,串起大家关心的各类的实际问题,以实践应用为主,轻理论推导,帮助大家解决各类实际问题。这是第三次课程,关于GA优化BP神经网络的内容,下面是课程的大致计划(根据大家需求不断调整),有需求的同学可以持续关注。

视频课程
【GA优化BP不求人】遗传算法优化BP神经网络的3种策略+轻代码教程
或者点击链接跳转至观看:https://www.bilibili.com/video/BV1LS4y1e7xW?share_source=copy_web
3种优化策略
- 初始权重和偏置的优化(初级形态)
- 超参数的优化(进化形态)
- 模型结构的优化(究极形态)
(1)初级形态——初始值优化
①首先初始化变量
%X表示自变量集合
clc;clear;
x=xlsread('数据模板(单输出).xlsx','sheet1');%输入变量
t=xlsread('数据模板(单输出).xlsx','sheet2');%输出变量
inputnum=size(x,1); % 输入层神经元个数
outputnum=size(t,1); % 输出层神经元个数=偏置个数
hiddenLayerSize=2*inputnum+1; % 隐含层神经元个数
w1num=inputnum*hiddenLayerSize; % 输入层到隐层的w个数
w2num=outputnum*hiddenLayerSize;% 隐含层到输出层的w个数
N=w1num+hiddenLayerSize+w2num+outputnum;%自变量的总数
②未优化前直接运行BP
[trainPerformance1,valPerformance1,testPerformance1,y1]=BPFun(x,t,hiddenLayerSize);
这里的BPFun是自己写的BP神经网络函数,输入自变量x,目标t,以及隐含层数量hiddenLayerSize,可直接输出运行误差结果和预测值
function [trainPerformance,valPerformance,testPerformance,y]=BPFun(x,t,hiddenLayerSize)
%% 选择一个训练函数
trainFcn = 'trainscg';
%% 创建拟合网络
net = fitnet(hiddenLayerSize,trainFcn);
%% 选择输入和输出前/后数据处理
net.input.processFcns = {'mapminmax'};
net.output.processFcns = {'mapminmax'};
%% 切分数据集为训练集、验证集、测试集
net.divideFcn = 'divideblock'; % 固定切分
net.divideMode = 'sample'; % 切分每一个样本
net.divideParam.trainRatio = 70/100;
net.divideParam.valRatio = 15/100;
net.divideParam.testRatio = 15/100;
%% 训练网络
[net,tr] = train(net,x,t);
%% 结果输出提示
y = net(x);%预测结果
% % 分别计算训练集、验证机、测试机表现
% 分别计算训练集、验证机、测试机表现
trainTargets = t .* tr.trainMask{1};
valTargets = t .* tr.valMask{1};
testTargets = t .* tr.testMask{1};
% 计算mse均方误差
trainPerformance.mse = perform(net,trainTargets,y);%训练集
valPerformance.mse = perform(net,valTargets,y); %验证集
testPerformance.mse = perform(net,testTargets,y);% 测试集
% 计算mae平均绝对误差
net.performFcn = 'mae';
trainPerformance.mae = perform(net,trainTargets,y);%训练集
valPerformance.mae = perform(net,valTargets,y); %验证集
testPerformance.mae = perform(net,testTargets,y);% 测试集
% 计算sae绝对误差和
net.performFcn = 'sae';
trainPerformance.sae = perform(net,trainTargets,y);%训练集
valPerformance.sae = perform(net,valTargets,y); %验证集
testPerformance.sae = perform(net,testTargets,y);% 测试集
% 计算sse平方和误差
net.performFcn = 'sse';
trainPerformance.sse = perform(net,trainTargets,y);%训练集
valPerformance.sse = perform(net,valTargets,y); %验证集
testPerformance.sse = perform(net,testTargets,y);% 测试集
% 计算crossentropy交叉熵
net.performFcn = 'crossentropy';
trainPerformance.crossentropy = perform(net,trainTargets,y);%训练集
valPerformance.crossentropy = perform(net,valTargets,y); %验证集
testPerformance.crossentropy = perform(net,testTargets,y);% 测试集
% 展示结构图
view(net)
end
③使用我们的实时编辑器,调用GA优化

④最后结果输出
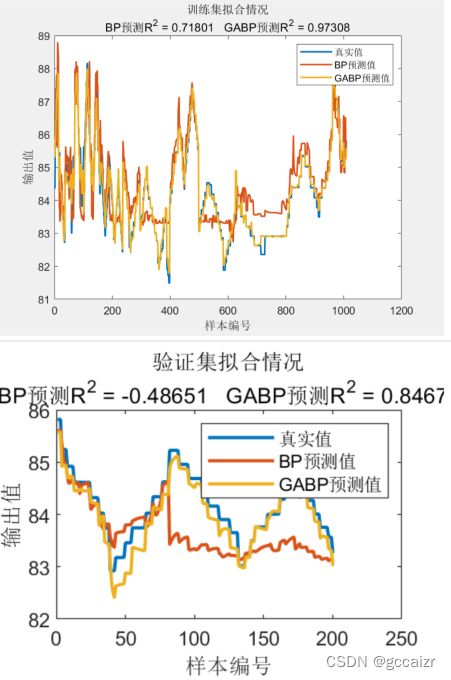
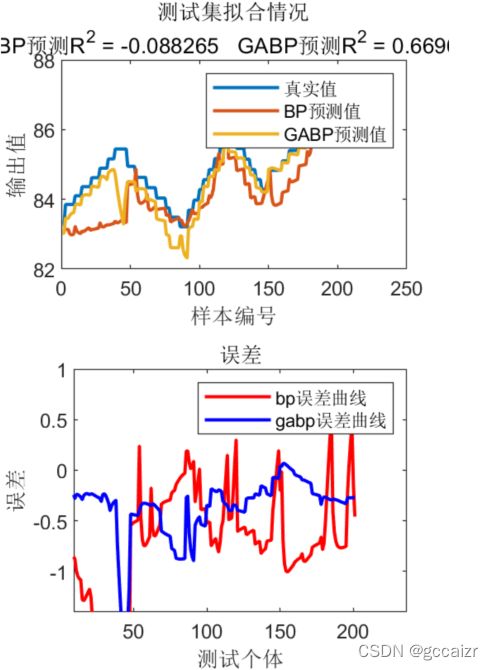

(2)进化形态——超参数优化
①(trainlm )参数
net.trainParam.epochs— 训练的最大 epoch 数。默认值为 1000。
net.trainParam.time— 以秒为单位的最大训练时间。默认值为inf。
net.trainParam.goal— 绩效目标。默认值为 0。
net.trainParam.min_grad— 最小性能梯度。默认值为1e-7。
net.trainParam.mu— 初始mu。默认值为 0.001。
net.trainParam.mu_dec— 的减小因子mu。默认值为 0.1。
net.trainParam.mu_inc— 增加系数mu。默认值为 10。
net.trainParam.mu_max— 的最大值mu。默认值为1e10。
net.trainParam.max_fail— 最大验证失败。默认值为6。
net.trainParam.showWindow— 显示培训 GUI。默认值为 true。
②(trainbr)参数
net.trainParam.epochs— 训练的最大 epoch 数。默认值为 1000。
net.trainParam.goal— 绩效目标。默认值为 0。
net.trainParam.mu— Marquardt 调整参数。默认值为 0.005。
net.trainParam.mu_dec— 的减小因子mu。默认值为 0.1。
net.trainParam.mu_inc— 增加系数mu。默认值为 10。
net.trainParam.mu_max— mu 的最大值。默认值为 1e10。
net.trainParam.max_fail— 最大验证失败。默认值为inf。
net.trainParam.min_grad— 最小性能梯度。默认值为1e-7。
net.trainParam.show— 显示之间的时期(NaN对于无显示)。默认值为 25。
net.trainParam.showCommandLine— 生成命令行输出。默认值为false。
net.trainParam.showWindow— 显示培训 GUI。默认值为 true。
net.trainParam.time— 以秒为单位的最大训练时间。默认值为inf。
③(trainscg)参数
net.trainParam.epochs— 训练的最大 epoch 数。默认值为 1000。
net.trainParam.show— 显示之间的时期(NaN对于无显示)。默认值为 25。
net.trainParam.showCommandLine— 生成命令行输出。默认值为false。
net.trainParam.showWindow— 显示培训 GUI。默认值为 true。
net.trainParam.goal— 绩效目标。默认值为 0。
net.trainParam.time— 以秒为单位的最大训练时间。默认值为inf。
net.trainParam.min_grad— 最小性能梯度。默认值为1e-6。
net.trainParam.max_fail— 最大验证失败。默认值为6。
net.trainParam.mu— Marquardt 调整参数。默认值为 0.005。
net.trainParam.sigma— 确定二阶导数近似的权重变化。默认值为5.0e-5。(超参数)
net.trainParam.lambda— 用于调节 Hessian 不确定性的参数。默认值为5.0e-7。(超参数)
(3)究极形态——模型结构优化
贪心策略:
①建立数学模型来描述问题 。
②把求解的问题分成若干个子问题 。
③对每个子问题求解,得到子问题的局部最优解。
④把子问题的解局部最优解合成原来解问题的一个解。
资料获取
详细过程请参超视频教程设置
关注公众号【橙子数据军团】,后台回复“003”获取本期资料。